







缓冲区buffer和缓存cache
- 缓存包括两部分,一部分是磁盘读取文件的页缓存,用来缓存从磁盘读取的数据,可以加快以后再次访问的速度。另一部分,则是 Slab 分配器中的可回收内存。
- 缓冲区是对原始磁盘块的临时存储,用来缓存将要写入磁盘的数据。这样,内核就可以把分散的写集中起来,统一优化磁盘写入。
写文件时会用到Cache 缓存数据,而写磁盘则会用到 Buffer来缓存数据。所以,回到刚刚的问题,虽然文档上只提到,Cache是文件读的缓存,但实际上,Cache 也会缓存写文件时的数据。
观察buffer cache变化,vmstat命令∶
[root@www ~]# vmstat 1
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
2 0 1460 498756 0 106032 0 0 10 36 101 103 1 0 99 0 0
0 0 1460 498740 0 106032 0 0 0 0 99 117 0 1 99 0 0
0 0 1460 498740 0 106032 0 0 0 0 133 133 1 0 99 0 0输出界面里,内存部分的 buff和 cache,以及 io 部分的bi和bo 就是我们要关注的重点。
- buff和 cache就是我们前面看到的Buffers和Cache,单位是 KB。
- bi和 bo 则分别表示块设备读取和写入的大小,单位为块/秒。因为Linux中块的大小是1KB,所以这个单位也就等价于 KB/s。
简单来说,Buffer 是对磁盘数据的缓存,而 Cache 是文件数据的缓存,它们既会用在读请求中,也会用在写请求中。
- 从写的角度来说,不仅可以优化磁盘和文件的写入,对应用程序也有好处,应用程序可以在数据真正落盘前,就返回去做其他工作。
- 从读的角度来说,既可以加速读取那些需要频繁访问的数据,也降低了频繁I/O对磁盘的压力。
缓存命中率
缓存的命中率。所谓缓存命中率,是指直接通过缓存获取数据的请求次数,占所有数据请求次数的百分比。命中率越高,表示使用缓存带来的收益越高,应用程序的性能也就越好。
实际上,缓存是现在所有高并发系统必需的核心模块,主要作用就是把经常访问的数据(也就是热点数据),提前读入到内存中。这样,下次访问时就可以直接从内存读取数据,而不需要经过硬盘,从而加快应用程序的响应速度。
cachestat 提供了整个操作系统缓存的读写命中情况
[root@docker ~]# cachestat 1 3
HITS MISSES DIRTIES HITRATIO BUFFERS_MB CACHED_MB
0 0 0 0.00% 16 394
1 0 0 100.00% 16 394
0 0 0 0.00% 16 394你可以看到,cachestat的输出其实是一个表格。每行代表一组数据,而每一列代表不同的缓存统计指标。这些指标从左到右依次表示∶
- MSSES,表示缓存未命中的次数
- HITS,表示缓存命中的次数
- DIRTIES,表示新增到缓存中的脏页数
- BUFFERS_MB表示 Buffers的大小,以 MB为单位
- CACHED_MB表示 Cache的大小,以 MB为单位
cachetop 提供了每个进程的缓存命中情况
接下来我们再来看一个 cachetop的运行界面∶
$ cachetop
11:58:50 Buffers MB:258/Cached MB:347/Sort:HITS / Order:ascending
PID UID CMD HITS MISSES DIRTIES READ_HIT% wRITE_HIT%
13029 root python 1 0 0 100.0% 0.0%
它的输出跟 top类似,默认按照缓存的命中次数(HITS)排序,展示了每个进程的缓存命中情况。具体到每一个指标,这里的HITS、MISSES和 DIRTIES,跟 cachestat 里的含义一样,分别代表间隔时间内的缓存命中次数、未命中次数以及新增到缓存中的脏页数。
而READ_HIT和WRITE_HIT,分别表示读和写的缓存命中率。
查看某个容器状态,查看是什么原因退出
[root@docker ~]# docker inspect a6fb3d53a55b | grep -i status -A 10
"Status": "exited",
"Running": false,
"Paused": false,
"Restarting": false,
"OOMKilled": true,
"Dead": false,
"Pid": 0,
"ExitCode": 137,
"Error": "",
"StartedAt": "2021-11-11T00:48:00.806908787Z",
"FinishedAt": "2021-11-11T00:48:39.15824301Z"2.vm.overcommit_memory
Redis在启动时可能会出现这样的日志:
WARNING overcommit_memory is set to 0! Background save may fail under low memory condition.
To fix this issue add 'vm.overcommit_memory = 1' to /etc/sysctl.conf
and then reboot or run the command 'sysctl vm.overcommit_memory=1' for this to take effect.在分析这个问题之前, 首先要弄清楚什么是overcommit? Linux操作系统对大部分申请内存的请求都回复yes, 以便能运行更多的程序。 因为申请内存后, 并不会马上使用内存, 这种技术叫做overcommit。 如果Redis在启动时有上面的日志, 说明vm.overcommit_memory=0, Redis提示把它设置为1。
vm.overcommit_memory用来设置内存分配策略, 有三个可选值, 如表:可用内存代表物理内存与swap之和

日志中的Background save代表的是bgsave和bgrewriteaof, 如果当前可用内存不足, 操作系统应该如何处理fork操作。 如果
vm.overcommit_memory=0, 代表如果没有可用内存, 就申请内存失败, 对应到Redis就是执行fork失败, 在Redis的日志会出现:
Cannot allocate memoryRedis建议把这个值设置为1, 是为了让fork操作能够在低内存下也执行成功。
3.oom_badness() 函数
在发生 OOM 的时候,Linux 到底是根据什么标准来选择被杀的进程呢?这就要提到一个在 Linux 内核里有一个 oom_badness() 函数,就是它定义了选择进程的标准。其实这里的判断标准也很简单,函数中涉及两个条件:
- 第一,进程已经使用的物理内存页面数。
- 第二,每个进程的 OOM 校准值 oom_score_adj。在 /proc 文件系统中,每个进程都有一个 /proc/<pid>/oom_score_adj 的接口文件。我们可以在这个文件中输入 -1000 到 1000 之间的任意一个数值,调整进程被 OOM Kill 的几率。
adj = (long)p->signal->oom_score_adj;
points = get_mm_rss(p->mm) + get_mm_counter(p->mm, MM_SWAPENTS) +mm_pgtables_bytes(p->mm) / PAGE_SIZE;
adj *= totalpages / 1000;
points += adj;结合前面说的两个条件,函数 oom_badness() 里的最终计算方法是这样的:用系统总的可用页面数,去乘以 OOM 校准值 oom_score_adj,再加上进程已经使用的物理页面数,计算出来的值越大,那么这个进程被 OOM Kill 的几率也就越大。
每个进程的权值存放在/proc/{progress_id}/oom_score中,这个值受/proc/{progress_id}/oom_adj的控制,oom_adj在不同的Linux版本中最小值不同,可以参考Linux源码中oom.h(从-15到-17)。当oom_adj设置为最小值时,该进程将不会被OOM killer杀掉,设置方法如下。
echo {value} > /proc/${process_id}/oom_adj4.Memory Cgroup?
Memory Cgroup 也是 Linux Cgroups 子系统之一,它的作用是对一组进程的 Memory 使用做限制。
第一个参数,叫作 memory.limit_in_bytes。请你注意,这个 memory.limit_in_bytes 是每个控制组里最重要的一个参数了。这是因为一个控制组里所有进程可使用内存的最大值,就是由这个参数的值来直接限制的。
第二个参数 memory.oom_control 了。这个 memory.oom_control 又是干啥的呢?当控制组中的进程内存使用达到上限值时,这个参数能够决定会不会触发 OOM Killer。
如果没有人为设置的话,memory.oom_control 的缺省值就会触发 OOM Killer。这是一个控制组内的 OOM Killer,和整个系统的 OOM Killer 的功能差不多,差别只是被杀进程的选择范围:控制组内的 OOM Killer 当然只能杀死控制组内的进程,而不能选节点上的其他进程。
第三个参数,也就是 memory.usage_in_bytes。这个参数是只读的,它里面的数值是当前控制组里所有进程实际使用的内存总和。我们可以查看这个值,然后把它和 memory.limit_in_bytes 里的值做比较,根据接近程度来可以做个预判。这两个值越接近,OOM 的风险越高。通过这个方法,我们就可以得知,当前控制组内使用总的内存量有没有 OOM 的风险了。
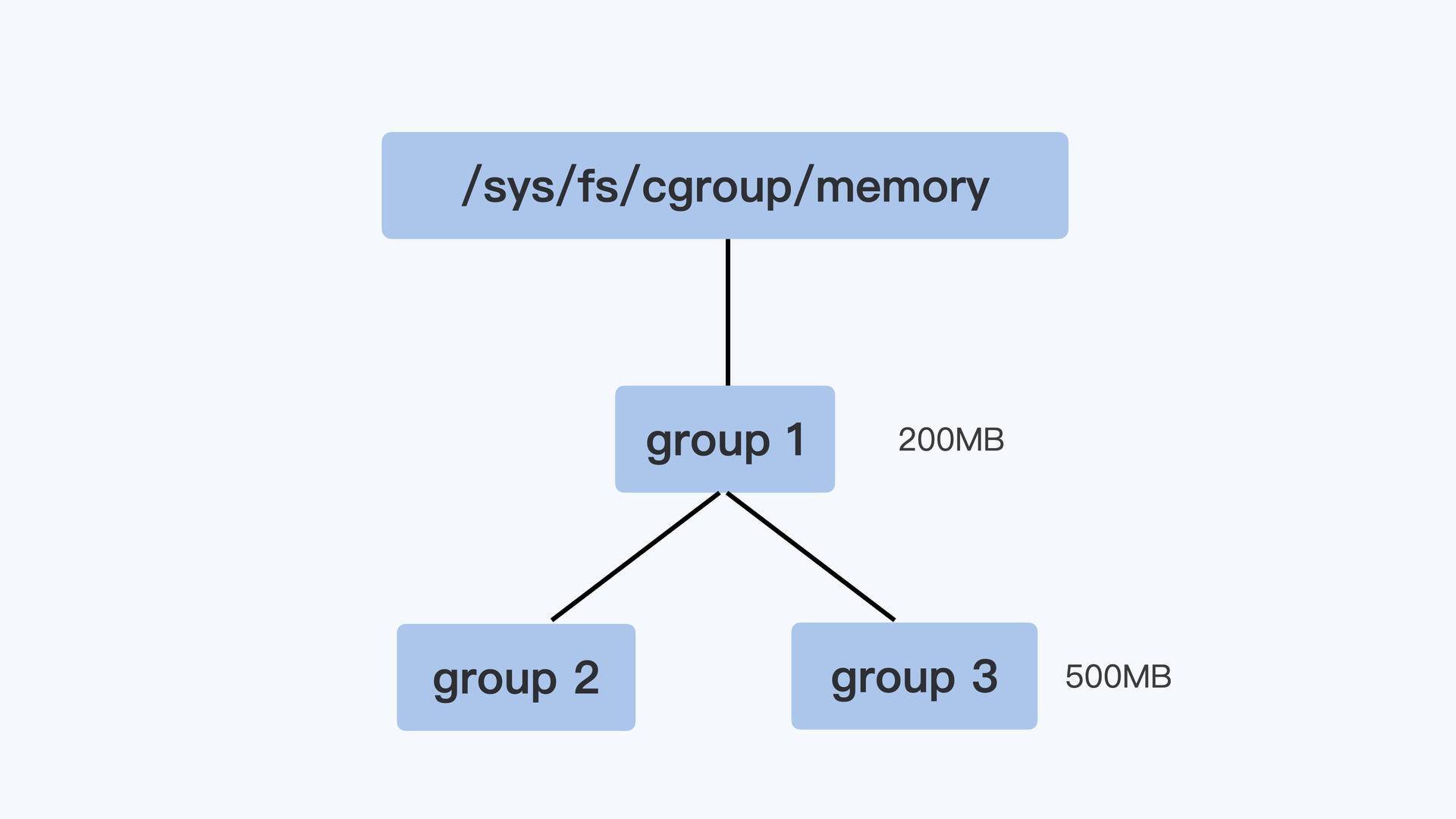
控制组
控制组之间也同样是树状的层级结构,在这个结构中,父节点的控制组里memory.limit_in_bytes 值,就可以限制它的子节点中所有进程的内存使用。
我用一个具体例子来说明,比如像下面图里展示的那样,group1 里的 memory.limit_in_bytes 设置的值是 200MB,它的子控制组 group3 里 memory.limit_in_bytes 值是 500MB。那么,我们在 group3 里所有进程使用的内存总值就不能超过 200MB,而不是 500MB。
好了,我们这里介绍了 Memory Cgroup 最基本的概念,简单总结一下:
第一,Memory Cgroup 中每一个控制组可以为一组进程限制内存使用量,一旦所有进程使用内存的总量达到限制值,缺省情况下,就会触发 OOM Killer。这样一来,控制组里的“某个进程”就会被杀死。
第二,这里杀死“某个进程”的选择标准是,控制组中总的可用页面乘以进程的 oom_score_adj,加上进程已经使用的物理内存页面,所得值最大的进程,就会被系统选中杀死。
Linux 系统有那些内存类型?
只有知道了内存的类型,才能明白每一种类型的内存,容器分别使用了多少。而且,对于不同类型的内存,一旦总内存增高到容器里内存最高限制的数值,相应的处理方式也不同。
Linux 的各个模块都需要内存,比如内核需要分配内存给页表,内核栈,还有 slab,也就是内核各种数据结构的 Cache Pool;用户态进程里的堆内存和栈的内存,共享库的内存,还有文件读写的 Page Cache。
Memory Cgroup 里都不会对内核的内存做限制(比如页表,slab 等)。所以我们今天主要讨论与用户态相关的两个内存类型,RSS 和 Page Cache。
RSS
先看什么是 RSS。RSS 是 Resident Set Size 的缩写,简单来说它就是指进程真正申请到物理页面的内存大小。这是什么意思呢?
应用程序在申请内存的时候,比如说,调用 malloc() 来申请 100MB 的内存大小,malloc() 返回成功了,这时候系统其实只是把 100MB 的虚拟地址空间分配给了进程,但是并没有把实际的物理内存页面分配给进程。
上一讲中,我给你讲过,当进程对这块内存地址开始做真正读写操作的时候,系统才会把实际需要的物理内存分配给进程。而这个过程中,进程真正得到的物理内存,就是这个 RSS 了。
比如下面的这段代码,我们先用 malloc 申请 100MB 的内存。
p = malloc(100 * MB);
if (p == NULL)
return 0;
然后,我们运行 top 命令查看这个程序在运行了 malloc() 之后的内存,我们可以看到这个程序的虚拟地址空间(VIRT)已经有了 106728KB(~100MB),但是实际的物理内存 RSS(top 命令里显示的是 RES,就是 Resident 的简写,和 RSS 是一个意思)在这里只有 688KB。

接着我们在程序里等待 30 秒之后,我们再对这块申请的空间里写入 20MB 的数据。
sleep(30);
memset(p, 0x00, 20 * MB)当我们用 memset() 函数对这块地址空间写入 20MB 的数据之后,我们再用 top 查看,这时候可以看到虚拟地址空间(VIRT)还是 106728,不过物理内存 RSS(RES)的值变成了 21432(大小约为 20MB), 这里的单位都是 KB。

所以,通过刚才上面的小实验,我们可以验证 RSS 就是进程里真正获得的物理内存大小。
对于进程来说,RSS 内存包含了进程的代码段内存,栈内存,堆内存,共享库的内存, 这些内存是进程运行所必须的。刚才我们通过 malloc/memset 得到的内存,就是属于堆内存。
具体的每一部分的 RSS 内存的大小,你可以查看 /proc/[pid]/smaps 文件。
[root@8ddcdff501a3 /]# ps -aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.0 1132 4 ? Ss 08:58 0:00 /sbin/docker-init -- /read_file /mnt/test.file 100
root 7 0.0 0.0 5352 2240 ? S 08:58 0:00 /read_file /mnt/test.file 100
root 8 0.0 0.0 12024 3364 pts/0 Ss 09:45 0:00 bash
root 24 0.0 0.0 46352 3428 pts/0 R+ 10:11 0:00 ps -aux
[root@docker ~]# ps -ef | grep mnt
root 7767 7739 0 16:58 ? 00:00:00 /sbin/docker-init -- /read_file /mnt/test.file 100
root 7797 7767 0 16:58 ? 00:00:00 /read_file /mnt/test.file 100
root 11994 10493 0 18:11 pts/4 00:00:00 grep --color=auto mnt
[root@docker ~]# cat /proc/7797/smaps | grep -i RSS
Rss: 4 kB
Rss: 4 kB
Rss: 4 kB
Rss: 1032 kB
Rss: 1176 kB
Rss: 0 kB
Rss: 16 kB
Rss: 8 kB
Rss: 12 kB
Rss: 160 kB
Rss: 8 kB
Rss: 4 kB
Rss: 4 kB
Rss: 4 kB
Rss: 8 kB
Rss: 0 kB
Rss: 4 kB
Rss: 0 kB
[root@docker ~]# echo $((4+4+4+1032+1176+16+8+12+160+8+4+4+4+8+4))
2448














 131
131











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









