







Node节点默认的Pod数量(如果node节点数目过小,在驱逐的时候pod被调度到其他节点,容易pending,因为其他节点有pod运行数量限制)
Kubernetes Node节点每个默认允许最多创建110个Pod,有时可能会由于系统硬件的问题,从而需要控制Node节点的Pod的运行数量。
即:需要调整Node节点的最大可运行Pod数量。
一般来说,我们只需要在kubelet配置文件中增加–max-pods参数,然后,重启kubelet 服务,就生效。
重启kubelet,不影响现有运行中的容器,不会造成容器重启。(Default Max POD Value per node is 110)
[root@master ~]# kubectl describe node master
Capacity:
cpu: 2
ephemeral-storage: 104845360Ki
hugepages-2Mi: 0
memory: 4045032Ki
pods: 110
[root@master ~]# kubectl describe node master | grep -i pods:
pods: 110
pods: 110
Non-terminated Pods: (13 in total)修改限制Pod启动数量
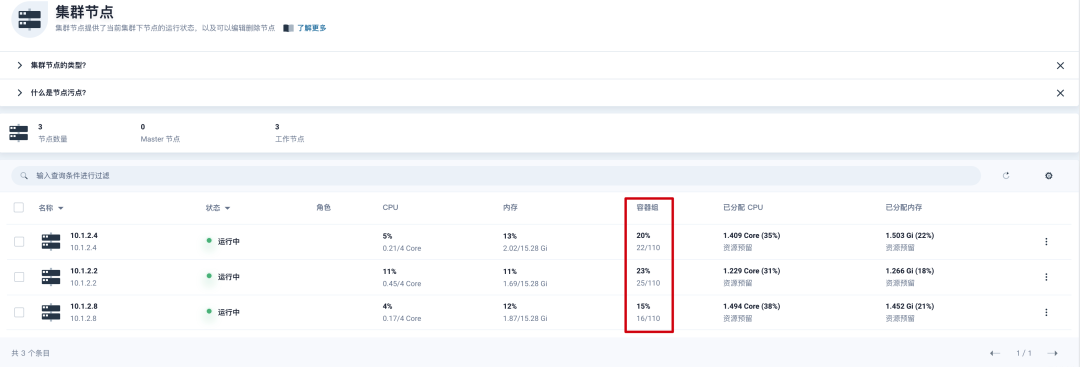
修改
1、登录 Node 节点,查看kubelet启动文件路径(Find config file path for kubelet on worker node)
[root@VM-2-8-centos ~]# systemctl status kubelet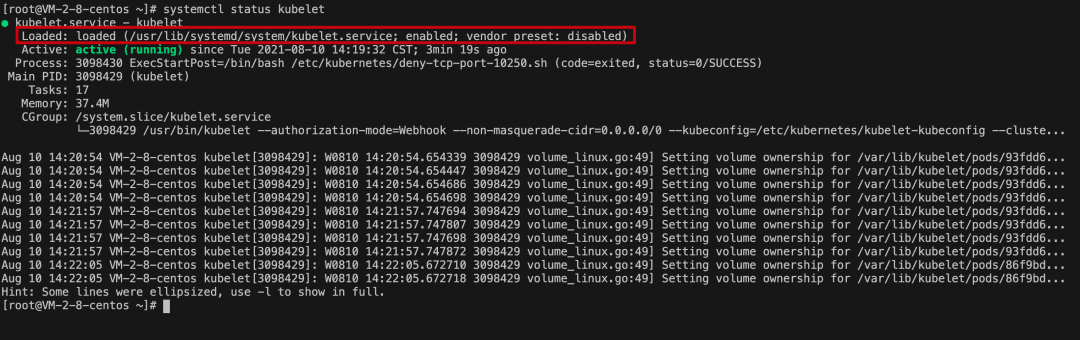
从上图可以看到,kubelet 的配置文件为 /var/lib/kubelet/config.yaml
2、修改/etc/kubernetes/kubelet(Update/Add maxPods field on /var/lib/kubelet/config.yaml as needed and restart kubelet on worker node)
强烈建议,在修改Pod数量的时候,如果是缩减(当前运行70个Pod,缩减到20个),强烈建议先把Node上的Pod驱散,等驱散完了在重启,最后在激活Node。
ubuntu@k8s-worker-1:~$ sudo cat /var/lib/kubelet/config.yaml
apiVersion: kubelet.config.k8s.io/v1beta1
authentication:
anonymous:
enabled: false
webhook:
cacheTTL: 0s
enabled: true
x509:
clientCAFile: /etc/kubernetes/pki/ca.crt
authorization:
mode: Webhook
webhook:
cacheAuthorizedTTL: 0s
cacheUnauthorizedTTL: 0s
clusterDNS:
- 10.96.0.10
clusterDomain: cluster.local
cpuManagerReconcilePeriod: 0s
evictionPressureTransitionPeriod: 0s
fileCheckFrequency: 0s
healthzBindAddress: 127.0.0.1
healthzPort: 10248
httpCheckFrequency: 0s
imageMinimumGCAge: 0s
kind: KubeletConfiguration
nodeStatusReportFrequency: 0s
nodeStatusUpdateFrequency: 0s
rotateCertificates: true
runtimeRequestTimeout: 0s
staticPodPath: /etc/kubernetes/manifests
streamingConnectionIdleTimeout: 0s
syncFrequency: 0s
volumeStatsAggPeriod: 0s
maxPods: 5003、重启kubelet
[root@VM-2-8-centos ~]# systemctl restart kubelet查看修改结果
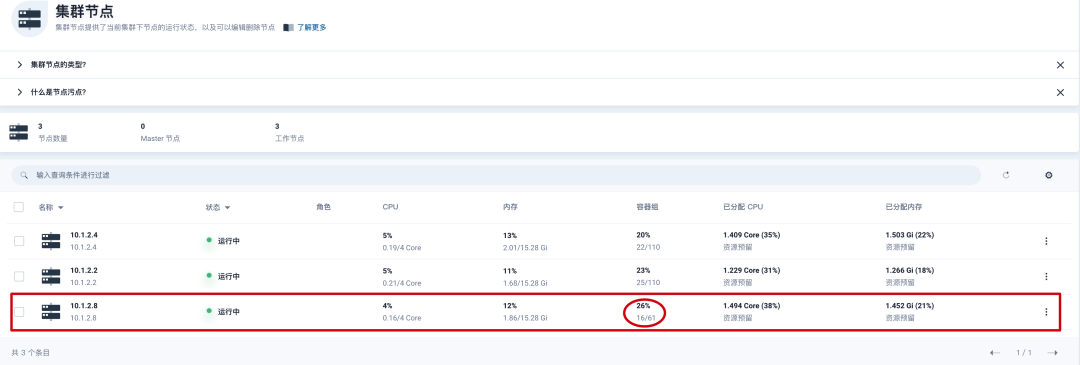
可以看到,已经完成修改的节点的最大可调度Pod数量已经调整为61。配置生效。
新建监控视图
在这里,我们可以部署Prometheus + Grafana,配置监控视图,更好的体现集群中节点的 Pod 分配率。
PromQL:
sum(kubelet_running_pod_count{node=~"$node"}) by (cluster, node) / sum(kube_node_status_allocatable_pods{node=~"$node"}) by (cluster, node)效果展示:
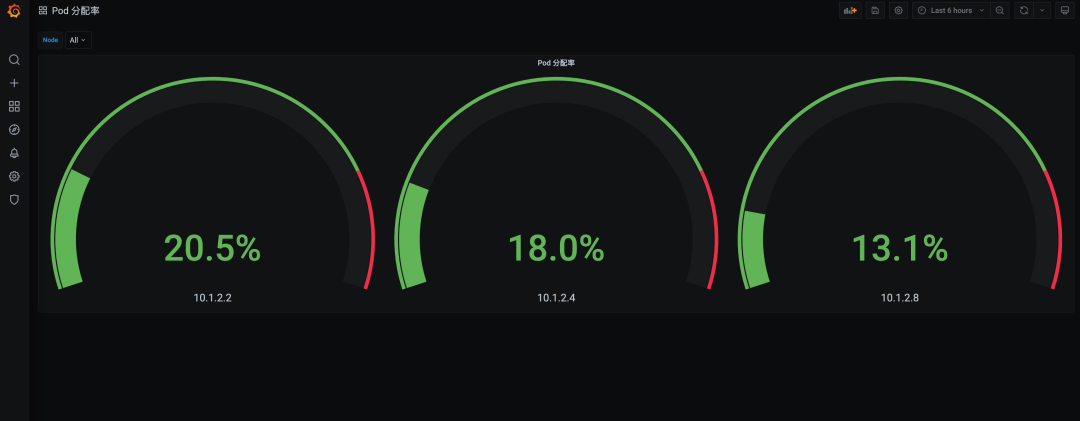

















 4513
4513

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









