







 本文详细介绍了Prometheus的时间序列数据聚合操作,包括sum、min、max、avg等内置聚合函数,以及如何通过without和by进行标签维度的聚合。同时,讨论了基于时间的聚合如_over_time()函数,用于平滑曲线和计算时间范围内的统计值。此外,还介绍了子查询的概念,用于计算如最大请求率等复杂指标。最后,提供了几个具体的PromQL查询示例和练习。
本文详细介绍了Prometheus的时间序列数据聚合操作,包括sum、min、max、avg等内置聚合函数,以及如何通过without和by进行标签维度的聚合。同时,讨论了基于时间的聚合如_over_time()函数,用于平滑曲线和计算时间范围内的统计值。此外,还介绍了子查询的概念,用于计算如最大请求率等复杂指标。最后,提供了几个具体的PromQL查询示例和练习。

Prometheus还提供了下列内置的聚合操作符,这些操作符作用域瞬时向量。可以将瞬时表达式返回的样本数据进行聚合,形成一个新的时间序列。
聚合运算符从标签维度进行聚合,这些运算符在一个时间内对多个序列进行聚合。
聚合函数
官方文档:https://prometheus.io/docs/prometheus/latest/querying/operators/
- sum():对样本值求和;
- avg():对样本值求平均值这是进行指标数据分析的标准方法;
- count():对分组内的时间序列进行数量统计; 计算序列的总数,要和sum区分开
- stddev():对样本值求标准差,以帮助用户了解数据的波动大小(或称之为波动程度)
- stdvar():对样本值求方差,它是求取标准差过程的中间状态;
- min():求取样本值的最小值;
- max():求取样本值的最大值;
- topk():逆序返回分组内的样本值最大的前k个时间序列及其值;
- bottomk():顺序返回分组内的样本值最小的前k个时间序列及其值;
- quantile():分位数用于评估数据的分布状态,该函数会返回分组内指定的分位数的值,即数值落在小于等于指定的分位区间的比例;
- count_values():对分组内的时间序列的样本值进行数量统计;
聚合表达式 group 只是按标签分组,并将样本值设为 1
使用聚合操作的语法如下:
- PromQL中的聚合操作语法格式可采用如下两种格式之一:
- <aggr-op> ([parameter,]<vector exoression>) [without|by(<label list>)]
- <aggr-op> [without|by(<label list>)] ([parameter,]<vector exoression>)
- 分组聚合:先分组、后聚合
- without:从结果向量中删除由without子句指定的标签,未指定的那部分标签则用作分组标准;
- by:功能与without刚好相反,它仅使用by字句中指定的标签进行聚合,结果向量中出现但未被by子句指定的标签则会被忽略;
- 为了保留上下文信息,使用by字句时需要显示指定其结果中原本出现的job、instance等一类标签;
- 事实上,各函数工作机制的不同之处也仅在于计算操作本身,PromQL对于它们的执行逻辑相似;
其中只有count_values, quantile, topk, bottomk支持参数(parameter)。
without用于从计算结果中移除列举的标签,而保留其它标签。by则正好相反,结果向量中只保留列出的标签,其余标签则移除。通过without和by可以按照样本的问题对数据进行聚合。
例如:
sum(http_requests_total) without (instance)等价于
sum(http_requests_total) by (code,handler,job,method)如果只需要计算整个应用的HTTP请求总量,可以直接使用表达式:
sum(http_requests_total)聚合
我们知道 Prometheus 的时间序列数据是多维数据模型,我们经常就有根据各个维度进行汇总的需求。
基于标签 分组聚合
- request_duration_seconds_count 就是一共有多少个请求
- request_duration_seconds_sum 是总的延迟时间,就是所有请求一共花了多长时间
例如我们想知道的 demo 服务5m钟处理的请求数,那么可以所有单个的速率相加就可以,这样就可以算得5m内所有的请求数量。
sum(rate(demo_api_request_duration_seconds_count{job="demo"}[5m]))
可以得到如下所示的结果:

但是我们可以看到绘制出来的图形没有保留任何标签维度,一般来说可能我们希望保留一些维度,例如,我们可能更希望计算每个 instance 和 path 的变化率,但并不关心单个 method 或者 status 的结果,这个时候我们可以在 sum() 聚合器中添加一个 without() 的修饰符:
sum without(method, status) (rate(demo_api_request_duration_seconds_count{job="demo"}[5m]))

上面的查询语句相当于用 by() 修饰符来保留需要的标签的取反操作:by()类似于SQL语句里面的group by,这里是根据什么去做分组聚合。
sum by(instance, path, job) (rate(demo_api_request_duration_seconds_count{job="demo"}[5m]))

现在得到的 sum 结果是就是按照 instance、path、job 来进行分组去聚合的了:

最后同理apiserver也是一样的
sum by(verb)(rate(apiserver_request_duration_seconds_count[5m]))
这里的分组概念和 SQL 语句中的分组去聚合就非常类似了。
除了 sum() 之外,Prometheus 还支持下面的这些聚合器/聚合函数:(如果不加上by进行分组,那么计算的是整个时间序列的值,只是一个值而已,没有标签维度)



聚合函数:avg (平均值)
通过查询 metric值为 node_cpu_seconds_total 来获取当前CPU 的所有信息,直接通过此参数参数,会查到的数据是当前CPU的所有相关的收集到的数据。
此时就需要使用 irate 函数,用于计算距离向量中的实际序列的每秒顺势增长率。再根据标签筛选来查询如下:
irate(node_cpu_seconds_total{job="node"}[5m])使用avg聚合查询到的数据后,再使用by 来区分实例,这样就能做到分实例查询各自的数据。
avg(irate(node_cpu_seconds_total{job="node_srv"}[5m])) by (instance)上面的语句查询到的CPU数据,是包含CPU的所有数据,而我们要查询的是CPU的5分钟负载
思路就可以这样:查询出CPU的空闲值mode='idle',乘以一百得出空闲百分比后,在用100减去空闲百分比就得出CPU使用的百分比
如下:
100 - ((avg(irate(node_cpu_seconds_total{job="node_srv",mode="idle"}[5m])) by (instance)) * 100)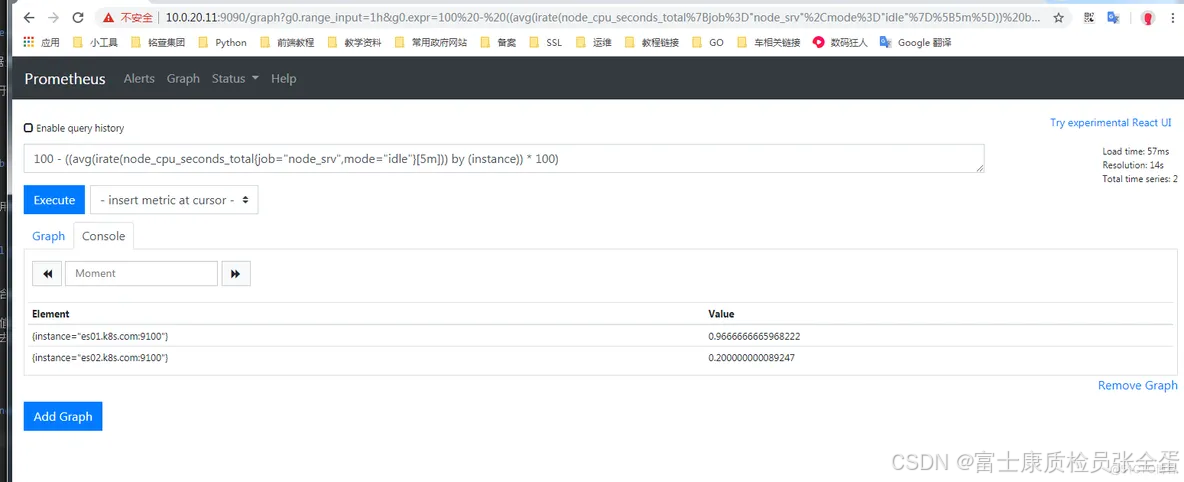
练习:
1.按
job分组聚合,计算我们正在监控的所有进程的总内存使用量(process_resident_memory_bytes指标):sum by(job) (process_resident_memory_bytes)
2.计算指标有多少不同的CPU模式:
count (group by(mode) (demo_cpu_usage_seconds_total))
3.计算每个 job 任务和指标名称的时间序列数量:
count by (job, __name__) ({__name__ != ""})每个指标里面都有_name_


基于时间聚合(Gauge类型)
前面我们已经学习了如何使用 sum()、avg() 和相关的聚合运算符从标签维度进行聚合,这些运算符在一个时间内对多个序列进行聚合,但是有时候我们可能想在每个序列中按时间进行聚合,例如,使尖锐的曲线更平滑,或深入了解一个序列在一段时间内的最大值。
为了基于时间来计算这些聚合,PromQL 提供了一些与标签聚合运算符类似的函数,但是在这些函数名前面附加了 _over_time()
<aggregation>_over_time()
下面的函数列表允许传入一个区间向量,它们会聚合每个时间序列的范围,并返回一个瞬时向量:
avg_over_time(range-vector):区间向量内每个指标的平均值。min_over_time(range-vector):区间向量内每个指标的最小值。max_over_time(range-vector):区间向量内每个指标的最大值。sum_over_time(range-vector):区间向量内每个指标的求和。count_over_time(range-vector):区间向量内每个指标的样本数据个数。quantile_over_time(scalar, range-vector):区间向量内每个指标的样本数据值分位数。stddev_over_time(range-vector):区间向量内每个指标的总体标准差。stdvar_over_time(range-vector):区间向量内每个指标的总体标准方差。
[info] 注意:即使区间向量内的值分布不均匀,它们在聚合时的权重也是相同的。
例如,我们查询 demo 实例中使用的 goroutine 的原始数量,可以使用查询语句 go_goroutines{job="demo"},这会产生一些尖锐的峰值图:

我们可以通过对图中的每一个点来计算 10 分钟内的 goroutines 数量进行平均来使图形更加平滑:他要算十分钟之内的平均值,其实就是将这些值全部加起来求平均。

可以看到计算的平均值

avg_over_time(go_goroutines{job="demo"}[10m])
这个查询结果生成的图表看起来就平滑很多了:

比如要查询 1 小时内内存的使用率则可以用下面的查询语句:
100 * (1 - ((avg_over_time(node_memory_MemFree_bytes[1h]) + avg_over_time(node_memory_Cached_bytes[1h]) + avg_over_time(node_memory_Buffers_bytes[1h])) / avg_over_time(node_memory_MemTotal_bytes[1h])))



子查询
上面所有的 _over_time() 函数都需要一个范围向量作为输入(比如[5m]),通常情况下只能由一个区间向量选择器来产生,比如 my_metric[5m]。但是如果现在我们想使用例如 max_over_time() 函数来找出过去一天中 demo 服务的最大请求率应该怎么办呢?
请求率 rate 并不是一个我们可以直接选择时间的原始值,而是一个计算后得到的值,比如:
rate(demo_api_request_duration_seconds_count{job="demo"}[5m])
如果我们直接将表达式传入 max_over_time() 并附加一天的持续时间查询的话就会产生错误:
# ERROR!
max_over_time(
rate(
demo_api_request_duration_seconds_count{job="demo"}[5m]
)[1d]
)
实际上 Prometheus 是支持子查询的,它允许我们首先以指定的步长在一段时间内执行内部查询,然后根据子查询的结果计算外部查询。子查询的表示方式类似于区间向量的持续时间,但需要冒号后添加了一个额外的步长参数:[<duration>:<resolution>]。
这样我们可以重写上面的查询语句,告诉 Prometheus 在一天的范围内评估内部表达式,步长分辨率为 15s:
max_over_time(
rate(
demo_api_request_duration_seconds_count{job="demo"}[5m]
)[1d:15s] # 在1天内明确地评估内部查询,步长为15秒
)
也可以省略冒号后的步长,在这种情况下,Prometheus 会使用配置的全局 evaluation_interval 参数进行评估内部表达式:
max_over_time(
rate(
demo_api_request_duration_seconds_count{job="demo"}[5m]
)[1d:]
)
这样就可以得到过去一天中 demo 服务最大的 5 分钟请求率,不过冒号仍然是需要的,以明确表示运行子查询。子查询还允许添加一个偏移修饰符 offset 来对内部查询进行时间偏移,类似于瞬时和区间向量选择器。
但是也需要注意长时间计算子查询代价也是非常昂贵的,我们可以使用记录规则(后续会讲解)预先记录中间的表达式,而不是每次运行外部查询时都实时计算它。
练习:
- 输出过去一小时内 demo 服务的最大 95 分位数延迟值(1 分钟内平均),按 path 划分:
max_over_time( histogram_quantile(0.95, sum by(le, path) ( rate(demo_api_request_duration_seconds_bucket[1m]) ) )[1h:] )

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









