







2021-5-19 一些面试题
1.MVCC的实现原理了解吗?
详见博客 https://blog.csdn.net/SnailMann/article/details/94724197
https://www.cnblogs.com/shujiying/p/11347632.html
https://www.cnblogs.com/luchangyou/p/11321607.html
总之,MVCC就是因为大牛们,不满意只让数据库采用悲观锁这样性能不佳的形式去解决读-写冲突问题,而提出的解决方案,所以在数据库中,因为有了MVCC,所以我们可以形成两个组合:
MVCC + 悲观锁 MVCC解决读写冲突,悲观锁解决写写冲突 MVCC + 乐观锁 MVCC解决读写冲突,乐观锁解决写写冲突 这种组合的方式就可以最大程度的提高数据库并发性能,并解决读写冲突,和写写冲突导致的问题
MVCC的实现原理
MVCC的目的就是多版本并发控制,在数据库中的实现,就是为了解决读写冲突,它的实现原理主要是依赖记录中的 3个隐式字段,undo日志 ,Read View 来实现的。
所以我们先来看看这个三个point的概念。

undo日志 undo log主要分为两种:
insert undo log 代表事务在insert新记录时产生的undo log, 只在事务回滚时需要,并且在事务提交后可以被立即丢弃 update undo log 事务在进行update或delete时产生的undo log; 不仅在事务回滚时需要,在快照读时也需要;所以不能随便删除,只有在快速读或事务回滚不涉及该日志时,对应的日志才会被purge线程统一清除
什么是Read View?
什么是Read View,说白了Read View就是事务进行快照读操作的时候生产的读视图(Read View),在该事务执行的快照读的那一刻,会生成数据库系统当前的一个快照,记录并维护系统当前活跃事务的ID(当每个事务开启时,都会被分配一个ID, 这个ID是递增的,所以最新的事务,ID值越大)
总之在RC隔离级别下,是每个快照读都会生成并获取最新的Read View;而在RR隔离级别下,则是同一个事务中的第一个快照读才会创建Read View, 之后的快照读获取的都是同一个Read View。
基本原理
MVCC的实现,通过保存数据在某个时间点的快照来实现的。这意味着一个事务无论运行多长时间,在同一个事务里能够看到数据一致的视图。根据事务开始的时间不同,同时也意味着在同一个时刻不同事务看到的相同表里的数据可能是不同的。
InnoDB存储引擎MVCC的实现策略
在每一行数据中额外保存两个隐藏的列:当前行创建时的版本号和删除时的版本号(可能为空,其实还有一列称为回滚指针,用于事务回滚,不在本文范畴)。这里的版本号并不是实际的时间值,而是系统版本号。每开始新的事务,系统版本号都会自动递增。事务开始时刻的系统版本号会作为事务的版本号,用来和查询每行记录的版本号进行比较。
每个事务又有自己的版本号,这样事务内执行CRUD操作时,就通过版本号的比较来达到数据版本控制的目的。
MVCC逻辑流程- https://www.cnblogs.com/luchangyou/p/11321607.html
2.mybatis里的#和$区别,#的底层是怎么实现的?
mybatis的#{}和${}的区别和底层实现 ${} (Statement实现): 1、只是简单的替换,传递的参数会被当成sql语句中的一部分(不能防止sql注入) 2、建议like和order by后使用
#{} (PreprareStatement实现): 1、解析为一个 '?'占位符号,会对自动传入的数据加一个双引号(可以防止sql注入)
预编译的机制:预编译是提前对SQL编译之前进行预编译,而其后注入的参数将不会再进行编译。因为SQL注入是发生在编译的过程中,因为恶意注入了某些特殊字符,最后被编译成了恶意的执行操作。所以预编译机制则可以很好的防止SQL注入
3.mysql的索引底层实现是什么?聚簇索引和非聚簇索引的区别?b+树和b树有什么区别,为什么索引数据结构采用的是b+树而不是b树?查询次数少,树更矮?为什么?
https://blog.csdn.net/u013132035/article/details/82193763
1)聚簇索引和非聚簇索引区别:

聚簇索引的优点
-
聚簇索引将索引和数据行保存在同一个B-Tree中,查询通过聚簇索引可以直接获取数据,相比非聚簇索引需要第二次查询(非覆盖索引的情况下)效率要高。
-
聚簇索引对于范围查询的效率很高,因为其数据是按照大小排列的,
非聚簇索引
非聚簇索引,又叫二级索引。二级索引的叶子节点中保存的不是指向行的物理指针,而是行的主键值。当通过二级索引查找行,存储引擎需要在二级索引中找到相应的叶子节点,获得行的主键值,然后使用主键去聚簇索引中查找数据行,这需要两次B-Tree查找。
数据库采用B+树而不是B-树 b树的原因
https://blog.csdn.net/fei33423/article/details/48469899
2)B+树还有一个最大的好处,方便扫库,B树必须用中序遍历的方法按序扫库,而B+树直接从叶子结点挨个扫一遍就完了,B+树支持range-query非常方便,而B树不支持。这是数据库选用B+树的最主要原因。
B+树是B树的变形,它把所有的附属数据都放在叶子结点中,只将关键字和子女指针保存于内结点,内结点完全是索引的功能,最大化了内结点的分支因子。不过是n个关键字对应着n个子女,子女中含有父辈的结点信息,叶子结点包含所有信息(内结点包含在叶子结点中,内结点没有指向“附属数据”的指针必须索引到叶子结点)。这样的话还有一个好处就是对于每个结点所需的索引次数都是相等的,保证了稳定性。
【B*树】
B树是B+树的变体,**在B+树非根和*非叶子结点再增加指向兄弟的指针*;B树定义了非叶子结点关键字个数至少为(2/3)*M**,即块的最低使用率为2/3(代替B+树的1/2)。
B+树的分裂:当一个结点满时,分配一个新的结点,并将原结点中1/2的数据复制到新结点,最后在父结点中增加新结点的指针;B+树的分裂只影响原结点和父结点,而不会影响兄弟结点,所以它不需要指向兄弟的指针;
B*树的分裂:当一个结点满时,如果它的下一个兄弟结点未满,那么将一部分数据移到兄弟结点中,再在原结点插入关键字,最后修改父结点中兄弟结点的关键字(因为兄弟结点的关键字范围改变了);如果兄弟也满了,则在原结点与兄弟结点之间增加新结点,并各复制1/3的数据到新结点,最后在父结点增加新结点的指针;
所以,B*树分配新结点的概率比B+树要低,空间使用率更高;
4.spring的IOC了解吗?spring是怎样解决循环依赖的问题的?
---《面试突击第三季》26,27讲
高频面试题:Spring 如何解决循环依赖?
https://zhuanlan.zhihu.com/p/84267654
关于Spring bean的创建,其本质上还是一个对象的创建,既然是对象,一定要明白一点就是,一个完整的对象包含两部分:当前对象实例化和对象属性的实例化。
在Spring中,对象的实例化是通过反射实现的,而对象的属性则是在对象实例化之后通过一定的方式设置的。
@Component
public class A {
private B b;
public void setB(B b) {
this.b = b;
}
}
@Component
public class B {
private A a;
public void setA(A a) {
this.a = a;
}
}
首先Spring尝试通过ApplicationContext.getBean()方法获取A对象的实例,由于Spring容器中还没有A对象实例,因而其会创建一个A对象
然后发现其依赖了B对象,因而会尝试递归的通过ApplicationContext.getBean()方法获取B对象的实例
但是Spring容器中此时也没有B对象的实例,因而其还是会先创建一个B对象的实例。
读者需要注意这个时间点,此时A对象和B对象都已经创建了,并且保存在Spring容器中了,只不过A对象的属性b和B对象的属性a都还没有设置进去。
因为Spring中已经有一个A对象的实例,虽然只是半成品(其属性b还未初始化),但其也还是目标bean,因而会将该A对象的实例返回。
此时,B对象的属性a就设置进去了,然后还是ApplicationContext.getBean()方法递归的返回,也就是将B对象的实例返回,此时就会将该实例设置到A对象的属性b中。
这个时候,注意A对象的属性b和B对象的属性a都已经设置了目标对象的实例了
这里的A对象其实和前面设置到实例B中的半成品A对象是同一个对象,其引用地址是同一个,这里为A对象的b属性设置了值,其实也就是为那个半成品的a属性设置了值。
。。。。详见上文链接
https://blog.csdn.net/qq_34387962/article/details/117075687
spring ioc作用:

5.1、Java内存模型原理:
**JAVA内存模型: Java内存模型规定所有的变量都是存在主存中,每个线程都有自己的工作内存。线程堆变量的操作都必须在工作内存进行,不能直接堆主存进行操作,并且每个线程不能访问其他线程的工作内存。 Java内存模型的Volatile关键字,原子性、可见性、有序性 详情

Java内存模型中的原子性、可见性、有序性是什么?
连环炮:Java内存模型-->原子性、可见性、有序性-->volatile-->happen-before/内存屏障,
原子性,可见性,有序性,并发过程中,可能会产生的三个问题
有可见性:比如加了volatile修饰的变量,线程1修改这个变量后,线程2读取的时候需要重新从主内存去读取,而不是使用工作内存里面的,这样线程1的修改其他线程就可以感知到,这就是有可见性。
原子性:data++,必须是独立执行的,没有人影响我的,一定是我自己执行成功之后别人才能来进行下一次的data++的执行。如果不加任何修饰,默认情况下不是原子性的,不是线程安全的。
有序性:对于代码,同时还有一个问题是指令重排序,编译器和指令器,有的时候为了提高代码的执行效率,会将指令重排序。
具备有序性,不会发生指令重排导致我们的代码异常;不具备有序性,会发生指令重排,导致代码可能会出现一些问题。
###
JAVA内存模型与JVM内存模型的区别
** 直接进入正题
**JAVA内存模型: Java内存模型规定所有的变量都是存在主存中,每个线程都有自己的工作内存。线程堆变量的操作都必须在工作内存进行,不能直接堆主存进行操作,并且每个线程不能访问其他线程的工作内存。 Java内存模型的Volatile关键字,原子性、可见性、有序性 详情 **JVM内存模型: 虚拟机栈:用来放局部变量、堆区对象的引用和常量池对象的引用;但对象本身不存放在栈中,而是存放在堆(new出来的对象)或者常量池中(对象可能在常量池里)(字符串常量对象存放在常量池中。);
方法区:存放类的信息;此区包含常量池(常量池用来放基本类型常量和字符串类型常量),此部分可以回收;方法区可以放用static修饰的变量,但此部分不能回收,因为方法区也叫持久带,永久带基本不参与垃圾回收;
堆::存放一些new出的对象(包含成员变量),和数组。但发生方法逃逸了就不会保存堆里面了。
关于内存模型的图片:
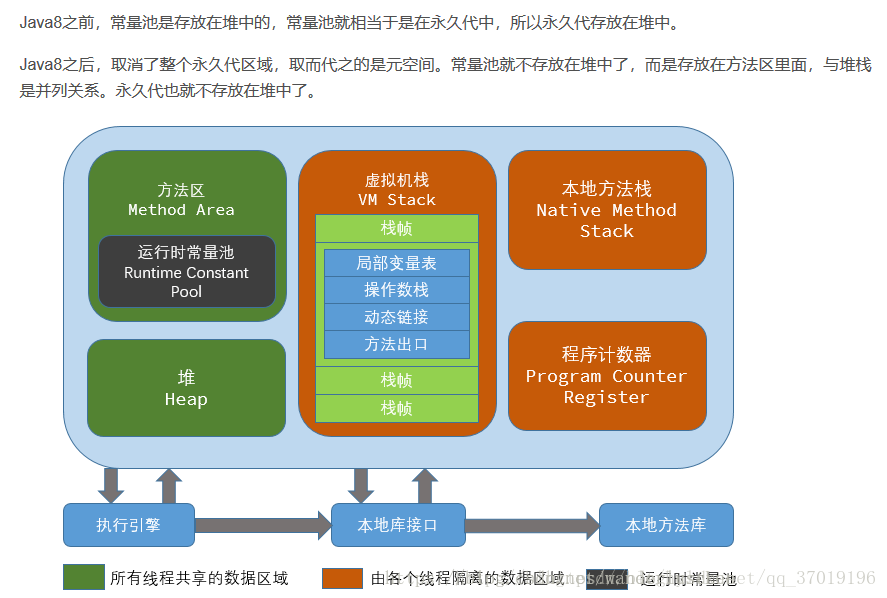
JVM内存模型如上图?JVM 哪块内存区域不会发生内存溢出?
程序计数器(Program Counter Rerister)
程序计数器是一块内存较小的区域,它用于存储线程的每个执行指令,每个线程都有自己的程序计数器,此区域不会有内存溢出的情况。
5.2、JVM中有哪几块内存区域?Java_8之后对内存分代做了什么改进?
堆内存:存放对象,所有线程均可使用
栈内存:工作线程自己独有的
永久代:自己写的类加载的地方,存放一些常量池、类信息
Java8内存分代的改进
【永久代】改叫【metaspace元空间】,将常量池存放在堆内存中,类信息存放在metaspace元空间
《面试突击第三季》36--40
6.类加载过程?双亲委派机制?
https://www.cnblogs.com/wyq178/p/10127578.html
二:类加载过程
类加载一共分为七个过程,他们的具体的顺序是:加载->验证->准备->解析->初始化,接下来我们来一一介绍这些过程:
2.1:加载
类加载过程中,虚拟机需要完成以下三件事:
(1)通过一个类的全限定名来获取定义此类的二进制字节流
(2)将这个字节流所代表的静态存储结构转化为方法区的运行时数据结构
(3)在内存中生成一个代表此类的java.lang.class的对象,作为方法区的这个类的访问入口
2.2:验证
2.2.1:文件格式的验证
2.2.2:元数据的验
2.2.3:字节码验证
2.2.4:符号引用的验证
三:双亲委派机制
3.1:类加载器的分类
3.1.1:启动类加载器
这个加载器主要负责将存放在<JAVA_HOME>的lib目录下的,或者被--Xbootclasspath参数所指定的路径中的,并且被虚拟机识别的(比如rt.jar).名字不符合的类库即使放在lib目录下也会被加载。
3.1.2:扩展类加载器
这个加载器主要负责加载存放在<JAVA_HOME>/lib/ext目录下的java类库,或者而被java.ext.dirs系统变量所指定的路径的所有类库,开发者可以直接使用扩展类加载器
3.1.3:应用程序加载器
这个类加载器负责加载用户类路径上所指定的类库,如果程序中没有定义过自己的类加载器,那么一般情况下这个就是程序中默认的类加载器。
3.2:双亲委派机制
指的是:如果一个类加载器收到了类加载的请求,它首先不会自己去尝试加载这个类,而是把这个请求委派给父类加载器去完成,(每一个层次的类加载器都是如此)。只有当父加载器反馈自己无法完成这个加载请求(它的搜索范围中没有找到所需的类)时,子加载器才会尝试自己加载完成。

1.双亲委派模型的工作过程 如果一个类加载器收到了类加载的请求,它首先不会自己去尝试加载这个类,而是把这个请求委派给父类加载器去完成,因此所有的加载请求最终都应该传送到顶层的启动类加载器中,只有当父加载器反馈自己无法完成这个加载请求(它的搜索范围中没有找到所需的类)时,子加载器才会尝试自己去加载。
2.双亲委派模型的好处 Java类随着它的类加载器一起具备了一种带有优先级的层次关系。例如java.lang.Object,它存放在rt.jar之中,无论哪一个类加载器要加载这个类,最终都是委派给启动类加载器进行加载,因此Object类在程序的各种类加载器环境中都是同一个类。相反,如果没有使用双亲委派模型,由各个类加载器自行去加载的话,若用户自己写了一个名为java.lang.Object的类,并放在程序的ClassPath中,那系统中将会出现多个不同的Object类,应用程序将会变得一片混乱。
3.双亲委派模型的实现 实现模型的代码都集中在java.lang.ClassLoader的loadClass()方法之中。先检查是否已经被加载过,若加载过则返回类的Class对象,若没有加载则调用父类加载器的loadClass()方法,从父类到子类依次尝试加载,若父加载器为空则默认使用启动类加载器作为父加载器,若父类加载失败,则抛出ClassNotFoundException异常后,再调用自己的findClass()方法进行加载。
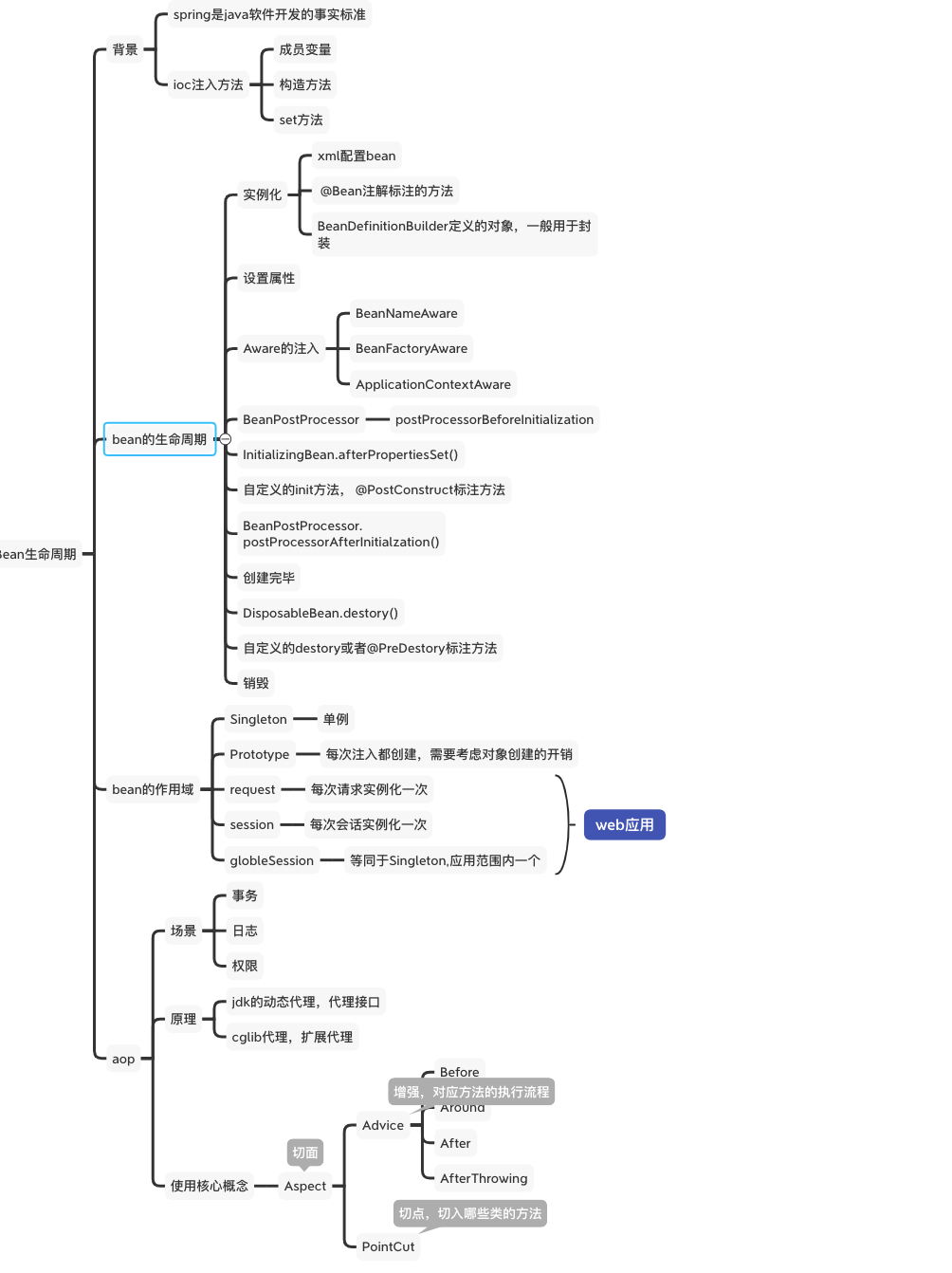
7.spring bean的生命周期
具体如下图,很细。
bean生命周期大致分为:实例化bean,设置属性,Aware的注入,BeanPostProcessor--postProcessorBeforeInitialization--->
自定义的init方法,@PostConstruct 创建完成 自定义destory方法--> 销毁
8.sential是单独模块还是怎样??---这个当时没说出来,一下子忘了。。其实是哪个模块需要就引入,或者说直接在common工程里引入。
??? 9.RocketMQ是单独一个模块还是怎样??这个当时没答上来。。。因为<<谷粒商城>>项目的这部分跳过了,,没看。。。。
-----去看,好好学。
10.权限管理系统涉及数据表怎样设计,有哪些主要字段??
https://www.jianshu.com/p/6f65212e5c39
11.让你设计一个秒杀系统,怎样设计?
详见《谷粒商城》秒杀系统实现。
12.冒泡排序算法
package day0515; public class demo_sort { public static void main(String[] args) { //冒泡排序算法 int[] numbers=new int[]{1,5,8,2,3,9,4}; //需进行length-1次冒泡 for(int i=0;i<numbers.length-1;i++) { for(int j=0;j<numbers.length-1-i;j++) { if(numbers[j]>numbers[j+1]) { int temp=numbers[j]; numbers[j]=numbers[j+1]; numbers[j+1]=temp; } } } System.out.println("从小到大排序后的结果是:"); for(int i=0;i<numbers.length;i++) System.out.print(numbers[i]+" "); } }
13.Oracle,mysql的分页查询SQL
1、Mysql的分页查询:
SELECT
*
FROM
student
LIMIT (PageNo - 1) * PageSize,PageSize;
理解:(Limit n,m) =>从第n行开始取m条记录,n从0开始算。
2、Oracel的分页查询:
select * from(selct ROWNUM rn,* from student where ROWNUM<=pageNo*pageSize) where rn>(pageNo-1)*pageSize;
理解:假设pageNo = 1,pageSize = 10,先从student表取出行号小于等于10的记录,然后再从这些记录取出rn大于0的记录,从而达到分页目的。ROWNUM从1开始。
14.ThreadLocal底层实现
ThreadLocal是一个解决线程并发问题的一个类,用于创建线程的本地变量,我们知道一个对象的所有线程会共享它的全局变量,所以这些变量不是线程安全的,我们可以使用同步技术。但是当我们不想使用同步的时候,我们可以选择ThreadLocal变量。
每个线程都会拥有他们自己的Thread变量,他们可以使用get/set方法去获取他们的默认值或者在线程内部改变他们的值。ThreadLocal实例通常是希望他们同线程状态关联起来是private static属性。
底层实现主要是存有一个map,以线程作为key,泛型作为value,可以理解为线程级别的缓存。每一个线程都会获得一个单独的map。
ThreadLocal不支持继承性,子线程是获取不到父线程的值的。可以使用inheritableThreadLocal来解决不能继承问题。它的底层实现也非常简单。当父线程创建子线程时,会把父线程的变量复制到子线程里面。
在JUC包里面的ThreadLocalRandom就是使用ThreadLocal原理实现的。
面试常问之ThreadLocal底层原理
https://blog.csdn.net/qq_45336137/article/details/107982974
15.登录过程,权限验证,单点登录
16.synchronize,
volatile底层是如何基于内存屏障保证可见性和有序性的?
---《面试突击第三季》
23、能从底层角度聊聊volatile关键字的原理吗?
如果面试官上来直接问volatile,那么应该先从内存模型开始讲,然后谈原子性、可见性、有序性的理解,最后再讲volatile关键字的原理
volatile关键字是用来解决可见性和有序性
volatile用途:(1)保证内存可见性 (2)禁止指令重排
volatile会在线程1执行data++之后将值设置会工作内存并写到主内存中的同时,将其他线程的工作缓存中data的值设置为失效。当线程在执行下次操作的时候,发现工作内存中的值失效了,回去主内存中再次读取
【评论区】
1、可见性是指,下次使用的时候值可见。可见性并不能保证原子性 ———————————————— 版权声明:本文为CSDN博主「装兔子的猫」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。 原文链接:https://blog.csdn.net/ksws01/article/details/110873521
24、你知道指令重排以及happens-before原则是什么吗?
【面试题】你知道指令重排以及happens-before原则是什么吗? https://blog.csdn.net/ksws01/article/details/110873554
happens-before原则,一定程度上避免指令重排
编译器、指令器可能对代码重排序、乱排、要守一定的规则,happens-before原则。只要符合happens-before的原则,那么就不能胡乱重排序,如果不符合这个规则,那么就可以自己排序。
happens-before八大原则
(单线程happen-before原则:在同一个线程中,书写在前面的操作happen-before后面的操作。 锁的happen-before原则:同一个锁的unlock操作happen-before此锁的lock操作。 volatile的happen-before原则:对一个volatile变量的写操作happen-before对此变量的任意操作(当然也包括写操作了)。 happen-before的传递性原则:如果A操作 happen-before B操作,B操作happen-before C操作,那么A操作happen-before C操作。 线程启动的happen-before原则:同一个线程的start方法happen-before此线程的其它方法。 线程中断的happen-before原则:对线程interrupt方法的调用happen-before被中断线程的检测到中断发送的代码。 线程终结的happen-before原则:线程中的所有操作都happen-before线程的终止检测。 对象创建的happen-before原则:一个对象的初始化完成先于他的finalize方法调用。)
有过有面试官问happens-before原则,不是说要把8条背出来。而是说,规则制定了在一些特殊情况下,不允许编译器、指令器对你写的代码进行指令重排,必须保证你的代码的有序性
但是如果没有满足上面的规则,那么就可能会出现指令重排。这8条原则是避免出现指令重排的情况,要求这几个重要的场景下,是按照顺序来,但是8条规则之外,可以随意重排指令。
比如说这个例子,如果用volatile来修饰flag变量,一定可以让prepare()指令在flag=true之前执行这就禁止了指令重排。因为volatile要求的是,volatile前面的代码一定不能指令重拍到其修饰的变量操作后面,volatile后面的代码也不能指令重排到volatile前面。
(1)知道指令重排是什么意思
(2)知道happen-before原则
(3)volatile避免指令重排
25、volatile底层是如何基于内存屏障保证可见性和有序性的?
面试题: https://www.freesion.com/article/9021645644/
可见性问题指的是一个线程在访问一个共享变量的时候,其他线程对该共享变量的修改对于第一个线程来说是不可见的,
造成可见性问题的原因 在Java中造成可见性问题的原因是Java内存模型(JMM),在Java内存模型中,规定了共享变量是存放在主内存中,然后每个线程都有自己的工作内存,而线程对共享变量的操作,必须先从主内存中读到工作内存中去,至于什么时候写回到主内存是不可预知的,这就导致每个线程之间对共享变量的操作是封闭的,其他线程不可见的。
如何解决可见性问题? 可见性问题的解决可以加synchronized关键字,但是有点小题大做的感觉,其实可以使用轻量级的同步机制volatile来保证高并发的线程之间的可见性问题
当处理器发现自己缓存行对应的内存地址被修改,就会将当前处理器的缓存行设置成无效状态,那么下次对这个数据进行操作,就会重新从系统内存中获取最新的值。对应JMM来说就是:
1. Lock前缀的指令让线程工作内存中的值写回主内存中;` `2. 通过缓存一致性协议,其他线程如果工作内存中存了该共享变量的值,就会失效;` `3. 其他线程会重新从主内存中获取最新的值;
为了性能优化,JVM会在不改变数据依赖性的情况下,允许编译器和处理器对指令序列进行重排序,而有序性问题指的就是程序代码执行的顺序与程序员编写程序的顺序不一致,导致程序结果不正确的问题。而加了volatile修饰的共享变量,则通过内存屏障解决了多线程下有序性问题。
VOLATILE内存语义的实现
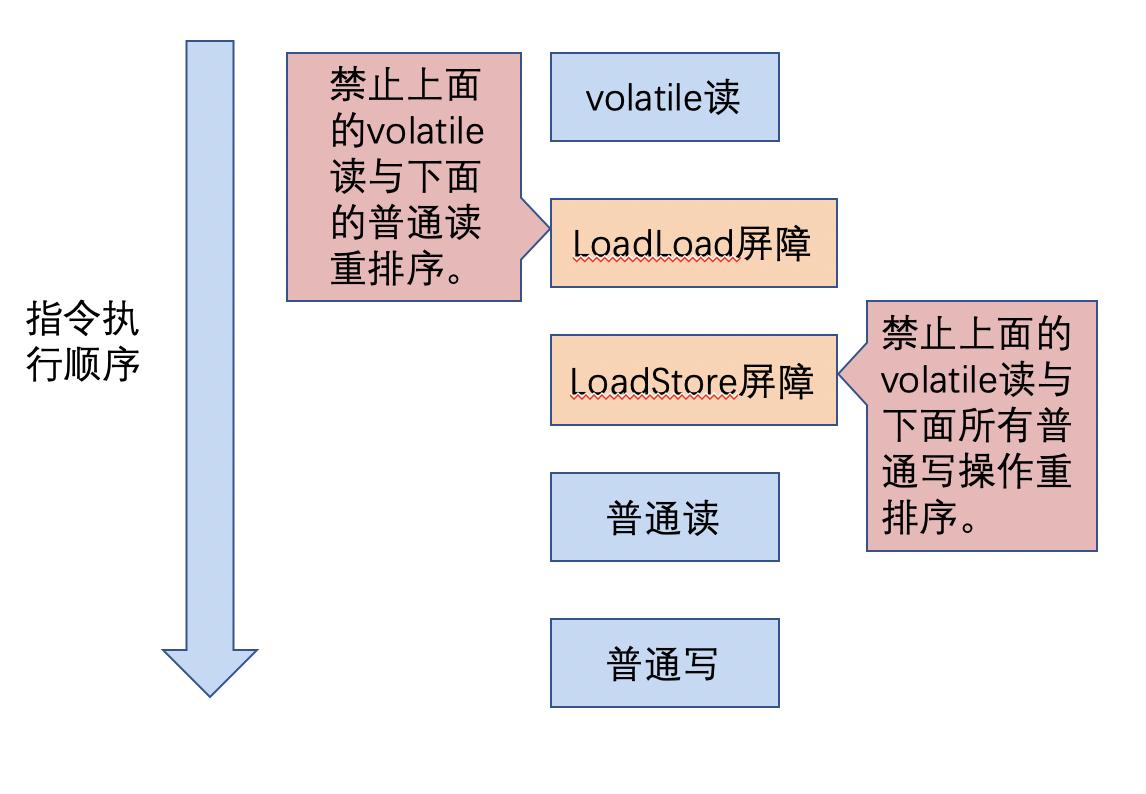
为了实现volatile的内存语义,编译器在生成字节码时,会在指令序列中插入内存屏障来禁止特定类型的处理器重排序,下面是基于保守策略的JMM内存平展插入策略。
* 在每个volatile写操作的前面插入一个StoreStore屏障。` `* 在每个volatile写操作的后面插入一个StoreLoad屏障。` `* 在每个volatile读操作的后面插入一个LoadLoad屏障。` `* 在每个volatile读操作的后面插入一个LoadStore屏障。
volatile在写操作前后插入了内存屏障后生成的指令序列示意图如下:

volatile在读操作后面插入了内存屏障后生成的指令序列示意图如下:
44、你能聊聊TCPIP四层网络模型吗?OSI七层网络模型也说一下!
这里要着重区分一下MAC地址和IP 地址:
对于MAC地址,由于我们不直接和它接触,所以大家不一定很熟悉。在OSI(Open System Interconnection,开放系统互连)7层网络协议(物理层,数据链路层,网络层,传输层,会话层,表示层,应用层)参考模型中,第二层为数据链路层(Data Link)。它包含两个子层,上一层是逻辑链路控制(LLC:Logical Link Control),下一层即是我们前面所提到的MAC(MediaAccess Control)层,即介质访问控制层。所谓介质(Media),是指传输信号所通过的多种物理环境。常用网络介质包括电缆(如:双绞线,同轴电缆,光纤),还有微波、激光、红外线等,有时也称介质为物理介质。MAC地址也叫物理地址、硬件地址或链路地址,由网络设备制造商生产时写在硬件内部。这个地址与网络无关,也即无论将带有这个地址的硬件(如网卡、集线器、路由器等)接入到网络的何处,它都有相同的MAC地址,MAC地址一般不可改变,不能由用户自己设定。
mac地址可以标识全世界上唯一一台主机,仅仅在局域网内有效。 ip地址可以标识世界上唯一一台联网的主机,在广域网内也有效
TCP/IP四层模型,数据链路层、网络层、传输层、应用层。
OSI七层模型,应用层、表示层、会话层、传输层、网络层、数据链路层、物理层。
网络基础(一)------------TCP/IP四层模型和网络传输基本流程 https://blog.csdn.net/daboluo521/article/details/80373310
TCP/IP是两个独立的且紧密结合的协议,负责管理和引导数据报文在网络上的传输。TCP负责和远程主机的连接,IP负责寻址,是报文被送到其该去的地方。 TCP/IP也分为不同的层次开发,每一层负责不同的通信功能,但TCP/IP协议简化了层次设备。而由下而上一次是网络接口层、网络层、传输层、应用层。
-
网络接口层:有时候也称为数据链路层,通常包括操作系统中设备的驱动程序和计算机相应的网络接口卡。
-
网络层:处理分组在网络中的活动,如分组的选路。
-
传输层:主要为两台主机上的应用程序提供端到端的通信。
-
应用层:负责处理特定的应用程序和程序细节。

网络传输的基本流程
网络传输的流程图 局域内两台主机通过TCP/IP协议通讯的过程如下所示:

首先用户层需要传输文件,那么就需要文件传输协议。 在需要传送的数据加上文件传输协议的报头,呼叫下一层。 传输层接收到这个指令之后,加上该层的协议报头,再呼叫下一层。 网络层收到这个指令之后,加上网络层的报头,传给链路层。 链路层的协议中包括传送目标。通过局域网传送给了对方主机的链路层。 以上过程称为——封装。
两个主机此时不在同一个局域网内,所以它们两个主机想要沟通,就必须通过路由器。 客户从用户层发送数据,自顶向下发送,一步步添加报头信息,这是封装的过程。然后发送到局域网内,可是发送方发送数据时,已经知道了他要发送数据的接收方不在这个局域网内。那么他就会将该数据发给路由器。寻求路由器的帮助,帮助它转发。
路由器也是一个主机,所以他经过解包,得到了目标主机的ip地址,然后在经过封装,此时就会加上目标局域网的报头信息。(相当于该数据换了身衣服)通过路由器的路由功能,数据被发送到了接收方的局域网内,该局域网内所有主机都能收到,但是在通过解析,只有指定接收方会响应。 这就是在广域网内数据传输的过程。
———————————————— 版权声明:本文为CSDN博主「@make great efforts 」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。 原文链接:https://blog.csdn.net/daboluo521/article/details/80373310
17.HashMap底层实现?扩容是发生在put前还是后的?
https://blog.csdn.net/u014733604/article/details/85037848














 44万+
44万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









