









 本文介绍了如何在Spring Boot项目中使用dynamic-datasource-spring-boot-starter引入依赖,并配置多个数据源。涉及entity类、Controller、Service、Mapper及其实现,展示了如何通过@DS注解在Service中切换不同数据库进行操作。最后,通过请求示例验证数据是否成功写入到不同数据库。
本文介绍了如何在Spring Boot项目中使用dynamic-datasource-spring-boot-starter引入依赖,并配置多个数据源。涉及entity类、Controller、Service、Mapper及其实现,展示了如何通过@DS注解在Service中切换不同数据库进行操作。最后,通过请求示例验证数据是否成功写入到不同数据库。
目录
1.项目路径
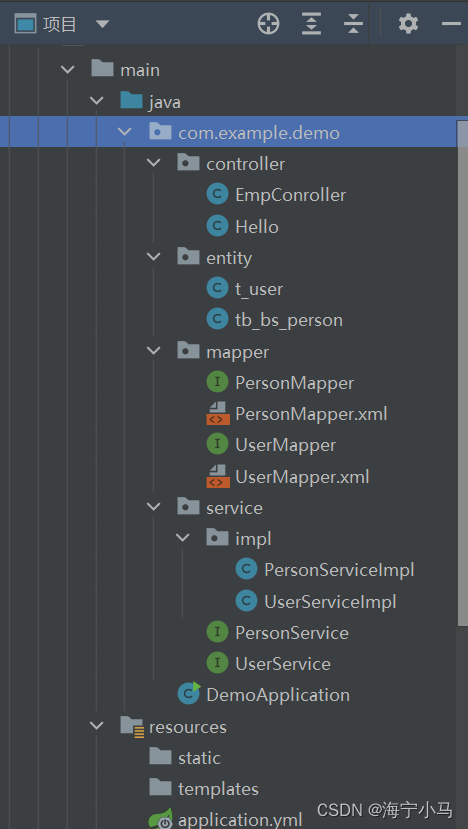
2.pom.xml 引入依赖:
<dependency> <groupId>com.baomidou</groupId> <artifactId>dynamic-datasource-spring-boot-starter</artifactId> <version>3.5.0</version> </dependency>
3.application.yml配置文件:

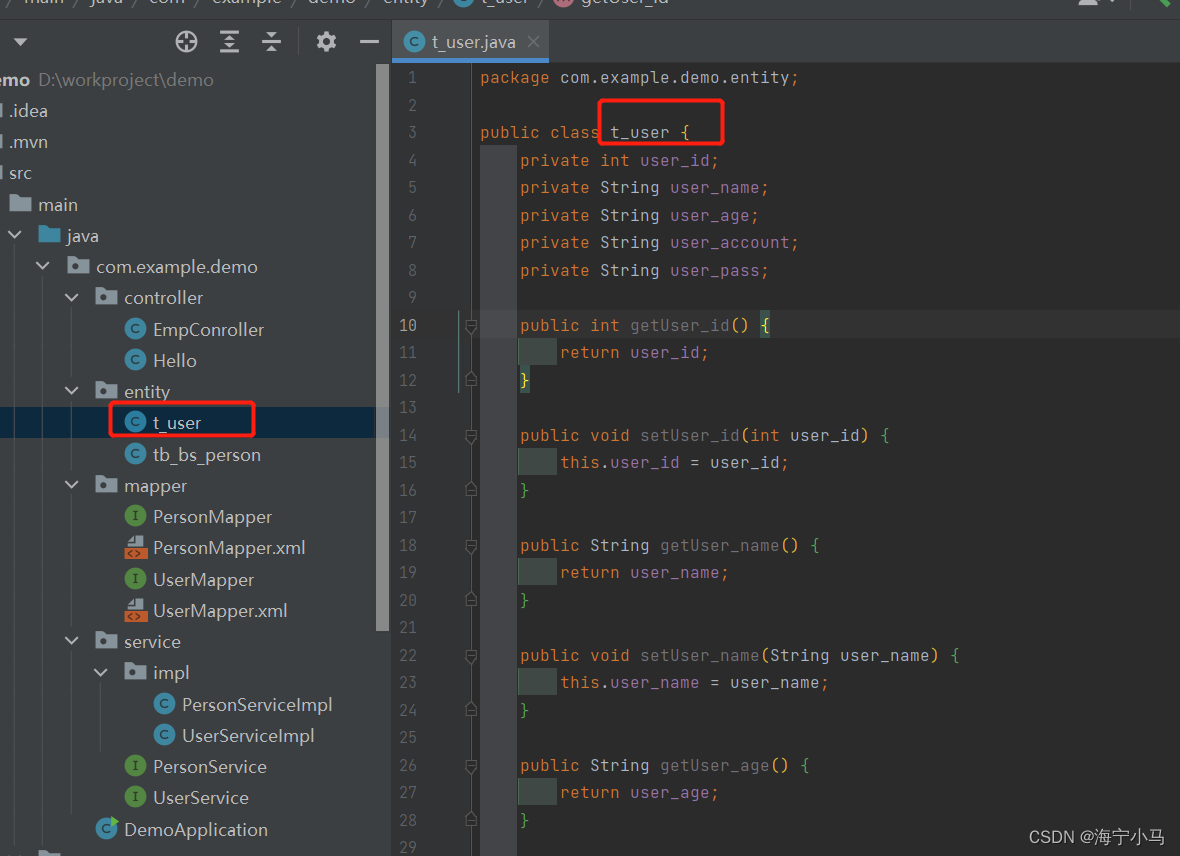
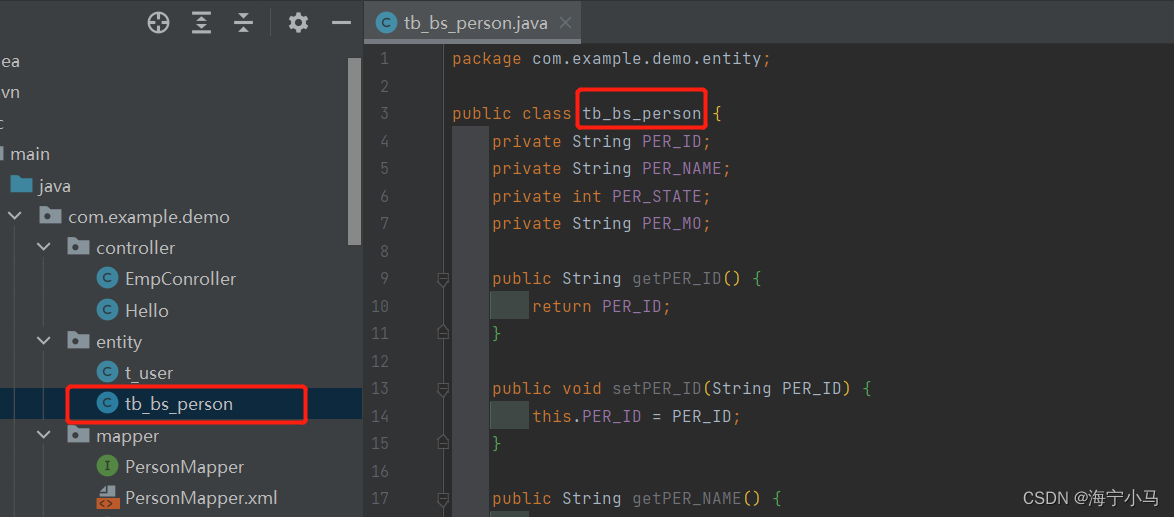
4.两个entity类
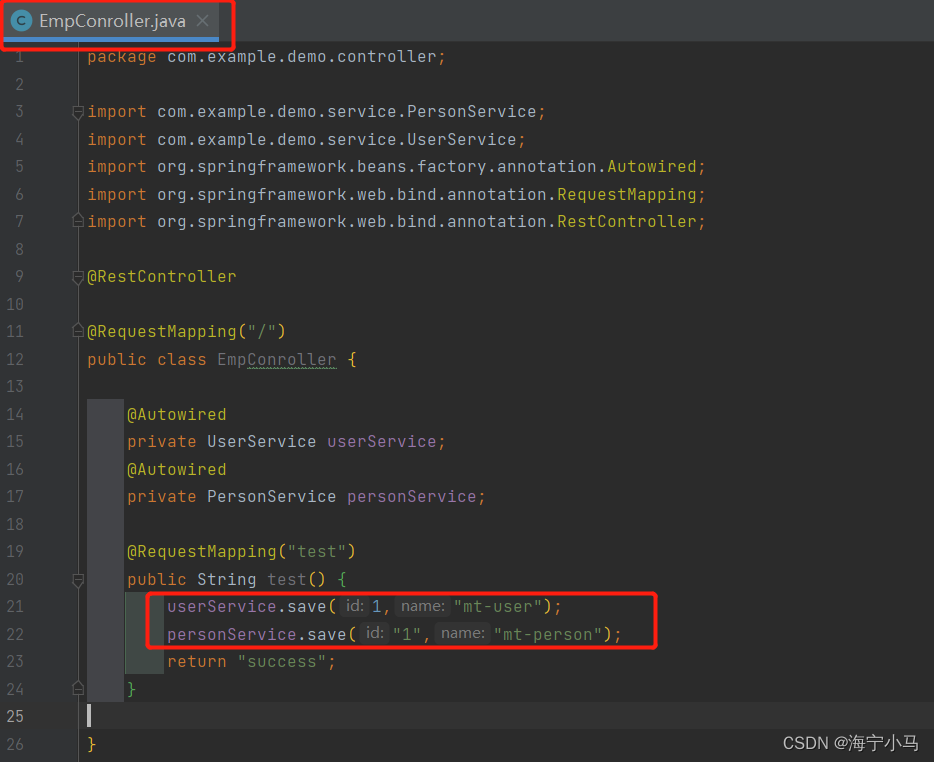
5.Conroller
6.两个Service以及两个ServiceImpl
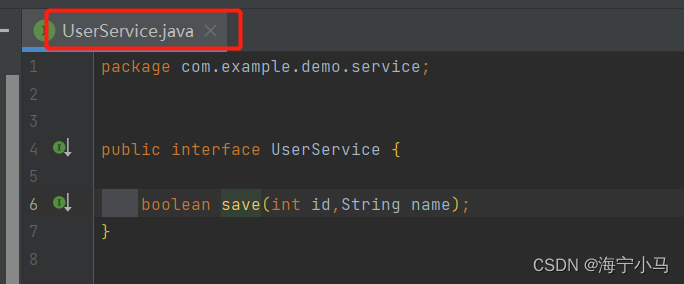
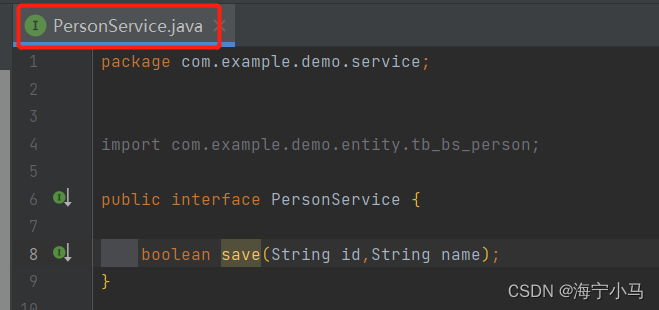
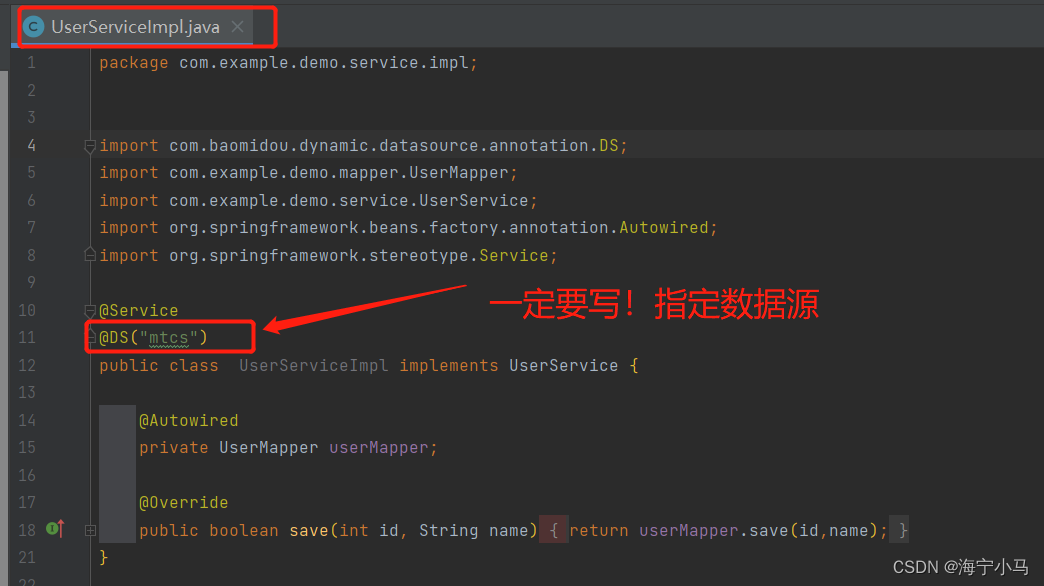
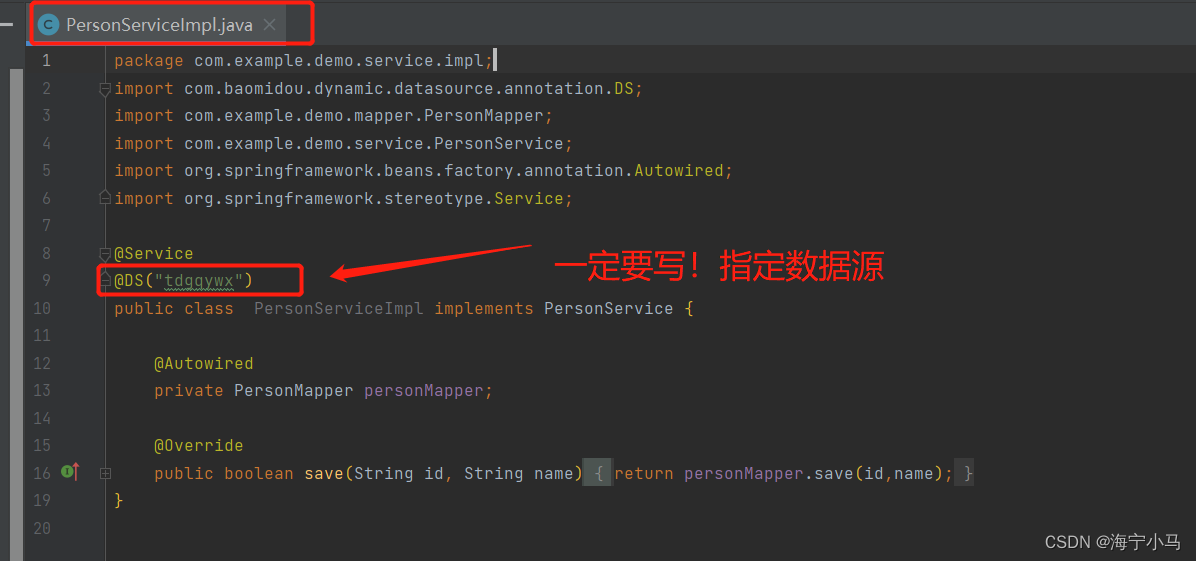
7.两个Mapper及两个Mapper.xml
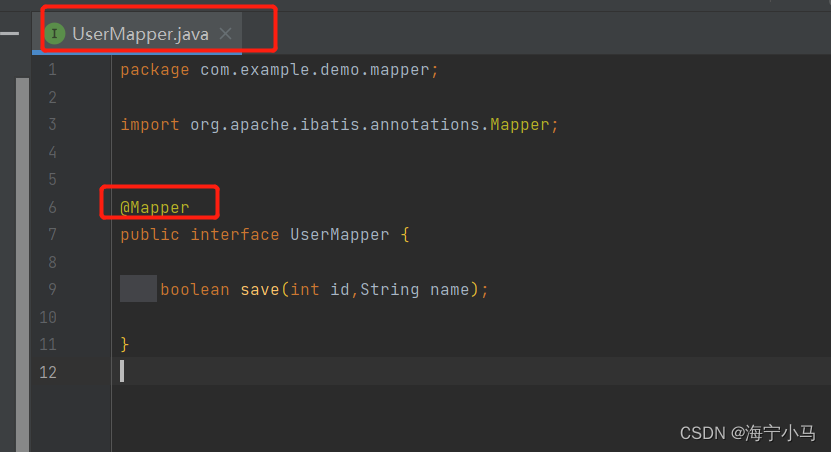
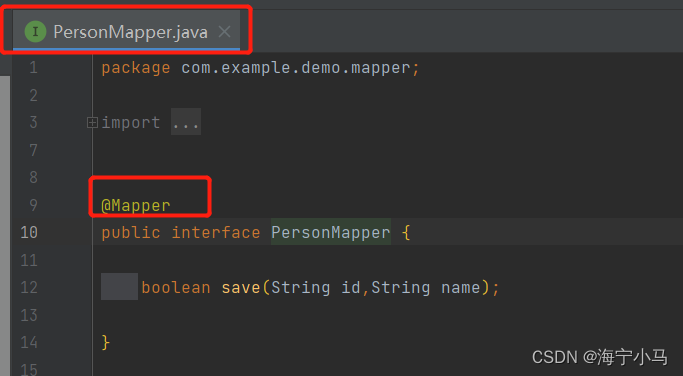
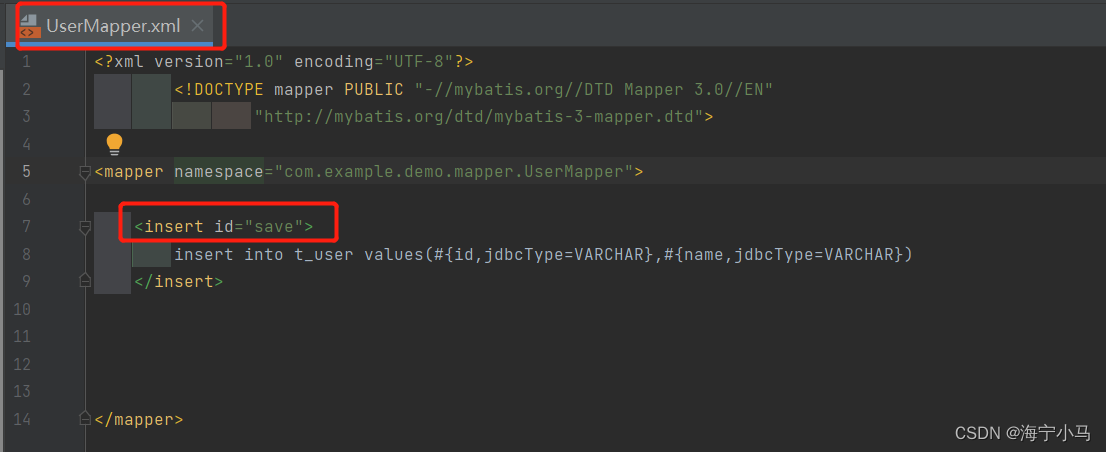
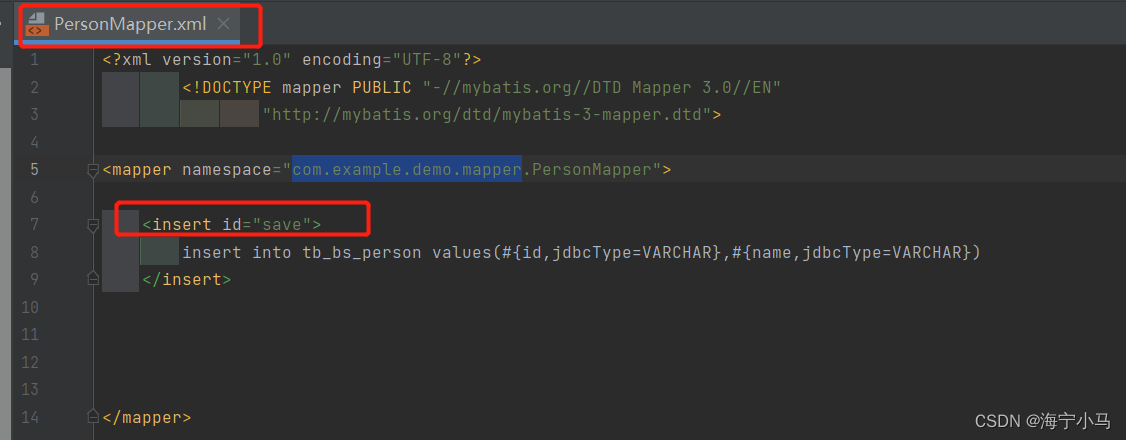
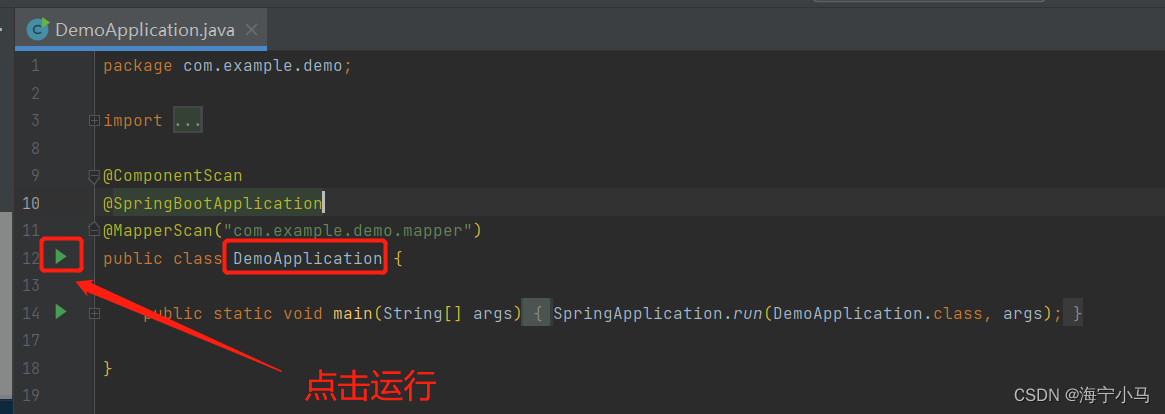
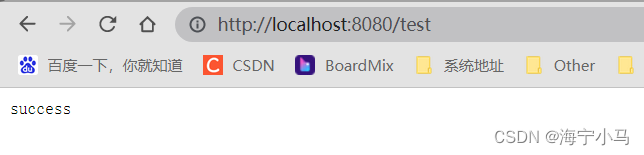
8.运行Application 然后在浏览器请求
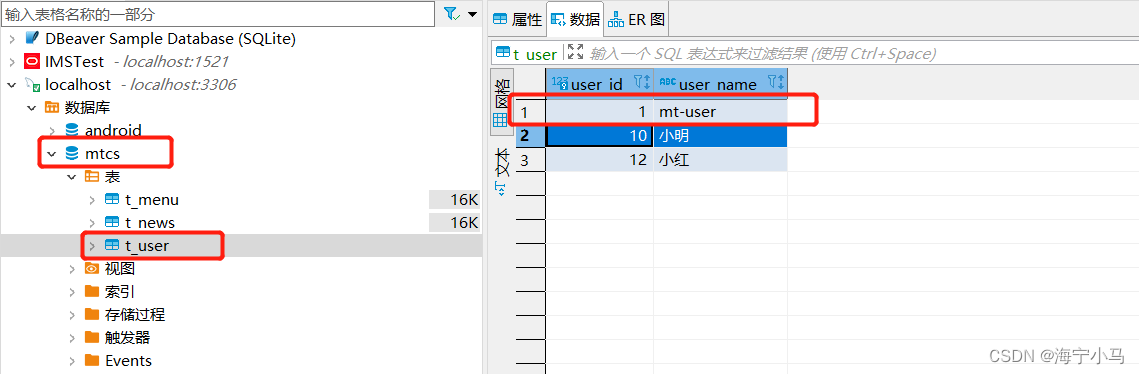
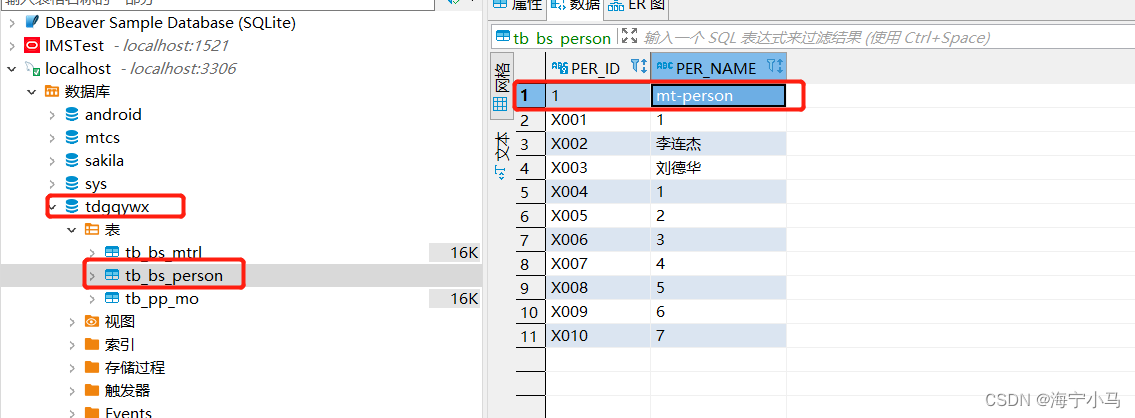
9.查看两个数据库是否有新增数据
总结:
1.pom.xml 引入依赖:dynamic-datasource-spring-boot-starter
2.在application.yml 中配置多个数据源信息(url,username,password等)
3.在service实现类中需要加入@DS注解



















 798
798

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











