







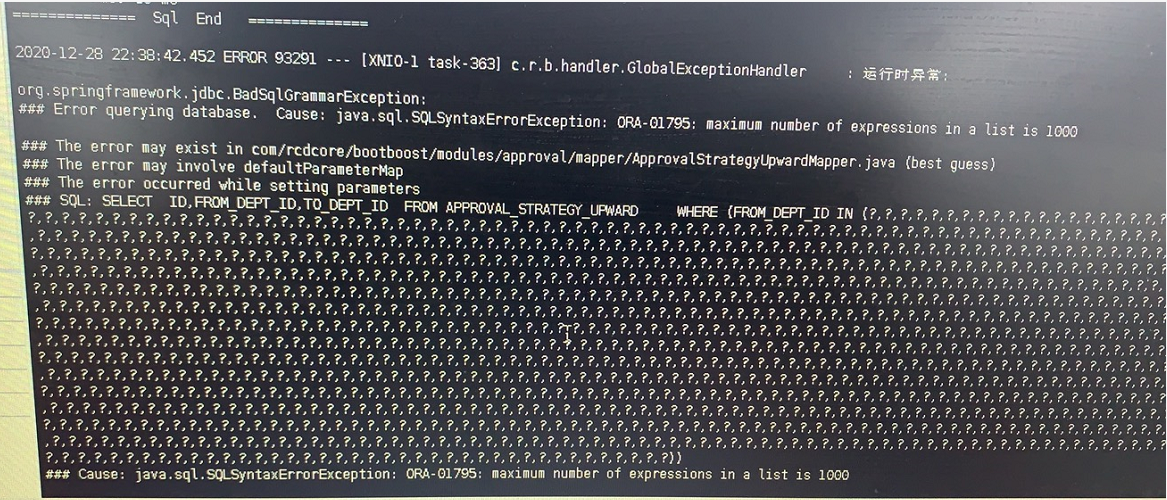
解决方法:
public class BachUtil {
/**
* 批量保护数量
*/
public static final Integer OPEN_BACH_PROTECT = 996;
/**
* 批次数量
*/
public static final Integer NUMBER_BACH_PROTECT = 996;
/**
* 批量中包含有关联查询,可能因为数据过长出现数据查询的的问题,
* 这里进行分批处理
* @param list
* 需要处理的list
* @param bach
* 批量处理的函数
* @param <T>
* 元素类型
*/
public static <T> void protectBach(List<T> list, Consumer<List<T>> bach){
if (isEmpty(list)){return;}
if (list.size() > OPEN_BACH_PROTECT) {
for (int i = 0; i < list.size(); i += NUMBER_BACH_PROTECT) {
int lastIndex = Math.min(i + NUMBER_BACH_PROTECT, list.size());
bach.accept(list.subList(i, lastIndex));
}
}else {
bach.accept(list);
}
}
/**
* 批量中包含有关联查询,可能因为数据过长出现数据查询的的问题
* 这里进行分批,合并数据处理。
* @param list
* 原数据
* @param bach
* 处理方法
* @param <T>
* 原数据类型
* @param <R>
* 处理结果类型
* @return
* 处理结果汇总
*/
public static <T, R> List<R> bach(List<T> list, Function<List<T>, List<R>> bach){
if (isEmpty(list)){return Collections.emptyList();}
if (list.size() > OPEN_BACH_PROTECT) {
List<R> end = new LinkedList<>();
for (int i = 0; i < list.size(); i += NUMBER_BACH_PROTECT) {
int lastIndex = Math.min(i + NUMBER_BACH_PROTECT, list.size());
Optional.ofNullable(bach.apply(list.subList(i, lastIndex)))
.ifPresent(end::addAll);
}
return end;
}
return bach.apply(list);
}
private static <T> boolean isEmpty(Collection<T> collection) {
return collection == null || collection.isEmpty();
}
/**
* 多线程方式
* 注意:
* 1. 线程数量,根据自己的环境,自行调节。这里是根据系统核心数给的默认值。
* 2. 连接池数量,线程池数量过大,容易撑爆线程池,所以适当调节线程池大小。
*/
public static final ExecutorService THREAD_POOL = Executors.newWorkStealingPool();
@lombok.SneakyThrows
public static <T, R> List<R> bachByThread(List<T> list, Function<List<T>, List<R>> bach){
if (isEmpty(list)){return Collections.emptyList();}
if (list.size() > OPEN_BACH_PROTECT) {
List<Future<List<R>>> futures = new LinkedList<>();
for (int i = 0; i < list.size(); i += NUMBER_BACH_PROTECT) {
int finalI = i;
int lastIndex = Math.min(i + NUMBER_BACH_PROTECT, list.size());
futures.add(THREAD_POOL.submit(() -> bach.apply(list.subList(finalI, lastIndex))));
}
return futures.parallelStream()
.flatMap(a -> Optional.ofNullable(a.get()).orElse(Collections.emptyList()).stream())
.collect(Collectors.toList());
}
return bach.apply(list);
}
}
欢迎交流,其他处理方案,或思路。
补充使用例子,批量处理的方法随便写的,实际中一般是要关联查询的。
public static class Node{
int x;
int y;
int area;
}
/**
* 计算到原点围成的面积。
* @param list
*/
public static void addNodeArea(List<Node> list){
// 这里仅仅是个例子,实际业务中,一般是要关联查询的,使用in的关联查询大于1000会出错
System.out.println("执行了一次");
for (Node node : list) {
node.area = node.x * node.y;
}
}
/**
* 调用方式展示
* @param args
*/
public static void main(String[] args) {
List<Node> list = new ArrayList<>();
for (int i = 0; i < 10000; i++) {
Node node = new Node();
node.x = (int) Math.random();
node.y = (int) Math.random();
list.add(node);
}
// 直接调用
// addNodeArea(list);
protectBach(list, BachUtil::addNodeArea);
}
这种使用方式吧,是不影响主要业务逻辑的补充查询,一般分页没问题,碰到需要查全表的就坑死了。我这里有个树形菜单有2k+的数据量,要一下子查出来,然后就爆了。爆炸了怎么办,加一层处理。
当然,可以不仅仅是关联查询,比如要加做一些其他操作,比如修改对应的状态,删除关联的表内容,发送通知啥的,避免不了关联查询,然后触发使用in的bug,然后爆炸。
关联查询的另外两种方式
- 使用in和or的组合查询,针对条件进行拆分处理,但是效率不高(in本身效率不高,or也是)。
- 写到自定义sql中,进行关联查询,但是需要修改主要的业务逻辑。
另外
listByIds() 方法也有这个问题














 3257
3257











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









