







1.简介:Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以收集并处理用户在网站中的所有动作流数据以及物联网设备的采样信息。一般用作系统间解耦、异步通信、削峰填谷等作用。同时Kafka又提供了Kafka streaming插件包实现了实时在线流处理。相比较一些专业的流处理框架不同,Kafka Streaming计算是运行在应用端,具有简单、入门要求低、部署方便等优点。
2.业务场景:
(1)消息队列

kafka消息队列:当短信服务宕机时,用户仍然能够得到注册成功的消息,只是没有短信提示,减少模块之间的耦合。同时使用消息队列异步通信,减少用户等待的时间。

kafka消息队列削峰填谷:当有大量数据产生时,利用kafka消息队列进行缓冲,将数据缓慢的输送给计算服务器或数据库。
(2)kafka Streaming 流处理(应用端)
3.常见的消息队列工作模式:
(1)至多一次:消息生产者将数据写入消息系统,消费者去消费服务器中的消息,当消息被确认消费之后,消息服务器主动删除队列中的数据,这种消费方式一般只允许被一个消费者消费,并且消息队列中的数据不允许被重复消费。
(2)没有限制:生产者发完不同数据之后,该消息可以被多个消费者同时消费,并且同一个消费者可以多次消费消息服务器中的同一个记录,主要是因为消息服务器一般可以长时间存储海量消息。

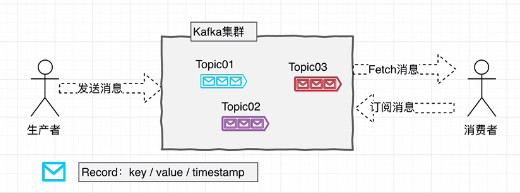
4.kafka集群架构:
kafka集群以Topic形式负责分类集群中的Record(消息),每一个Record属于一个Topic。每一个Topic底层都会对应一组分区的日志用于持久化Topic中的Record。同时在kafka集群中,Topic的每一个日志的分区都一定会有1个Broker(服务,即kafka实例)担当该分区的leader,其他的Broker担当该分区的follower,leader负责分区数据的读写操作,follower负责同步该分区中的数据。这样如果分区的leader宕机,其他的follower会选出新的leader继续负责该分区数据的读写。其中集群中的leader监控和Topic的部分元数据存储在Zookeeper中。

上图所示,Topic有三个分区,生产者发送消息时,用Record中hash(key)%分区数,计算把消息发动到topic的哪个分区中,可以使得record均匀的分散在多个分区中,也可保证同一个消息存放在同一个分区中。Broker0担当了topic中分区0的leader,Broker1和2担当分区0的follower;Broker2担当了topic1中分区1的leader,Broker0和1担当分区1的follower;Broker1担当了topic1中分区2的leader,Broker0和2担当分区2的follower。
当Broker0发生宕机时,分区0的数据将无法进行读写(leader负责读写)。zookeeper集群检测到宕机之后,将在Broker1和2中选取一个作为分区0的leader,例如选中了Broker2,则Broker2将作为分区0和分区1的leader。















 1437
1437











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









