






import argparse
import cv2
import mmcv
import numpy as np
import os
import os.path as osp
import shutil
import torch
import warnings
from scipy.optimize import linear_sum_assignment
from pyskl.apis import inference_recognizer, init_recognizer
try:
from mmdet.apis import inference_detector, init_detector
except (ImportError, ModuleNotFoundError):
def inference_detector(*args, **kwargs):
pass
def init_detector(*args, **kwargs):
pass
warnings.warn(
'Failed to import `inference_detector` and `init_detector` from `mmdet.apis`. '
'Make sure you can successfully import these if you want to use related features. '
)
try:
from mmpose.apis import inference_top_down_pose_model, init_pose_model, vis_pose_result
except (ImportError, ModuleNotFoundError):
def init_pose_model(*args, **kwargs):
pass
def inference_top_down_pose_model(*args, **kwargs):
pass
def vis_pose_result(*args, **kwargs):
pass
warnings.warn(
'Failed to import `init_pose_model`, `inference_top_down_pose_model`, `vis_pose_result` from '
'`mmpose.apis`. Make sure you can successfully import these if you want to use related features. '
)
try:
import moviepy.editor as mpy
except ImportError:
raise ImportError('Please install moviepy to enable output file')
def parse_args():
parser = argparse.ArgumentParser(description='PoseC3D demo')
# parser.add_argument('video', help='video file/url')
# parser.add_argument('out_filename', help='output filename')
parser.add_argument(
'--config',
default='../configs/posec3d/slowonly_r50_ntu120_xsub/joint.py',
help='skeleton action recognition config file path')
parser.add_argument(
'--checkpoint',
default='https://download.openmmlab.com/mmaction/pyskl/ckpt/posec3d/slowonly_r50_ntu120_xsub/joint.pth',
help='skeleton action recognition checkpoint file/url')
parser.add_argument(
'--det-config',
default='../demo/faster_rcnn_r50_fpn_1x_coco-person.py',
help='human detection config file path (from mmdet)')
parser.add_argument(
'--det-checkpoint',
default=('https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco-person/'
'faster_rcnn_r50_fpn_1x_coco-person_20201216_175929-d022e227.pth'),
help='human detection checkpoint file/url')
parser.add_argument(
'--pose-config',
default='../demo/hrnet_w32_coco_256x192.py',
help='human pose estimation config file path (from mmpose)')
parser.add_argument(
'--pose-checkpoint',
default='https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w32_coco_256x192-c78dce93_20200708.pth',
help='human pose estimation checkpoint file/url')
parser.add_argument(
'--det-score-thr',
type=float,
default=0.9,
help='the threshold of human detection score')
parser.add_argument(
'--label-map',
default='../tools/data/label_map/nturgbd_120.txt',
help='label map file')
parser.add_argument(
'--device', type=str, default='cuda:0', help='CPU/CUDA device option')
args = parser.parse_args()
return args
def frame_extraction(video_path, short_side):
target_dir = osp.join('./tmp', osp.basename(osp.splitext(video_path)[0]))
os.makedirs(target_dir, exist_ok=True)
# Should be able to handle videos up to several hours
frame_tmpl = osp.join(target_dir, 'img_{:06d}.jpg')
vid = cv2.VideoCapture(video_path)
frames = []
frame_paths = []
flag, frame = vid.read()
cnt = 0
new_h, new_w = None, None
while flag:
if new_h is None:
h, w, _ = frame.shape
new_w, new_h = mmcv.rescale_size((w, h), (short_side, np.Inf))
frame = mmcv.imresize(frame, (new_w, new_h))
frames.append(frame)
frame_path = frame_tmpl.format(cnt + 1)
frame_paths.append(frame_path)
cv2.imwrite(frame_path, frame)
cnt += 1
flag, frame = vid.read()
return frame_paths, frames
def detection_inference(args, frame_paths):
"""Detect human boxes given frame paths.
Args:
args (argparse.Namespace): The arguments.
frame_paths (list[str]): The paths of frames to do detection inference.
Returns:
list[np.ndarray]: The human detection results.
"""
model = init_detector(args.det_config, args.det_checkpoint, args.device)
assert model is not None, ('Failed to build the detection model. Check if you have installed mmcv-full properly. '
'You should first install mmcv-full successfully, then install mmdet, mmpose. ')
assert model.CLASSES[0] == 'person', 'We require you to use a detector trained on COCO'
results = []
print('Performing Human Detection for each frame')
prog_bar = mmcv.ProgressBar(len(frame_paths))
for frame_path in frame_paths:
result = inference_detector(model, frame_path)
# We only keep human detections with score larger than det_score_thr
result = result[0][result[0][:, 4] >= args.det_score_thr]
results.append(result)
prog_bar.update()
return results
def pose_inference(args, frame_paths, det_results):
model = init_pose_model(args.pose_config, args.pose_checkpoint,
args.device)
ret = []
print('Performing Human Pose Estimation for each frame')
prog_bar = mmcv.ProgressBar(len(frame_paths))
for f, d in zip(frame_paths, det_results):
# Align input format
d = [dict(bbox=x) for x in list(d)]
pose = inference_top_down_pose_model(model, f, d, format='xyxy')[0]
ret.append(pose)
prog_bar.update()
return ret
def get_list_dimension(lst):
if isinstance(lst, list):
return 1 + (max(map(get_list_dimension, lst)) if lst else 0)
return 0
def main():
args = parse_args()
frame_paths, original_frames = frame_extraction(r'D:\Project\pyskl-main\pyskl-main\demo\ntu_sample.avi',
480)
num_frame = len(frame_paths)
h, w, _ = original_frames[0].shape
print(num_frame)
config = mmcv.Config.fromfile(args.config)
model = init_recognizer(config, args.checkpoint, args.device)
# Load label_map
label_map = [x.strip() for x in open(args.label_map).readlines()]
# Get Human detection results
det_results = detection_inference(args, frame_paths)
torch.cuda.empty_cache()
pose_results = pose_inference(args, frame_paths, det_results)
torch.cuda.empty_cache()
fake_anno = dict(
frame_dir='',
label=-1,
img_shape=(h, w),
original_shape=(h, w),
start_index=0,
modality='Pose',
total_frames=num_frame)
num_person = max([len(x) for x in pose_results])
# Current PoseC3D models are trained on COCO-keypoints (17 keypoints)
num_keypoint = 17
keypoint = np.zeros((num_person, num_frame, num_keypoint, 2),
dtype=np.float16)
keypoint_score = np.zeros((num_person, num_frame, num_keypoint),
dtype=np.float16)
for i, poses in enumerate(pose_results):
for j, pose in enumerate(poses):
pose = pose['keypoints']
keypoint[j, i] = pose[:, :2]
keypoint_score[j, i] = pose[:, 2]
fake_anno['keypoint'] = keypoint
fake_anno['keypoint_score'] = keypoint_score
print(fake_anno)
if fake_anno['keypoint'] is None:
action_label = ''
else:
results = inference_recognizer(model, fake_anno)
action_label = label_map[results[0][0]]
print(action_label)
if __name__ == '__main__':
main()D:\Users\anaconda3\envs\openmmlab\python.exe D:\Project\pyskl-main\pyskl-main\Test\show_inference_recognizer.py
72
load checkpoint from local path: .cache\joint_f6bed715.pth
load checkpoint from http path: https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco-person/faster_rcnn_r50_fpn_1x_coco-person_20201216_175929-d022e227.pth
Performing Human Detection for each frame
[>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>] 72/72, 9.7 task/s, elapsed: 7s, ETA: 0sload checkpoint from http path: https://download.openmmlab.com/mmpose/top_down/hrnet/hrnet_w32_coco_256x192-c78dce93_20200708.pth
Performing Human Pose Estimation for each frame
[>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>] 72/72, 17.2 task/s, elapsed: 4s, ETA: 0s{'frame_dir': '', 'label': -1, 'img_shape': (480, 853), 'original_shape': (480, 853), 'start_index': 0, 'modality': 'Pose', 'total_frames': 72, 'keypoint': array([[[[342.5, 154.2],
[345.2, 148.6],
[337. , 148.6],
...,
[317.5, 331.2],
[370. , 370. ],
[314.8, 381. ]],[[342.8, 155.1],
[345.5, 149.6],
[337.2, 149.6],
...,
[317.8, 331.2],
[370.2, 369.8],
[315. , 380.8]],[[345. , 155.1],
[345. , 149.6],
[339.5, 149.6],
...,
[317.5, 331.2],
[369.8, 369.8],
[314.8, 380.8]],...,
[[408.5, 161.6],
[411.2, 153.5],
[400.5, 159. ],
...,
[330. , 319. ],
[370.5, 370.5],
[316.5, 375.8]],[[408.2, 161.6],
[411. , 153.5],
[400. , 159. ],
...,
[329.5, 319. ],
[370.2, 370.5],
[316. , 376. ]],[[406.8, 161.8],
[409.8, 153.4],
[398.5, 159. ],
...,
[328.2, 319.2],
[370.2, 367. ],
[314. , 375.5]]],
[[[454.8, 139.5],
[460.2, 134. ],
[449.2, 134. ],
...,
[432.5, 316.2],
[463. , 363. ],
[429.8, 365.8]],[[454.8, 138.9],
[460.2, 133.2],
[449.2, 133.2],
...,
[432.5, 317. ],
[463. , 361.5],
[429.8, 367. ]],[[454.8, 138.9],
[460.2, 133.4],
[449.2, 133.4],
...,
[432.5, 315.8],
[463. , 362.5],
[429.8, 368. ]],...,
[[419. , 141.6],
[421.8, 133.5],
[419. , 136.2],
...,
[424.5, 316.2],
[456.8, 369.8],
[429.8, 361.8]],[[418.5, 139.5],
[421.2, 134.1],
[418.5, 136.8],
...,
[424. , 313.5],
[458.8, 369.8],
[429.2, 361.8]],[[418.8, 141.6],
[421.2, 133.5],
[418.8, 136.2],
...,
[424. , 314. ],
[459. , 370.8],
[429.5, 360. ]]]], dtype=float16), 'keypoint_score': array([[[0.971 , 0.9785, 0.9966, ..., 0.845 , 0.9087, 0.8945],
[0.9443, 0.967 , 0.982 , ..., 0.859 , 0.9062, 0.891 ],
[0.929 , 0.941 , 0.9785, ..., 0.848 , 0.906 , 0.8945],
...,
[0.973 , 0.951 , 0.9277, ..., 0.922 , 0.89 , 0.8555],
[0.9663, 0.964 , 0.946 , ..., 0.9194, 0.8877, 0.8594],
[0.93 , 0.9326, 0.975 , ..., 0.919 , 0.867 , 0.8696]],[[0.95 , 0.9697, 0.964 , ..., 0.8745, 0.895 , 0.9233],
[0.9487, 0.981 , 0.9624, ..., 0.857 , 0.8955, 0.912 ],
[0.952 , 0.98 , 0.963 , ..., 0.882 , 0.8833, 0.9155],
...,
[0.9097, 0.8955, 0.78 , ..., 0.856 , 0.891 , 0.895 ],
[0.9136, 0.878 , 0.7773, ..., 0.8677, 0.8887, 0.9023],
[0.9204, 0.882 , 0.7915, ..., 0.878 , 0.879 , 0.9033]]],
dtype=float16)}
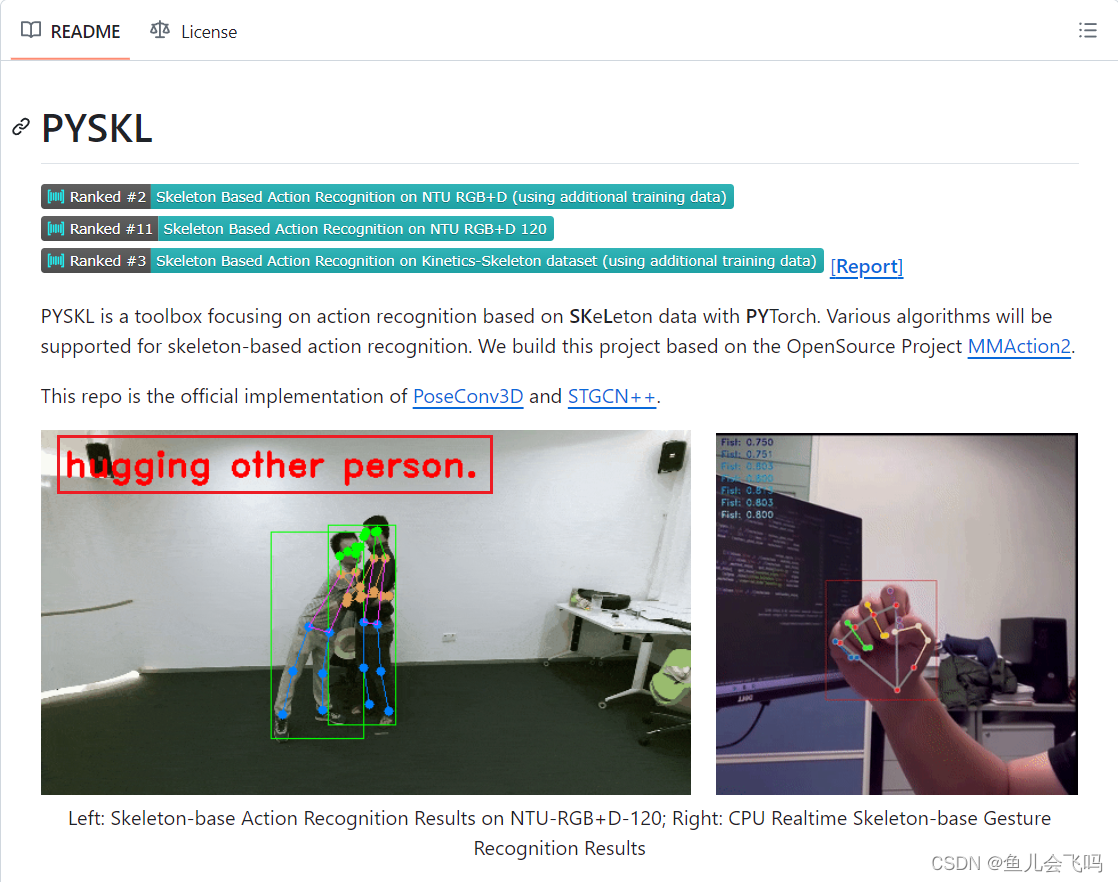
hugging other personProcess finished with exit code 0
发现打印的action_label是hugging other person
说明推理成功
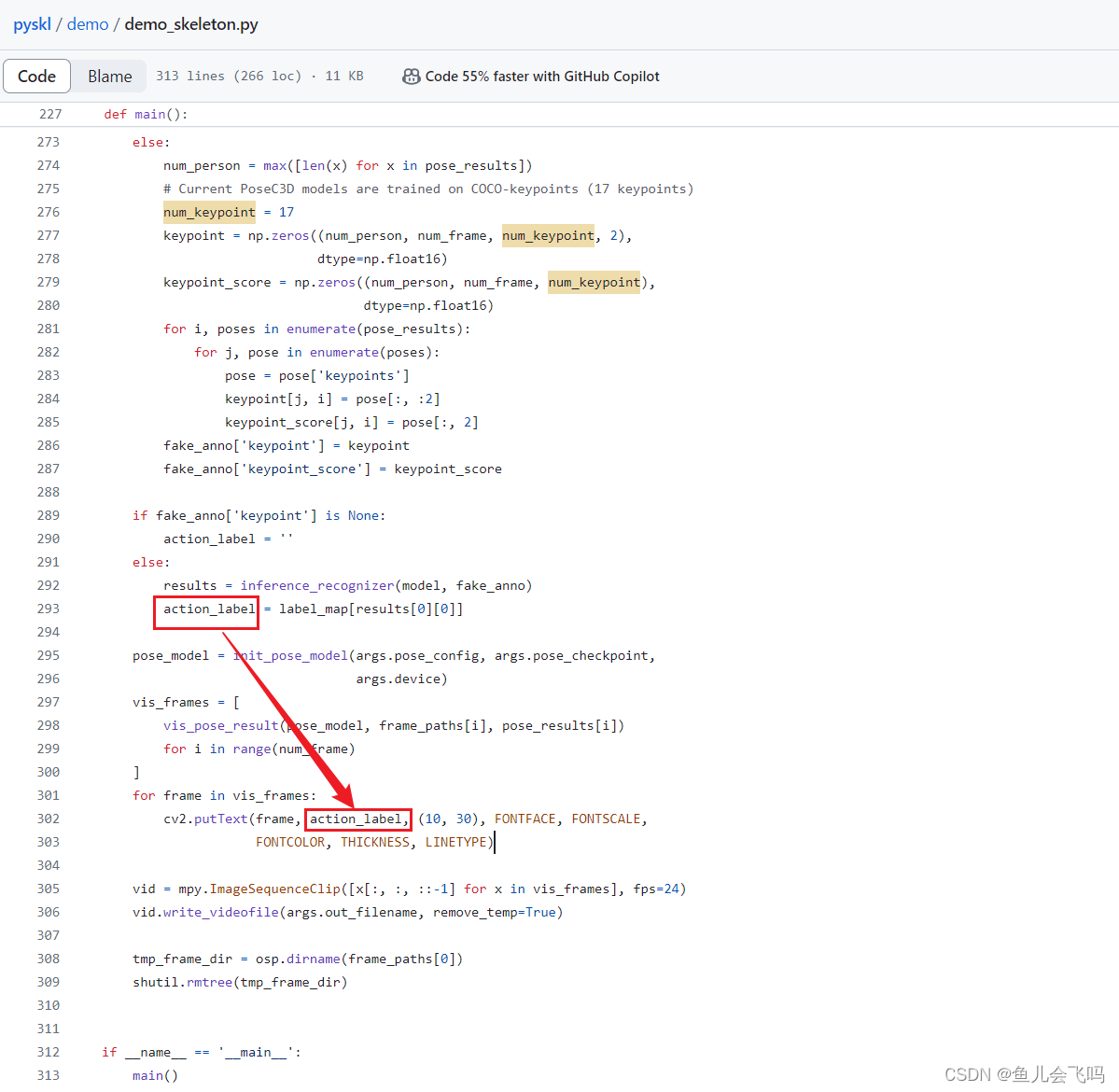
接下来就是把这个推理成功的结果action_label使用cv2.putText函数给添加到每一帧图像里面
https://github.com/kennymckormick/pyskl/tree/06bc11673deda7c50660b273d69e357732296613


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









