






引入
如果总进程数 world_size 只有 1,那么 rank 只能是 0,因为只有一个进程在运行。
在这种情况下,即使程序进入了分布式模式分支(else部分)的逻辑,也可以正常运行:
if args.non_dist:
my_part = annos
os.makedirs(args.tmpdir, exist_ok=True)
else:
init_dist('pytorch', backend='nccl')
rank, world_size = get_dist_info()
if rank == 0:
os.makedirs(args.tmpdir, exist_ok=True)
dist.barrier()
my_part = annos[rank::world_size]具体分析如下:
-
当
world_size == 1时:rank只能是 0,因为只有一个进程在运行。if rank == 0:这个条件永远成立,所以 rank 为 0 的进程会创建args.tmpdir目录。dist.barrier()也不会产生任何影响,因为只有一个进程在等待。
-
对于
my_part = annos[rank::world_size]这一行:- 由于
world_size == 1,rank::world_size等价于rank,即 0。 - 因此
my_part会被赋值为annos[0],也就是完整的annos数据集。
- 由于
所以即使总进程数为 1,程序也能正常地在分布式模式下运行,并得到和非分布式模式下相同的结果。
这种设计确实很灵活,可以让程序适应单机和分布式两种不同的运行环境。当只有一个进程时,代码会自动退化为单机模式,不需要做特殊处理。这样可以让程序更加通用和易用。
解释
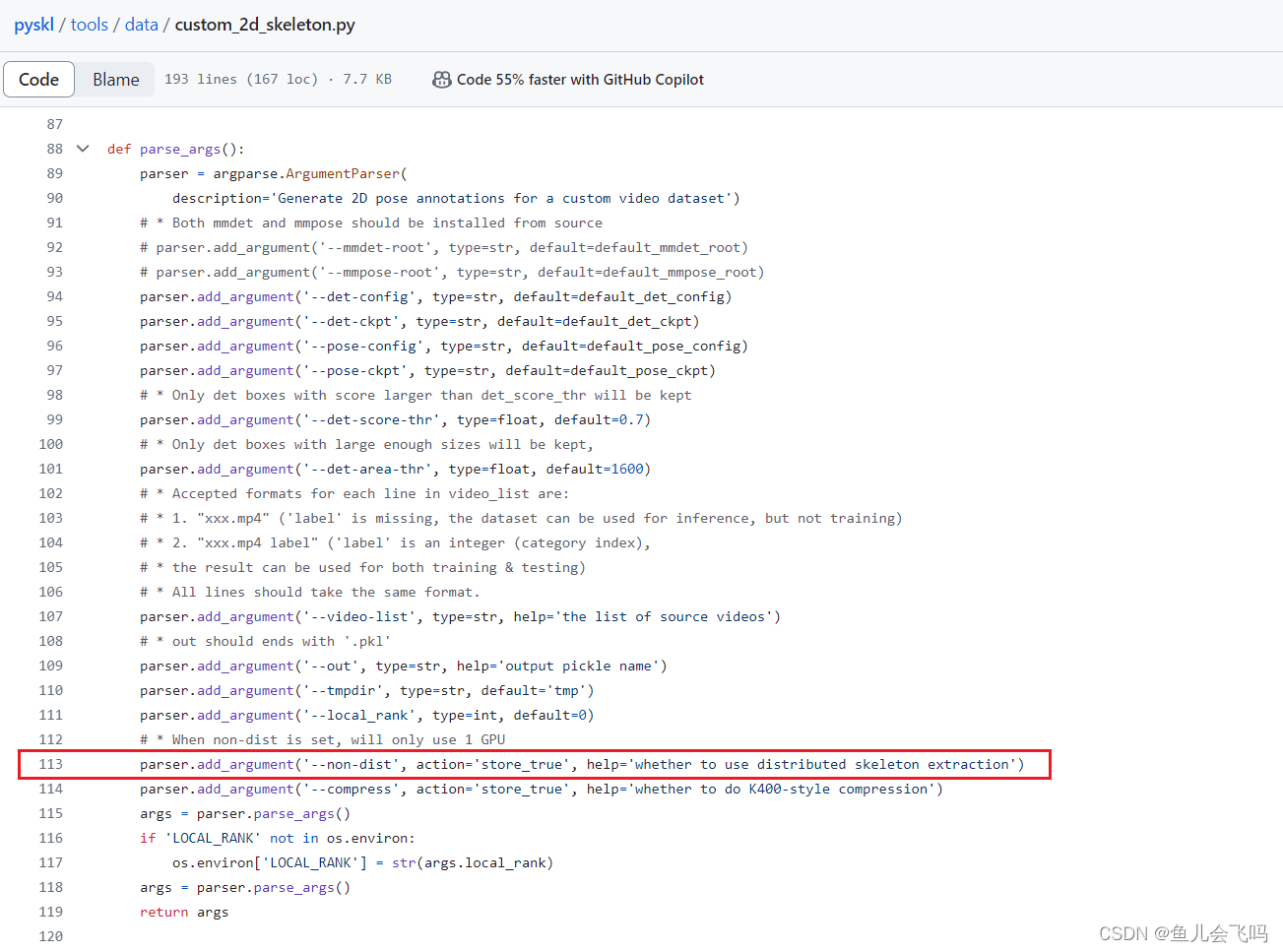
parser.add_argument('--non-dist', action='store_true', help='whether to use distributed skeleton extraction')parser是一个命令行参数解析器,通常是使用 Python 的argparse模块创建的。add_argument()方法用于向解析器添加一个新的命令行参数。
在这个例子中:
'--non-dist'是这个参数的名称。它以--开头,表示这是一个可选参数,而不是必需参数。action='store_true'指定了这个参数的行为。store_true意味着如果用户在命令行中包含了这个参数,它的值就会被设置为True。否则默认为False。help='whether to use distributed skeleton extraction'提供了这个参数的简单描述,用于在命令行帮助信息中显示。
总的来说,这行代码定义了一个名为 --non-dist 的可选参数。如果用户在命令行中包含了这个参数,它会被解析为 True。开发者可以在程序中检查这个参数的值,从而决定是否使用分布式的骨骼提取方法。
这种命令行参数定义方式非常常见,可以让用户更方便地控制程序的行为。
问题
问题1
如果它被解析为 True,会什么后果?
如果命令行参数 --non-dist 被解析为 True,那么它会对程序的行为产生以下影响:
-
不使用分布式的骨骼提取方法:
- 通常情况下,程序会使用分布式的方法来提取骨骼数据,以提高处理速度和效率。
- 但是如果
--non-dist参数被设置为True,程序就会改用非分布式的骨骼提取方法。
-
可能降低处理速度:
- 分布式处理能够并行化任务,从而加快处理速度。
- 但如果选择了非分布式方式,由于无法充分利用并行计算能力,处理速度可能会降低。
-
可能降低内存利用率:
- 分布式处理可以充分利用多台机器的内存资源。
- 而非分布式处理只能使用单台机器的内存,可能会受内存容量的限制。
总的来说,设置 --non-dist 参数为 True 可能会降低程序的处理性能,但可能在某些特殊情况下是有必要的,例如:
- 计算资源有限,无法支持分布式处理
- 需要更好的内存管理或更细粒度的控制
- 调试或测试分布式处理的实现
所以开发者需要根据具体需求来权衡是否使用分布式骨骼提取方法。这个参数提供了灵活性,让用户可以根据自己的需求来控制程序的行为。
问题2
默认是什么?
默认情况下,--non-dist 参数的值是 False。
这是因为 action='store_true' 意味着:
- 如果用户在命令行中包含了
--non-dist参数,它的值会被设置为True。 - 如果用户没有包含
--non-dist参数,它的默认值会是False。
也就是说,默认情况下,程序会使用分布式的骨骼提取方法,除非用户在命令行中显式地设置 --non-dist 参数为 True。
这种设计是很常见的,因为分布式处理通常是更推荐的方式,除非用户有特殊需求。将默认值设置为 False 可以让大多数用户无需考虑这个参数就可以使用最佳的处理方式。
当然,开发者也可以根据具体需求改变这个默认值。例如,如果非分布式的骨骼提取方法通常更合适,那么可以将默认值设置为 True。这需要根据实际情况进行权衡和决策。
问题3
单显卡情况应该如何修改代码
如果是单显卡需要修改代码
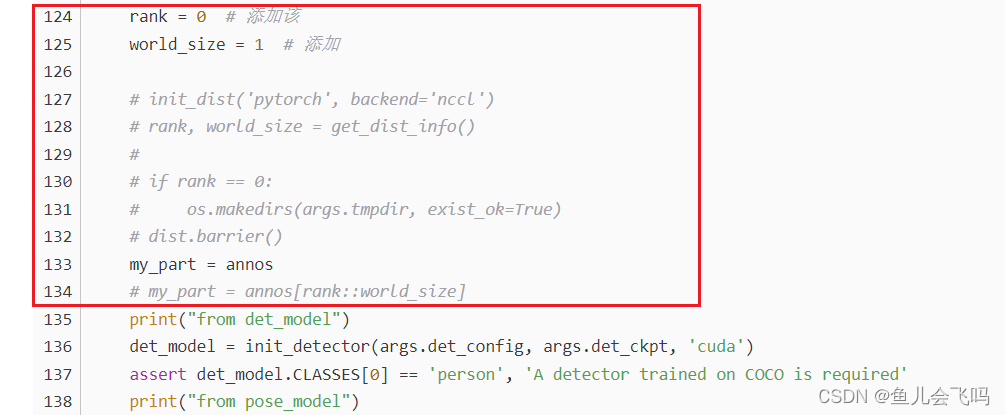
rank = 0 # 添加该
world_size = 1 # 添加
# init_dist('pytorch', backend='nccl')
# rank, world_size = get_dist_info()
#
# if rank == 0:
# os.makedirs(args.tmpdir, exist_ok=True)
# dist.barrier()
my_part = annos
# my_part = annos[rank::world_size]目的
将 rank 设为 0, world_size 设为 1, 并且注释掉了初始化分布式环境以及数据切分的部分。这样做的目的是:
-
模拟单进程场景: 通过将
world_size设为 1, 可以模拟只有一个进程在运行的场景。这相当于进入了非分布式的模式。 -
跳过分布式初始化: 注释掉了
init_dist()和get_dist_info()的调用,避免了初始化分布式环境的代码执行。 -
使用完整数据集: 将
my_part直接设置为annos, 意味着每个进程都会处理完整的数据集,而不是将数据集切分。
这样的修改可以让程序在单进程环境下运行,不需要涉及任何分布式计算的逻辑。这对于调试或测试程序的非分布式功能很有帮助,因为可以排除分布式相关的复杂因素。
总的来说,修改是为了简化代码,让它能在单进程模式下正常运行,以便更容易地测试和调试程序的基本功能。这是一种常见的优化和简化代码的方式,有助于提高开发效率。
https://github.com/kennymckormick/pyskl/blob/main/tools/data/custom_2d_skeleton.py
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









