







朴素贝叶斯中文情感分类
1、写在前面
朴素贝叶斯算法理论在很多博客上已经解释的很详细了,本文就不再叙述,本文注重于算法的应用以及编程实现,在读取前人的博客以及他们的项目应用,本人结合书本《机器学习算法原理与编程实践_郑捷》中的贝叶斯算法介绍,将其运用于中文情感分类中,书本中的代码运用了矢量编程,代码块简练易懂,这样也能提高对算法的理解。
本人对贝叶斯分类的理解,简单的概括就是:要想由什么特征属性来判定属于哪种分类,即求
,可以由在这种分类中具有这些特征属性的概率
求得,而
可以通过训练集得到。算法针对中文文本分析,情感分类区别在于特征属性的选择,前者是将所有文本内容的分词去除重复后,得到词典,后者是将情感词作为特征属性,情感词由各大学教授,权威人士在各自研究领域内公布了各自的情感分词库,免费公开(真诚感谢)。中文文本分析的编程实现已在上面提到的书本内完成,因它采取的是Scikit-Learn模块的朴素贝叶斯分类模块,可以进Scikit-Learn官方网站下载朴素贝叶斯分类模块源码学习,也可以自己编写贝叶斯算法类,本人觉得自己编写贝叶斯算法类有利于对算法的理解,在理解后,再采取Scikit-Learn模块进行相应的项目开发。故本人将书本中编写的贝叶斯算法类运用在中文情感分类中,增加对算法的理解。
2、项目实践
本人实现的中文情感分类过程,分为两个部分:(1)训练集数据的准备过程,(2)文本情感分类;
训练集数据的准备过程分为:
(1)文本下载:文本下载的方式有很多,其中高效的方法就是从文本网站上下载各个文章,下载可采取网络爬虫方法,可采取python+scrapy框架的方法对文本网页进行文章自动爬取(链接:https://pan.baidu.com/s/1EJ2QLjw_bEUza5JG9jDSLQ 密码:czuo),共下载文本(497)然后对文本进行分类,语料包括:积极文本(150),消极文本(266),其他的因情感倾向不明显,就不加入训练集。
(2)中文分词,本人将(1)中的文本采取jieba模块进行中文分词(代码在后面贴上)
(3)下载情感词典,链接: http://pan.baidu.com/s/1u12m0 ,来自台湾大学教授免费公布(再次感谢)
将爬虫到的xml文本进行解析以及中文分词,得到语料结构为list[[文本1],[文本2],[文本3]...[文本n]],代码如下:
#xml文件解析# -*- coding: utf-8 -*-
import sys
import os
import jieba
from lxml import etree
class GetCorpus(object):
def savefile(self,path,content):
fp=open(path,"w")
jiebacontent=[]
for word in content.split():
if (word !='[' and word!=']' and word!="'" and word!="'"):
jiebacontent.append(word)
fp.write(str(jiebacontent))
fp.close()
def readfile(self,path):
fp=open(path,"rb")
content=fp.read()
fp.close()
return content
#获取未分词语料
#list xml文件路径,parse_list语料路径
#xml文件内容
def wordparse(self,html):
page_source = etree.HTML(html)
title = page_source.xpath("//tok[@type='group']/tok[@type='atom']/text()")
words=[]
for word in title:
#str(word).replace()
words.append(word)
wordsString=[]
string=""
for word in words:
string+=word
string = string.replace("\n", "")
string = string.replace("\t", "")
wordsString.append(string)
return wordsString#中文文本解析import sys
import os
import jieba
from lxml import etree
from xmlParse import *
import pickle
#dunp 写入
def writedumpobj(path,obj):
file=open(path,"wb")
pickle.dump(obj,file)
file.close()
#dump 读取
def readdumpobj(path):
file=open(path,"rb")
bunch=pickle.load(file)
file.close()
return bunch
def _jieba():
postingList=[]
os.chdir('D:/linguistic-corpus/')
xml_path=r"500trainblogxml/"
#parse_path=r"train_corpus_small/"#parse xml语句解析目录
parse_path = r"train_corpus_seg/"
catelist=os.listdir(xml_path)#xml文件目录路径
cr=GetCorpus()#导入xml文件解析的类
classVec=[]
i=0
for mydir in catelist:
i += 1
class_path=xml_path+mydir+"/"# 分类子目录路径
seg_dir=parse_path+mydir+"/"
if not os.path.exists(seg_dir):
os.makedirs(seg_dir)
file_list=os.listdir(class_path)
for file_path in file_list:
if i==1:
classVec.append(1)#建立类别标签
if i==2:
classVec.append(0)#建立类别标签
fullname=class_path+file_path
content=cr.readfile(fullname)
contentpurse=cr.wordparse(content.decode("utf-8"))
seg_list=jieba.cut(str(contentpurse))
replase_seg_list=" ".join(seg_list).replace("[ '","").replace("' ]","")#删除一些无用字符串
split_seg_list = replase_seg_list.split()
postingList.append(split_seg_list)
writedumpobj("D:\linguistic-corpus\postingList\postingList.dat",postingList) # 写入分词,持久化保存
writedumpobj("D:\linguistic-corpus\postingList\classVec.dat",classVec)#写入分类
print(i)
return postingList
if __name__=="__main__":
postingList=_jieba()训练集准备就绪,以下进行文本分类
import pickle
import numpy as np
def readdumpobj(path):
file=open(path,"rb")
bunch=pickle.load(file)
file.close()
return bunch
def outemotionword(path):
emotionset=[]
with open(path,"rb") as fp:
for word in fp:
if not word.isspace():
word=word.decode("utf-8")
emotionset.append(word.strip())
return emotionset
def loadDataSet(path):#path是为了读入将情感词典
postingList=readdumpobj("D:\linguistic-corpus\postingList\postingList.dat")
classVec=readdumpobj("D:\linguistic-corpus\postingList\classVec.dat")
emotionset=outemotionword(path)
return postingList, classVec,emotionset
class NBayes(object):
def __init__(self):
self.vocabulary = [] # 词典,文本set表
self.idf=0 # 词典的idf权值向量
self.tf=0 # 训练集的权值矩阵
self.tdm=0 # P(x|yi)
self.Pcates = {} # P(yi)--是个类别字典
self.labels=[] # 对应每个文本的分类,是个外部导入的列表[0,1,0,1,0,1]
self.doclength = 0 # 训练集文本数,训练文本长度
self.vocablen = 0 # 词典词长,self.vocabulary长度
self.testset = 0 # 测试集
# 加载训练集并生成词典,以及tf, idf值
def train_set(self,trainset,classVec,emotionset):
self.cate_prob(classVec) # 计算每个分类在数据集中的概率:P(yi)
self.doclength = len(trainset)
tempset = set()
[tempset.add(word) for word in emotionset ] # 生成词典
self.vocabulary = list(tempset)
self.vocablen = len(self.vocabulary)
#self.calc_wordfreq(trainset)
self.calc_tfidf(trainset) # 生成tf-idf权值
self.build_tdm() # 按分类累计向量空间的每维值:P(x|yi)
# 生成 tf-idf
def calc_tfidf(self,trainset):
self.idf = np.zeros([1,self.vocablen])
self.tf = np.zeros([self.doclength,self.vocablen])
for indx in range(self.doclength):
for word in trainset[indx]:
if word in self.vocabulary:
self.tf[indx,self.vocabulary.index(word)] +=1
# 消除不同句长导致的偏差
self.tf[indx] = self.tf[indx]/float(len(trainset[indx]))
for signleword in set(trainset[indx]):
if signleword in self.vocabulary:
self.idf[0,self.vocabulary.index(signleword)] +=1
self.idf = np.log(float(self.doclength)/(self.idf+1))#防止该词语不在语料中,就会导致分母为零
self.tf = np.multiply(self.tf,self.idf) # 矩阵与向量的点乘
# 生成普通的词频向量
def calc_wordfreq(self,trainset):
self.idf = np.zeros([1,self.vocablen]) # 1*词典数
self.tf = np.zeros([self.doclength,self.vocablen]) # 训练集文件数*词典数
for indx in range(self.doclength): # 遍历所有的文本
for word in trainset[indx]: # 遍历文本中的每个词
if word in self.vocabulary:
self.tf[indx,self.vocabulary.index(word)] +=1 # 找到文本的词在字典中的位置+1
for signleword in set(trainset[indx]):
if signleword in self.vocabulary:
self.idf[0,self.vocabulary.index(signleword)] +=1
# 计算每个分类在数据集中的概率:P(yi)
def cate_prob(self,classVec):
self.labels = classVec
labeltemps = set(self.labels) # 获取全部分类
for labeltemp in labeltemps:
# 统计列表中重复的值:self.labels.count(labeltemp)
self.Pcates[labeltemp] = float(self.labels.count(labeltemp))/float(len(self.labels))
#按分类累计向量空间的每维值:P(x|yi)
def build_tdm(self):
self.tdm = np.zeros([len(self.Pcates),self.vocablen]) #类别行*词典列
sumlist = np.zeros([len(self.Pcates),1]) # 统计每个分类的总值
for indx in range(self.doclength):
self.tdm[self.labels[indx]] += self.tf[indx] # 将同一类别的词向量空间值加总
sumlist[self.labels[indx]]= np.sum(self.tdm[self.labels[indx]]) # 统计每个分类的总值--是个标量
self.tdm = self.tdm/sumlist # P(x|yi)
# 测试集映射到当前词典
def map2vocab(self,testdata):
self.testset = np.zeros([1,self.vocablen])
#删除测试集中词不在训练集中
for word in testdata:
if word in self.vocabulary:
self.testset[0,self.vocabulary.index(word)] +=1
# 输出分类类别
def predict(self,testset):
if np.shape(testset)[1] != self.vocablen:
print ("输入错误")
exit(0)
predvalue = 0
predclass = ""
for tdm_vect,keyclass in zip(self.tdm,self.Pcates):
# P(x|yi)P(yi)
temp = np.sum(testset*tdm_vect*self.Pcates[keyclass])
if temp > predvalue:
predvalue = temp
predclass = keyclass
return predclass
if __name__=="__main__":
postingList,classVec,emotionset=loadDataSet("D:\sentiment-word\emotionword.txt")
testset=postingList[119]
nb = NBayes() # 类的实例化
nb.train_set(postingList,classVec,emotionset) # 训练数据集
nb.map2vocab(testset) # 随机选择一个测试句,这里2表示文本中的第三句话,不是脏话,应输出0。
print(nb.predict(nb.testset)) # 输出分类结果0表示消极,1表示积极
print("分类结束")
结合代码,文本情感分类这一部分是算法核心,具体解析过程如下:
重点:文本情感分类有两种加权方法,一种是词频加权,一种是TF-IDF策略,这里重点分析下tf-idf策略以及怎么通过训练集求出,即代码中 def calc_tfidf(self,trainset),def cate_prob(self,classVec)函数的解析
首先了解下如下几个数据结构:
a、idf矩阵:
n为情感词典词的总数,元素
表示情感词编号m在所有文本中出现的次数,注意:如果在一文本中情感词 m 出现了多次,也只算一次。接着将上面的idf数组转化为逆向文件频率。
self.idf = np.log(float(self.doclength)/(self.idf+1))#防止该词语不在语料中,就会导致分母为零。
b、tf矩阵:
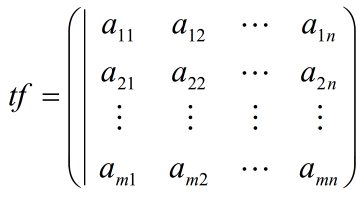
其中,n表示情感词典词的总数,m表示所有文本个数,即创建了一个二维矩阵,矩阵元素表示在文本标号m中,出现标号为n的情感词的词频,接着再将tf消除不同句长导致的偏差。
self.tf[indx] = self.tf[indx]/float(len(trainset[indx]))即将矩阵元素除以标号为m文本的所有单词数
这样tf,idf数组向量求出后再相乘,就得到了TF-IDF权重,将权重再赋予tf矩阵

不得不说,这个策略对文本分类的重要性。
c、tdm矩阵
既然权重得到了,接下来就是求,即

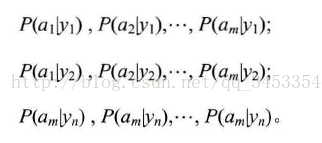
这个概率,本人在捉摸多次后理解如下:
首先,建立tdm矩阵,矩阵行为分类数,在本项目中,行数就为2,列为情感词典个数,为11086,而将tf中属于同一类的行相加,即得到tdm矩阵。
其次,建立sunlist矩阵,行数为分类数,列数为1,其元素是一标量,将tdm的属于同一类的行数元素累加,比如具体点的就是将tdm中是积极类的行数累加,
那么tdm=tdm/sumlista就是,即tdm最终保存的是在一分类中具有这些特征属性的概率。
得到tdm矩阵后,就可以对测试文本进行分类了,首先,必须要将测试文本进行分词,本代码是输入的是直接分词好的。然后将测试集映射到当前词典,得到测试向量testset即情感词典,就是求在测试文本中,各个情感词出现的频数,然后将testset与tdm矩阵相乘,将结果最大的值对应的分类作为这个测试文本的分类。
3、写在后面
一起学习,真诚感谢!















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









