






测试基础
测试计划&测试报告?
测试计划:测试范围、测试策略、测试资源、测试阶段划分、测试阶段日程安排
测试报告:测试环境、bug统计、测试结果分析、结论与建议
购物车:
功能测试:
1)所有页面链接功能正常,可以点击到正确页面
2)从商品详情页添加的商品数据与购物车页面的数据一致
3)若未登陆,点击购物车,则跳转到登陆页面等
4)商品数量与库存的关系:商品数量大于库存数量商品数量小于库存数量商品数量等于库存数量
5)勾选商品后,已选商品的总价显示正确,优惠明细显示正确
6)可以管理商品:包括编辑数量、单个删除、批量删除
7)添加的商品是否有数量上限
界面测试:
页面的布局、按钮、样式是否合理,显示是否完整
兼容性测试:
1)web端兼容性
2)app端兼容性易用性测试
性能测试:
1)多人同时打开购物车页面需要多久
2)多人同时调用添加购物车接口是否会挂
其他:
弱网测试
直播测试?
国内常见的直播协议有RTMP、HLS、HTTP-flv、RTP协议
直播端:采集、美颜处理、编码、推流
服务端处理:转码、录制、截图、鉴别审核
客户端:拉流、解码、渲染
功能:
延迟3s内、声音和画面同步、切换课件视频、退出在进入、互动、发表评论
回放-下载、播放、暂停、快进、快退、倍速、拖拽
网络:
不同网络环境下的播放和加载
设备:
横屏、竖屏
中断测试:
电话、网络、返回中断恢复
被测的直播平台使用开源SRS-Bench
sb_rtmp_publish模拟多路用户并发推流
sb_rtmp_load模拟多路用户并发拉流
推流:
执行sb_rtmp_publish后会打印出每个推流进程并发推流路数threads、成功路数alive、持续时长duration以及读写的流量等指标
服务端可使用netstat命令查看推流连接数
微信支付没有回调?
核实回调地址是否可被外网访问
回调url不能带参数
是否被策略拦截
平台接口问题
利用查单获取订单状态
消息推送?
消息推送对象:全部推送,精确推送,及安卓和IOS渠道推送
消息简介:客户端后台运行一般推送显示在通知栏,客户端前台运行一般弹出弹框,简介内容注意字数过多溢出情况
消息详情:文字、图片、表情包、换行以及链接跳转
消息推送场景:
设置过去时间、未推送之前修改消息内容、删除消息,查看是否还会推送
前台运行、后台运行、进程关闭状态
服务端命令没有下发到客户端?
兼容排查-单机还是多机
基本排查-服务、进程、网络,是否宕机
分别抓包-tcpdump\wireshark
查日志
上传文件测试?
文件格式、文件大小、文件名称、上传成功查看下载删除、批量上传、撤回、弱网、上传病毒木马、取消上传、断点续传
客户端测试、web测试、小程序有哪些区别?
载体:客户端是cs架构和web和小程序是bs架构,一般小程序测试可以直接从微信端打开
系统测试:客户端新旧版本兼容,小程序测试只要更新了服务器端,客户端就会同步会更新
性能:web页面可能只会关注响应时间,app关注流量、电量、CPU、GPU、Memory
兼容性:web浏览器和电脑硬件,app包括安卓ios,pad,小程序是基于微信、微信浏览器
专项测试:app中断测试、2g3g4gwifi网络,小程序入口,授权登录
升级:安装卸载升级
app:手势,home键
权限测试:是否可获取权限,如访问相册、通讯录、照相机等
程序崩溃定位?
加入友盟或者bugly来监听后期线上的运行
崩溃日志
内存泄漏:内存没有释放
内存溢出:使用的内存过多
安全测试?
密码加密-前端、后端
输入框防止sql注入、xss攻击
错误次数限制-防爆破
单点登录、多点登录
异地登录
测试素养&管理
需求评审中提出过什么问题?
流程方面:提前一天发需求,指定上线时间
需求描述是否清晰明了,是否存在歧义或矛盾之处;
是否存在与现有功能或系统冲突的问题;
是否存在未考虑到的使用场景或用户行为;
是否存在需要额外测试或验证的问题;
是否存在安全性、可靠性、性能等方面的问题;
如果项目周期很短,测试人力匮乏,你是怎么协调的?
依据代码review的结果和影响范围,对测试内容进行适当的裁剪。
借助自动化工具的支持,提高测试案例的执行效率。
调整组内任务的优先级,进行人力协调,优先投入最紧要的项目。
加强开发自测,拉取开发交付用例
测试提前进入
必要的情况下加班赶进度
临时改需求加需求?
必须改,根据优先级适当裁剪,或者重新排期
不必须,有时间本次,没有时间或者下次
放弃,时间成本不成本
测试团队分工?
一个迭代需求一个人负责,一个大需求当中拆分某些业务模块几个人负责
测试技术组主要进行工具考研、工具开发和工具维护为业务测试效率提升和基础建设做支撑
业务测试组主要进行具体业务测试和工具的落地使用具体测试内容覆盖功能、性能、兼容、稳定性、接口等
对于团队成员,你是如何打kpi的?
根据团队成员的职级和能力制定合理且细化明确的指标,包含case覆盖率、测试质量保证、测试效率提升、自动化事务、培训分享。
依据KPI的指标达成度、达成时效打分,创新型事务作为加分项。
成员自评和一对一沟通,了解成员的想法
对于老黄牛类型的,吃苦卖力但是没有突破的,给中等绩效
对于老白兔类型的,混吃等死,计划淘汰
对于独狼类型的,抢食,不听指挥的,果断淘汰
对于头狼类型的,吃苦卖力,有惊喜,给优秀绩效
如何保证项目质量?
尽早的了解需求、需求评审、测试准入、接口测试、引入自动化、测试用例覆盖范围、case评审、自动化、线上回归、自动化
如何推进项目进度?
日报或站会同步问题、跟上级或产品或项目经理多沟通、提前评估风险
项目中遇到的问题?
无自动化、用例维护不及时、无文档或者少文档或文档更新不及时
项目中做了哪些贡献?
减少手工测试、流程标准化
职业规划?
尽快适应岗位、融入新团队、提高工作效率
提升专业技能,积累工作经验
在岗位上独当一面,承担更多的责任
无休止的学习新技术应用到项目中、做点贡献
为什么胜任这份工作?
持续学习能力、乐观、工作的热情、适应能力
缺点?
源码阅读的少、强迫症
Linux
docker命令?
docker images 查看镜像列表
docker search ubuntu 搜索镜像
docker pull ubuntu 拉取镜像
docker rmi -f ubuntu 删除镜像
docker ps 容器列表
docker run -it -d --name 要取的别名 -p 宿主机端口:容器端口 -v 宿主机文件存储位置:容器内文件位置 镜像名:Tag /bin/bash
docker stop 容器名 停止容器
docker rm -f 容器名 删除容器
docker exec -it 775c7c9ee1e1 /bin/bash 进入容器
Linux中查找一个文件并且删除它(一条命令)?
find / -name “文件名” | xargs rm -rf
查找文件?
find ./ -type f -size +5M
find . -type f -atime +365
find . -name “*.txt”
查看目录大小?
du -h --max-depth=1 | sort -n
-h:显示K M G信息
–max-depth=1:目录层数
sort -n 排序
df -h 查看磁盘大小
linux合并文件?
合并1,2到3:
cat 1 2 >> 3
追加1到2
cat 1 >> 2
awk?
awk ‘脚本命令’ 文件名
awk ‘/^$/ {print “Blank line”}’ test.txt 打印出文件中的空行
awk ‘{print $1}’ data2.txt 打印第 1 个数据字段
Linux 文件内容大小写转换
cat file | tr a-z A-Z > newfile
awk ‘{print toupper($1)}’ file > newfile
ggguG
服务器之间传文件?
scp 本地文件路径 用户名@远程计算机IP或者计算机名称:远程路径
scp 用户名@本地计算机IP或者计算机名称:远程文件路径 本地路径
断点续传
rsync -avz root@192.168.57.131:/tmp/anaconda-ks.cfg
rsync -avz anaconda-ks.cfg root@192.168.57.131:/tmp/
杀死某一端口号的进程的方法?
(1)netstat -nlp查看占用端口号的服务
netstat -nlp | grep : 3306 查看占用该端口号的服务
(2)找到该端口号的进程
(3)找到该进程id:ps -ef | tomcat
(4)kill它:kill -9 65535
杀死某一进程:
kill -9 PID
查日志?
tail 最后10行
tail -f 实时,最后10行
tail -n +20 输出第20行到文件末尾的内容
tail -n -20 输出倒数第20行到文件末尾的内容
tail -20f -s 5 实时显示file文件的后20行内容,刷新时间为5秒
head
sed -n “开始行,结束行p” 文件名
去除重复行?
cat xx | sort | uniq > data1
统计关键字个数?
gerp “error” xx | wc -l
接口测试
接口测试点?
协议:http、https
header:正向,逆向
请求方式:正向,逆向
参数:
正向-必传、可传、参数值、参数类型
逆向:少传参、多传参、数据类型,参数传参错误,边界值,参数加密
响应:响应码,返回结果,错误处理,响应时间
版本控制:
鉴权:
压测:
接口的安全测试?
加密,token,时间戳,参数签名值,锁定机制,优化错误返回值
状态码?
100 信息,服务器收到请求,需要请求者继续执行操作
200 成功,操作被成功接收并处理
301 适合永久重定向,301比较常用的场景是使用域名跳转
302 用来做临时跳转,比如未登陆的用户访问用户中心重定向到登录页面
304 两次请求返回内容一样
400 请求参数和服务器可以处理的参数不匹配
401 用户没有权限
404 找不到要查询的页面,被删掉或者不存在,url错误、网络
405 请求方式错误
500 服务器错误,服务器在处理请求的过程中发生了错误
502 Bad Gateway 作为网关或者代理工作的服务器尝试执行请求时,从远程服务器接收到了一个无效的响应
504 Gateway Time-out 充当网关或代理的服务器,未及时从远端服务器获取请求
cookie,session,token区别?
cookie由服务器生成发给客户端,不可跨域,存在本地任何人可见可清理
session记录在服务器上,对服务器造成压力,负载均衡的话可能会失效
服务端返回token给客户端,每次请求都会在头里携带,每次请求都会验证
get和post、put请求区别?
1.get请求一般是去取获取数据,post请求一般是去提交数据
2.get因为参数会放在url中,所以隐私性差,有长度限制,post请求没有的长度限制,请求数据是放在body中
3.get请求刷新服务器或者回退没有影响,post请求回退时会重新提交数据请求
4.get请求可以被缓存,post请求不会被缓存
5.get请求只能进行url编码,post请求支持多种
put幂等,类似于更新,post不幂等,类似于新增
get和post发tcp 会分成几个包?
get产生一个数据包,post产生两个数据包
对于get方式的请求,浏览器会把http header和data一并发送出去,服务器响应200 OK,请求成功
对于post方式的请求,浏览器会先发送header,服务器响应100,要求客户端继续发送信息,浏览器再发送data,服务器响应200 OK,请求成功
请求头和响应头?
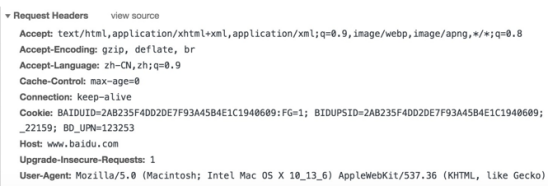
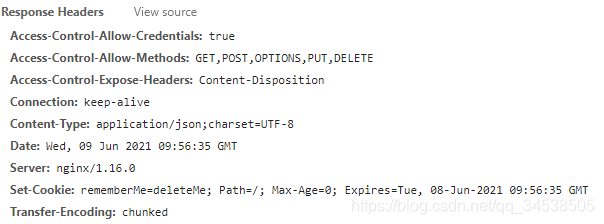
response返回内容?
状态码status_code
返回响应体字符串text
返回响应体字节content
返回响应头headers
请求编码?
Accept:
- application/x-www-form-urlencoded
用于传统表单提交 - multipart/form-data
常用于文件上传 - application/json
前后端分离程序的JSON 字符串 - text/xml
使用 HTTP 作为传输协议,XML 作为编码方式的远程调用规范
上传文件接口测试?
files = {“file”: (“test.xlsx”, open(“D:\test.xlsx”, “rb”), “application/octet-stream”)}
response = requests.post(url=url, headers=headers, files=files, data=data)
下载文件接口测试?
with open(‘x.words’,“wb”) as f
f.write(response.content)
一个接口一直没有返回?
检查url、ip、端口
防火墙、代理、dns解析
检查项目或者服务是否启动
数据库,接口依赖
接口测试用例?

数据库
分布式数据库?
用多机(机器)来横向扩展单机的性能
多机备份、容灾
mysql用的引擎?
InnoDB
InnoDB支持事务,MyISAM不支持
MyISAM适合查询以及插入为主的应用,InnoDB适合频繁修改以及涉及到安全性较高的应用
InnoDB支持外键,MyISAM不支持
索引?
增加分组排序检索数据的速度
查询过程中提高性能
创建和维护索引耗时间,占用物理内存
每次增删改都需要维护索引
主键?
不能重复,不能为空
一张表中最多有一个主键,一般是id
id int unsigned primary key commit ‘xxx’
事务?
数据库事务( transaction)是访问并可能操作各种数据项的一个数据库操作序列,这些操作要么全部执行,要么全部不执行,是一个不可分割的工作单位。事务由事务开始与事务结束之间执行的全部数据库操作组成。
数据一致性怎么保证?
添加事务、锁定、主从复制、
数据库查询第二条?
limit 1,1 --从第2条开始取1条
order by 列 desc limit 1,1 --倒数第二条
limit 10,20 --从第11条开始,取20条,应该是 11~30条
sql通配符?
like:
% 替代0个或多个字符
%英%唐%
_ 仅替代一个字符
英
regexp:
[]表示括号内所列字符中的一个(类似正则表达式)
[王李张]飞 、老[0-9]
[^]表示不在括号所列之内的单个字符
sql?
【删除整个表】
truncate table <表名>
删除表的所有行,但表的结构、列、约束、索引等不会被删除
drop table <表名>
删除表数据和结构
delete from <表名> [where <删除条件>]
删除某一条数据
【增】
insert into <表名> (列名) values (列值)
【改】
update <表名> set <列名=更新值> [where <更新条件>]
【查】
select <列名> from <表名> [where <查询条件表达试>]
【order by】
只排序,配合where
【group by】
聚合函数一起使用,where+group by+having+order by
【having】
对group by的筛选
【举例子】
平均分:
select sid,avg(score) from sc where sid > 10 group by sid having avg(score) > 70;
聚合分组条件排序:
select user_id,sum(payment_fee) as sum FROM t_order where order_code like “YH_2308%”
GROUP BY user_id HAVING sum > 1000 order by sum DESC;
【sql】
查重复数据信息:
首先查重复的字段,分组,计数
select name from emp group by name having count()>=1 # 包含只出现一次的
SELECT DISTINCT(name) FROM emp
然后根据字段查信息
select x,xx,xxx from emp where name in (子查询)
查看学生课程总成绩:
select sum(成绩) as 总分 from 成绩表 group by 学生id order by 总分 desc
查询每科排名前二
SELECT * FROM stuscore A
WHERE
(SELECT COUNT(DISTINCT score) FROM stuscore B WHERE A.subject = B.subject AND B.score>=A.score)<=2
ORDER BY A.score DESC;
【count】
(1) count() 会统计表中的所有的记录数, 包含字段为null 的记录。
“count(1)和count(*)之间没有区别
(2) count(字段) 会统计该字段在表中出现的次数,忽略字段为null 的情况。
【提取json中的字段值】
SELECT JSON_UNQUOTE(JSON_EXTRACT(列名,‘$.字段.字段’)) AS 新列名 FROM 表名
【将查询结果当作一个新表然后计数】
SELECT COUNT(ip) FROM
(SELECT ip FROM soc_operation_log GROUP BY ip HAVING COUNT(ip)>=1) AS tbl2
【查看表DDL】
show create table 表名;
【查看表备注】
show full columns from 表名;
【where和having】
where用于过滤数据行,having过滤分组
where不能用聚合函数,having可以用聚合函数
where在数据分组前过滤,having在数据分组后进行过滤
一次性插入大量数据?
1.一条sql插入多条数据,避免多次与数据库链接
2.添加事务
sql中四种连接查询的区别?
inner join,在两张表进行连接查询时,只保留两张表中完全匹配的结果集
left join,在两张表进行连接查询时,会返回左表所有的行,即使在右表中没有匹配的记录,性能差
right join,在两张表进行连接查询时,会返回右表所有的行,即使在左表中没有匹配的记录
full join,在两张表进行连接查询时,返回左表和右表中所有没有匹配的行
在内连接时on和where的作用是可以认为是一样的
左连接on+and
以左表全匹配进行连接,之后用and筛选,不符合and条件的数据左表保留,右表为null
select * from 左 right join 右 on 左.a = 右.a
跨库查询&双重排序
SELECT *
FROM yiliao_base.t_position_biz_conf AS t1
INNER JOIN yiliao_core.t_hospital_user AS t2 ON t2.user_id = t1.biz_code
WHERE t1.position_code = ‘homePage’
ORDER BY t1.rank ASC,t1.id DESC;
redis?
redis-cli -h host -p port -a password
set name “roc”
get name
del name
ES查询?
GET /person/_search
query: 判断条件。
must
must_not
should 应该
from:起始数据。
size:获取大小。
sort:排序。
aggs:聚合。
服务端
消息中间件:
Kafka-高吞吐量的分布式发布订阅消息系统,系统A发送消息给kafka(消息引擎系统),系统B从kafka中读取A发送的消息
Rmq-消息队列
Web服务器中间件:
Tomcat-javaweb服务
nginx-反向代理、负载
缓存中间件:
redis-消息代理、实时数据
日志中间件:
ES-存储大量非结构化数据,日志数据
对称加密和非对称加密?
对称加密:AES
非对称加密:RSA
1.对称加密加密与解密使用的是同样的密钥,所以速度快,但由于需要将密钥在网络传输,所以安全性不高。
2.非对称加密使用了一对密钥,公钥与私钥,所以安全性高,但加密与解密速度慢。
3.解决的办法是将对称加密的密钥使用非对称加密的公钥进行加密,然后发送出去,接收方使用私钥进行解密得到对称加密的密钥,然后双方可以使用对称加密来进行沟通
内存泄漏和内存溢出?
内存溢出(out of memory),指应用系统中存在无法回收的内存或使用的内存过多,最终使得程序运行要用到的内存大于能提供的最大内存
内存泄露(memory leak),指程序中已动态分配的堆内存由于某种原因程序未释放或无法释放,造成系统内存的浪费,导致程序运行速度减慢甚至系统崩溃等严重后果
进程与线程的区别?
线程是程序执行的最小单位,而进程是操作系统分配资源的最小单位
一个进程由一个或多个线程组成
进程之间相互独立,但同一进程下的各个线程之间共享程序的内存空间
微服务测试?
RocketMQ?
阿里下的开源产品,用在电商场景比较多,Java开发的,低延时,非常适合在线业务
Producer:生产者,负责生产消息
Broker:消息存储,提供了消息的接收、存储、拉取等功能
Comsumer:消费者,负责消费消息
Topic:生产者发布消息到MQ,需要指定一个Topic,消费者也需要指定具体是监听哪个Topic的消息,当该topic有消息就会进行消费
测试?
消费主流程是正常的
消息丢失
消息避免重复发送
消费积压
消费顺序
负载均衡?
轮询-适用于性能接近
最小连接数-适用于长连接
最小响应时间-适用于对响应时间要求较高
IP哈希-适用于会话保持
加权轮询-适用于性能不一样
网络基础
OCI七层模型?
应用层:用户与网络之间的接口
HTTP FTP TFTP SMTP SNMP DNS TELNET HTTPS POP3 DHCP
表示层:提供应用层数据的公共表示,即统一数据格式
LPP
会话层:应用程序之间建立、维持和中断会话
LDAP
传输层:负责数据传输时端到端的完整性
TCP\UDP、端口
网络层:数据从一个结点到另一个结点的传输
IP、ARP
数据链路层:负责信息从一个结点到另一人结点的物理传输
STP、WIFI
物理层:在物理传输介质上发送和接收数据位,为数据链路层提供物理连接
在浏览器地址栏中输入www.baidu.com到看到百度首页,这个过程中间经历了什么?
1.浏览器获取用户在地址栏输入的域名。
2.浏览器将域名发送给DNS域名系统解析。
3.DNS解析域名得到相应的IP,返回给浏览器。
4.浏览器根据IP向服务器发起TCP三次握手,建立TCP连接。
5.浏览器向服务器发送HTTP请求。
6.服务器通过HTTP响应向浏览器返回数据。
7.释放TCP连接。
8.浏览器解析数据,经行渲染。
HTTP1.0\2.0\3.0区别?
http1.0:有访问数量限制
http2.0:多路复用
http3.0:基于UDP协议
TCP与UDP区别总结?
1、TCP面向连接(如打电话要先拨号建立连接);UDP是无连接的,即发送数据之前不需要建立连接
2、TCP提供可靠的服务。也就是说,通过TCP连接传送的数据,无差错,不丢失,不重复,且按序到达;UDP尽最大努力交付,即不保证可靠交付
3、TCP面向字节流,实际上是TCP把数据看成一连串无结构的字节流;UDP是面向报文的
UDP没有拥塞控制,因此网络出现拥塞不会使源主机的发送速率降低(对实时应用很有用,如IP电话,实时视频会议等)
4、每一条TCP连接只能是点到点的;UDP支持一对一,一对多,多对一和多对多的交互通信
5、TCP首部开销20字节;UDP的首部开销小,只有8个字节
6、TCP的逻辑通信信道是全双工的可靠信道,UDP则是不可靠信道
TCP如何保证可靠性?
校验和:TCP 将保持它首部和数据的检验和
序列号:TCP 传输时将每个字节的数据都进行了编号
确认应答:ACK 报文
超时重传、连接管理、流量控制、拥塞控制
网络传输协议?
常见协议有:Telnet、FTP、SMTP、HTTP、DNS等
经典bug
比如6月1日进行了一次备份,7月1日进行了一次备份
恢复到6月1日,记录表只有6月1日及之前的数据,没有7月1日的…
结论:
数据备份本身的表不能进行备份和恢复
jmeter
正则:
(“token”:“83EEAA887F1D2F1AA1CDA9E197810992”,“sex”:“女”,“userName”:“12548650”)
左边界(.+?)右边界
1、提取单个变量
“token”:“(.+?)”,“sex”😦.+?),“userName”
模板:
1
1
1,匹配数字:1 提取正则表达式中的第一个(.?)所匹配的内容
83EEAA887F1D2F1AA1CDA9E197810992
模板:
0
0
0,匹配数字:1 提取正则表达式所有的部分
“token”:“83EEAA887F1D2F1AA1CDA9E197810992”,“sex”:“女”,“userName”
模板:
2
2
2,匹配数字:1 提取正则表达式中的第二个(.?)所匹配的内容
女
模板:
3
3
3,匹配数字:1 提取缺省值中输入的数据
模板:
1
1
1
2
2
2 ,匹配数字:1 把2个()所匹配的内容拼接起来
83EEAA887F1D2F1AA1CDA9E197810992女
2、提取多个变量
“sex”:“女”,“userName”:“12548650”
引用名称:MYREF
模板:
1
1
1
2
2
2
调用:
M
Y
R
E
F
g
1
{MYREF_g1}
MYREFg1{MYREF_g2}
3、提取所有小数,如10.2
([0-9]+.[0-9]+)
模板:
0
0
0
a
a
1
{aa_1}
aa1{aa_2}
4、提取所有小数后面的数字,如10.2的2
([0-9]+).([0-9]+)
模板:
2
2
2(第二组变量)
a
a
1
{aa_1}
aa1{aa_2}
监控:
监听器 - jp@gc - PerfMon Metrics Collector
serveragent
运行startAgent.bat
参数化?
User Parameters
CSV Data
User Defined Variables
FunctionHelper中的函数
生成随机数方法?
函数助手
用BeanShell后置处理程序写脚本
聚合报告?
请求名称、请求次数、平均值、中位数(50%用户的响应时间小于该值)、90%、95%、99%、min、max、异常%、吞吐量(qps)、接收kb/s、发送kb/s
自动化
接口自动化框架工具?
Python+pytest+requests+yaml/excel+alluer
UI自动化框架工具?
Python+pytest+selenium+html
小程序自动化框架工具?
Python+minium
分层?
测试数据目录
公共方法
测试用例目录
测试报告存放目录
pytest优点?
前置后置
conftest.py
@pytest.fixture(scope=“session”)
yield
引用前置函数
@pytest.mark.usefixtures(“init_data”)
参数化
@pytest.mark.parametrize() 装饰器接收两个参数:
第一个参数以字符串的形式存在,它代表能被被测试函数所能接受的参数,如果被测试函数有多个参数,则以逗号分隔;
第二个参数用于保存测试数据。如果只有一组数据,以列表的形式存在,如果有多组数据,以列表嵌套元组的形式存在(例如:[1,1]或者[(1,1), (2,2)])
import pytest
@pytest.mark.parametrize(“data, code”, [(“data1”, 200), (“data2”, 500)])
def test_equal(number):
res = requests.post(url, json = data, headers=headers)
codes = res[‘data’][‘code’]
assert codes == code
if name == “main”:
pytest.main([])
插件
pytest插件?
@pytest.mark.dependency(depends=[“TestCase::test_01”]) 用例依赖
@pytest.mark.skip 打标记
@pytest.mark.flaky(reruns=重新执行最大次数, reruns_delay=执行间隔时间(秒)) 失败重跑,装饰器或者命令行
@pytest.mark.run(order=执行顺序) 执行顺序
pytest.assume() 断言失败仍会执行至用例结束
@pytest.mark.xfail(reason=“预期失败”) 预期失败
打标记
@pytest.mark.skip 打标记
测试报告优化
allure
提取参数?
from jsonpath import jsonpath
data = json.loads(data)
token = jsonpath(res,‘&.data[1].token’)[0] # 返回一个列表
selenium系统等待、显式等待、隐式等待?
强制等待:
time.sleep(3)
显式:元素出现就执行
from selenium.webdriver.support.wait import WebDriverWait
隐式:元素出现还是会等待时间
driver.implicitly_wait(30)
UI自动化操作?
webdriver
driver = webdriver.Chrome() 打开浏览器
driver.maximize_window()
driver.get(url)
driver.quit()
webdriverwait().until 等待
switch_to.alart 切换弹窗
accept() 弹窗操作
switch_to_window(list[1]) 切换窗口
get_attribute 获取元素属性
截图:save_screenshot
get_screenshot_as_file
actionchains 动作链
验证码解决方案?
第三方库,智能识别
万能验证码
debug模式
数据库
pytest返回值?
Exit code 0 所有用例执行完毕,全部通过
Exit code 1 所有用例执行完毕,存在Failed的测试用例
Exit code 2 用户中断了测试的执行
Exit code 3 测试执行过程发生了内部错误
Exit code 4 pytest 命令行使用错误
Exit code 5 未采集到可用测试用例文件
pytest运行命令?
pytest 目录 运行目录或目录下的文件
pytest -vs 详细信息 -q 精简信息
–html=report.html 输出测试报告
-k “MyClass and not met” 运行指定文件
-m “smoke” 运行标记
-n 2 多进程
pytest运行原理?
收集测试文件和测试函数
加载到内存中
执行函数
统计测试结果并输出测试报告
如何开展自动化工作?
1、熟悉需求
需求文档、手工测试、产品、测试
项目阶段、棘手的问题
2、分析
哪些模块适合哪些不适合
稳定性、功能复杂性、核心模块、bug量、开会讨论
筛选模块
3、功能测试
筛选核心功能核心接口、主流程、主功能点,评审
4、自动化计划
框架选型、人员、定规范、时间规划
规划:覆盖率
自动化切入点&困难?
切入点:
测试准入、集成测试、线上回归
困难:
接口文档的管理 – 抓包理解业务或者向开发询问接口字段含义,如果没有证明项目推进有问题
case维护困难 – 涉及到多人协同开发
前端改动大、频繁、不规范导致元素不好定位
刚开始时框架不统一、编码规范
Jenkins&svn&git
运行
java -jar jenkins.war
使用变量
${} 或者 $
String Parameter 字符串
Choice Parameter 字符串列表
Boolean Parameter 对应的字符值为’true’或者’false’
File Parameter 上传文件
定时脚本
config-定时构建
日程表依次是 分钟 小时 日 月 星期
*(星号):表示每,每分钟,每小时,每天,每月,每星期
, (逗号):表示指定列表范围。
-(横短线):表示区间范围
30 15 * * * 每天下午3点30分定时执行脚本
30 15 * * 2,4,6 每周2,4,6下午3点30分定时执行脚本
0 8-10 * * * 8到10点整每小时执行一次
0 22 */1 * * 每一天在22点执行一次
SVN检出
svn提交
svn更新
git init 当前目录初始化仓库
git clone 【url】 克隆仓库
git branch -a 列出所有分支
git branch 【dev】 以当前分支为起点创建一个分支
git checkout [dev] 创建分支
git checkout -b 【dev】 创建并切换
git branch -d [dev] 删除完全合并的分支,-D 强制删除
git pull
git add .
git commit . -m “”
将dev合并到test?
切换到dev分支,commit并push
切换到test并pull
选择dev分支merge into当前(git merge dev)
test分支push到远端
python基础
python数据类型?

json和字典的区别?
json的类型是字符串,字典的类型是dict
json的key只能是字符串,dict的key可以是任何可hash的对象,例如:字符串、数字、元组等
json的key可以是有序、重复的,dict的key不可重复
dict 字符串用单引号、双引号,json强制规定双引
json访问方式可以是[],也可以是.,遍历方式分in,of; dict的value仅仅可以下标访问
*args、**kwargs区别?
*args 将所有参数以元组(tuple)的形式导入
**kwargs 将参数以字典的形式导入
sort和sorted区别?
用法:
a.sort() 重新返回a
sorted(a) 返回新的list
内置函数?
abs、max、min、round(小数点四舍五入)、sum、bool、int、float、complex、str、bytes、list、tuple、type、len、print、input、open
第三方库?
requests、pytest、pymysql、selenium、openpyxl、flask、Scrapy、
深拷贝和浅拷贝?
浅拷贝,是重新分配一块内存,创建一个新的对象,但里面的元素是原对象中各个子对象的引用。
深拷贝,是重新分配一块内存,创建一个新的对象,并且将原对象中的元素,以递归的方式,通过创建新的子对象拷贝到新对象中。因此,新对象和原对象没有任何关联。
类的属性和方法?
私有属性:
def init(self,year,month,day):
self.year=year
self.month=month
self.day=day
静态属性:
@property
封装一个属性, 不用加括号就可以调用
静态方法:
@staticmethod
可以供类和实例调用
类方法
@classmethod
第一个参数必须是类对象,一般以cls作为第一个参数,能够通过实例对象和类对象去访问
语法?
列表转字典?
1
list_key = [“a”, “b”, “c”, “d”, “c”]
list_value = [1, 2, 3, 4, 5]
dict = {}
for i in range(len(list_key)):
dict[list_key[i]] = list_value[i]
print(dict)
2
dict(zip(list_key, list_value))
3
list2 = [[‘key1’,‘value1’],[‘key2’,‘value2’],[‘key3’,‘value3’]]
print(dict(list2))
4
dict={‘name’:‘wsm’, ‘age’:‘22’, ‘sex’:‘female’}
print(list(dict.keys()))
print(list(dict.values()))
print(list(dict.items()))
数字交换?
a = 1
b = 2
1
b, a = a, b
2
c = a
a = b
b = c
3
a = a + b
b = a - b
a = a - b
列表去重?
ids = [1, 2, 2, 3, 3, 3, 4, 4, 4, 4, 4, 5]
“”“for循环”“”
id = []
for i in ids:
if i not in id:
id.append(i)
“”“count函数、del函数”“”
for i in ids:
while ids.count(i) > 1:
del ids[ids.index(i)]
“”“内置函数set”“”
print(list(set(ids)))
list相加?
for循环
list1+list2
list1.extend(list2)
L1[len(L1):len(L2)] = L2
多线程?
threading模块
普通创建方式:
t1 = threading.Thread(target=run, args=(“t1”,))
t1.start()
自定义线程:
class MyThread(threading.Thread):
def run(self):
t1 = MyThread(“t1”)
守护线程:
setDaemon(True)
当主进程结束后,子线程也会随之结束
主线程等待子线程结束:
join(timeout=None)
字典转字符串?
json.dumps()
装饰器、生成器、迭代器?
@函数装饰器:
def func1(func):
func()
@func1
def func2(): # 等价于func1(func2)
yield生成器:
异步执行,如关闭浏览器、清理数据
iter迭代器:
1.使用iter()方法创建迭代器
2.使用next()函数进行迭代
3.当迭代元素用尽时会抛出 StopIteration 异常
性能测试
性能测试流程?
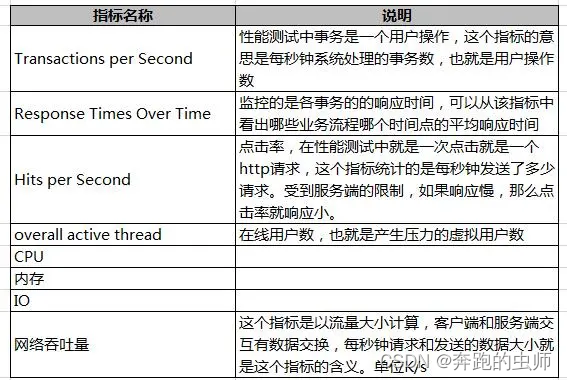
1.性能需求分析:明确吞吐量、TPS、QPS、响应时间258、事务成功率
2.设计模型:登录用户、并发方式、业务、是否退出
3.准备测试环境、测试机、服务器
4.监控:CPU、内存、磁盘IO、网络带宽
5.分析数据、调优
调优?
代码调优
操作系统
数据库
存储-mysql\es
中间件
消息队列
网络
常见问题?
加压之后流量没有上去:
网络带宽
代码层次-缓存、堆积
错误
1、CPU飙升:
top 查看pid - 查看pid进程日志
大数据的正则、数据库写入死锁
2、CPU正常,偶发耗时高:
GC耗时-垃圾回收
3、内存增长:
第三方插件内存泄漏
4、指标正常,响应耗时久:
大量打印日志
5、并发测试前期良好,越往后越差:
数据量增长影响性能
没有分页
6、上游正常、下游打崩:
循环请求
压测中token失效?
1.避免手写token,通过登录去提取token值-json提取器,beanshell后置处理器添加全局变量
2.一个用户的话可以用setup线程组,多个用户用仅一次控制器,csv文件
3.单独写一个线程组拿token,设置测试活动
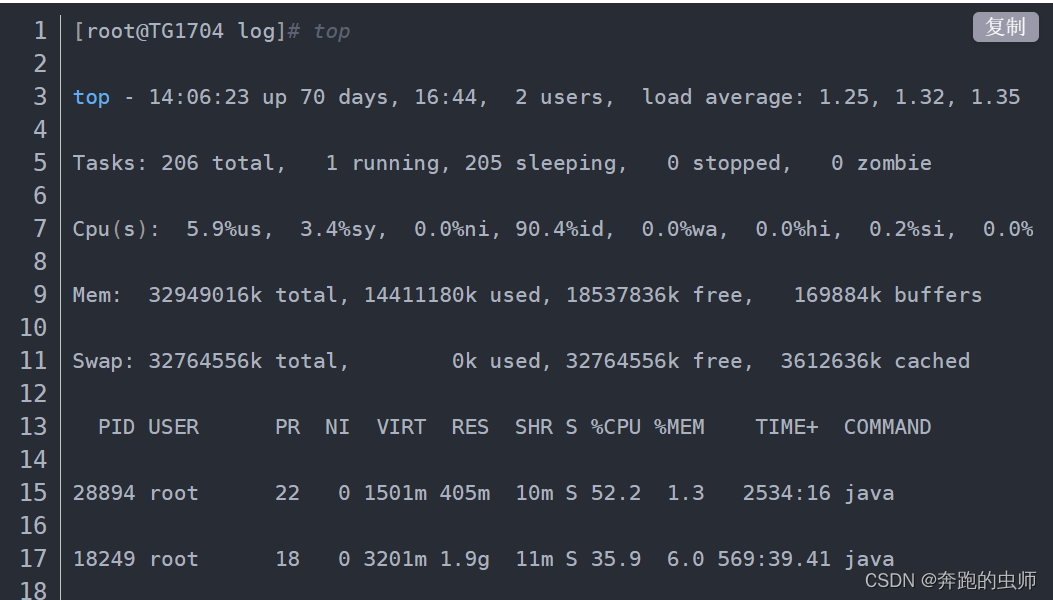
性能监控?
top P cpu
top M 内存
top 1 各颗CPU占用情况
free -m 内存,单位是m

df -h 磁盘
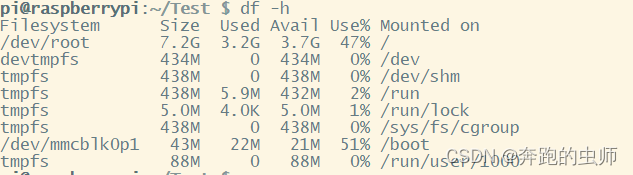
iostat -d 1 查看各个磁盘IO
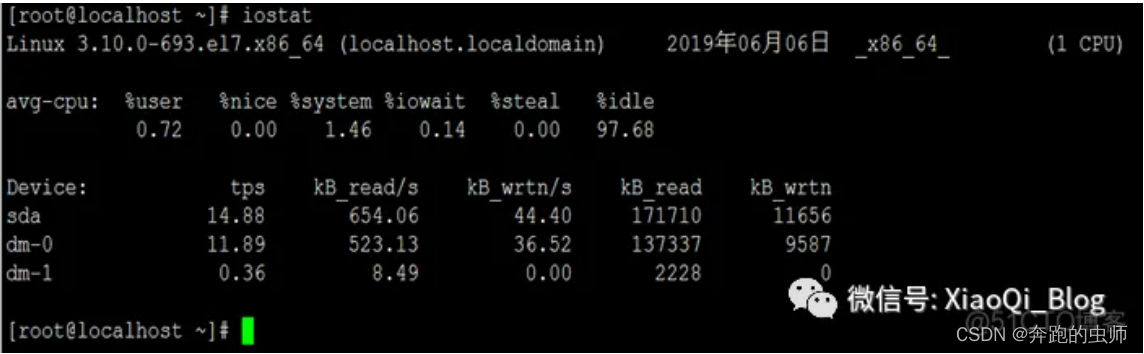
pidstat -d 1 查看进程占用
select * from information_schema.processlist where command !=‘sleep’; 查看数据库会话列表
vmstat 3 10 以3秒为时间间隔,连续收集10次性能数据swpd(已经使用)、free、buff、cache、si和so
procs -----------memory---------- —swap-- -----io---- -system-- ----cpu----
r b swpd free buff cache si so bi bo in cs us sy id wa
2 0 79496 1614120 139240 787928 0 0 23 10 0 0 1 1 1 88 0
swpd:使用的虚拟内存量。
free:空闲内存量。
buff:用作缓冲区的内存量。
cache:用作高速缓存的内存量。
si:从磁盘交换的内存量(换入,从 swap 移到实际内存的内存)。
so:交换到磁盘的内存量(换出,从实际内存移动到 swap 的内存)
iftop -i eth0 查看网络带宽
分布式压测?
一台控制机,其余是负载机
master:
jmeter.properties文件,remote_hosts配置上slave端的IP,多个slave地址用逗号分隔;
Master上已上传脚本文件和参数化文件;
Djava.rmi.server.hostname=http://xxx.xxx.xxx.xxx,将这里设置为master机器的ip地址
slave:
jmeter.properties文件,server.rmi.ssl.disable=true;
jmeter4.0以上才需要修改,4.0以下没有这个字段值;
Slave上参数化文件要放在jmeter的bin目录下
执行:
控制机会把脚本发送到每个负载机上,负载机获取到脚本就执行脚本(负载机只需要启动jmeter-server.bat或者jmeter-server)
负载机回传执行结果给控制机,控制机会进行汇总
jmeter -n -t 脚本绝对路径名.jmx -l 要保存的结果绝对路径名.jtl -R 192.168.199.199:1099,192.168.149.223:1099
app性能测试?
Xcode instruments
perfDog
响应:冷启动、热启动
adb shell am start -W packageName/ActivityName(绝对路径,首个Activity)
内存:空闲时间、某个操作、释放
adb shell dumpsys meminfo packageName
CPU:空闲、某个操作、释放
adb shell dumpsys cpuinfo |grep packageName
FPS:每一帧的时间不超过1000/60=16.6ms,这就是16ms的黄金准则
adb shell dumpsys gfxinfo packageName
GPU:在一个像素点上绘制多次,深红:绘制四次 (必须优化)
手机自动的Debug GPU overdraw
耗电量:安装前后待机、长时间使用
adb shell dumpsys batterystats |grep packageName
大数据
大数据怎么测试准确性?
单条、几条、抽样、数量、
数据链路?
数据采集:从业务系统采集数据日志,通过网络协议、用户行为等
数据存储:存储到大数据的系统,ES检索、kafka消息队列
数据清洗:对一些数据进行清洗和转换,比如加或者过滤日志头
数据建模:存表
数据计算:数据接口
数据展示:报表、大屏
大数据测试?
数据本身的完整性总量、准确性、及时性
大数据系统或应用产品的web、接口、性能
特殊场景的容灾、备份、恢复、分库分表
区别?
数据体量、sql能力、测试效率低、测试环境、数据验收
异常场景?
数据飘逸:在双11当天的23:59:59时有大量支付订单由于调用链路长以及网络延迟等原因,最终数据入库的时间漂移到了12日
可以通过多个时间戳限制
kafka设置偏移量?
–to-offset --execute 执行指定的偏移量
kafka压测?
Kafka Producer压力测试
脚本:
bin/kafka-producer-perf-test.sh --topic test --record-size 100 --num-records 100000 --throughput -1 --producer-props bootstrap.servers=hadoop100:9092,hadoop102:9092,hadoop101:9092
参数:
–topic:topic名称
–record-size:一条信息有多大,单位字节
–num-records:总共发送多少条信息
–throughput:每秒多少条信息,设置成-1,表示不限流,可测生产者最大吞吐量
–bootstrap.servers:发送端配置信息
结果:
100000 records sent, 27495.188342 records/sec (2.62 MB/sec), 1461.75 ms avg latency, 2183.00 ms max latency, 1696 ms 50th, 2103 ms 95th, 2177 ms 99th, 2181 ms 99.9th.
解析:
一共写入10万条消息
每秒27495.188342条记录
吞吐量为2.62 MB/sec
每次写入的平均延迟为1461.75ms
最大延迟2183.00 ms
Kafka Consumer 压力测试
脚本:
bin/kafka-consumer-perf-test.sh --broker-list hadoop100:9092 --topic test --fetch-size 10000 -messages 10000000 --threads 1
参数说明:
–broker-list:节点地址
–topic:指定topic名称
–fetch-size:指定每个fetch的数据大小
–messages:总共要消费的消息个数
–threads:处理线程数
结果:
start.time, end.time, data.consumed.in.MB, MB.sec, data.consumed.in.nMsg, nMsg.sec, rebalance.time.ms, fetch.time.ms, fetch.MB.sec, fetch.nMsg.sec
2020-06-27 13:17:57:490, 2020-06-27 13:18:11:751, 20.0272, 1.4043, 210000, 14725.4751, 1593235077858, -1593235063597, -0.0000, -0.0001
解释:
开始时间
结束时间
共消费数据:20.0272M
吞吐量:1.4043MB/s
共消费数据:210000条
平均每秒消费:14725.4751条














 1031
1031











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









