







创建DockerFile镜像

你可以通过dockerfile去定义你的容器镜像,包括它的中间件,包括哪些可运行的文件。你可以将一个应用里面所需要的所有依赖,都在dockerfile里面去定义好,docker 本身支持docker build的命令,它会依次去读取Dockerfile里面的这些指令,将这些指令转化为正真的容器镜像。
回顾12Factor之进程(无状态应用)
运行环境中,应用程序通常是以一个和多个进程运行的。(很方便的横向扩展,一个进程跑在这,当你量大了,扛不住了,我再启动一个进程,同时进程出现问题可以随意替换它,无共享,无状态,这样就可以以底层本的方式来管理大量进程)
- 12-Factor 应用的进程必须无状态(Stateless)且无共享(Share nothing)
任何需要持久化的数据都要存储在后端服务内,比如数据库(存储和计算是分离的,任何的数据存储可以晚一点做容器化,可以先将计算的部分容器化,后面数据库有能力了再去做数据库的容器化)
- 应在构建阶段将源代码编译成待执行应用
Session Sticky 是 12-Factor 极力反对的(很多应用希望面向会话的,后面有很多的服务实例,客户端希望永远都到其中一个服务实例当中去,这样的话可以保持会话,可以reuse这些session的信息,但是它希望所有的会话信息,用户信息是放在公共缓存里面)
- Session 中的数据应该保存在诸如 Memcached 或 Redis 这样的带有过期时间的缓存中
Docker 遵循以上原则管理和构建应用。上面就是希望每个提供服务的应用进程它是无状态的,可以随时替换的。
理解构建上下文(Build Context)
- 当运行 docker build 命令时,当前工作目录被称为构建上下文,docker本身会将工作目录里面所有的文件都上传给docker daemon,在这个基础之上再去构建容器镜像。(如果你在根目录去构建容器镜像,将根目录作为构建上下文,那么会相当的慢,它会去检索我所在的当前目录,会将当前目录的所有内容都传输给docker daemon,这样构建的效率会非常的底下)
- docker buildc 默认查找当前目录的 Dockerfile作为构建输入,也可以通过-f指定 Dockerfile。
docker build -f ./Dockerfile
- 当docker build 运行时,首先会把构建上下文传输给docker daemon,把没用的文件包含在构建上下文时,会导致传输时间长,构建需要的资源多,构建出的镜像大等问题。
试着到一个包含文件很多的目录运行下面的命令,会感受到差异:
(1)docker build-f $GOPATH/src/github.com/cncamp/golang/httpserver/Dockerfile
(2)docker build $GOPATH/src/github.com/cncamp/golang/httpserver/
可以通过.dockerignore文件从编译上下文排除某些文件。
- 因此需要确保构建上下文清晰,比如创建一个专门的目录放置 Dockerfile,并在目录中运行docker build。
[root@jenkins dockerfile]# docker build -f ./Dockerfile -t java-demo:v1.1 .
[+] Building 0.1s (7/7) FINISHED docker:default
=> [internal] load build definition from Dockerfile 0.0s
=> => transferring dockerfile: 311B 0.0s
=> [internal] load metadata for docker.io/library/openjdk:8-jdk-alpine 0.0s
=> [internal] load .dockerignore 0.0s
=> => transferring context: 2B 镜像构建日志

Build Cache
构建容器镜像时,Docker 依次读取 Dockerfile 中的指令,并按顺序依次执行构建指令。
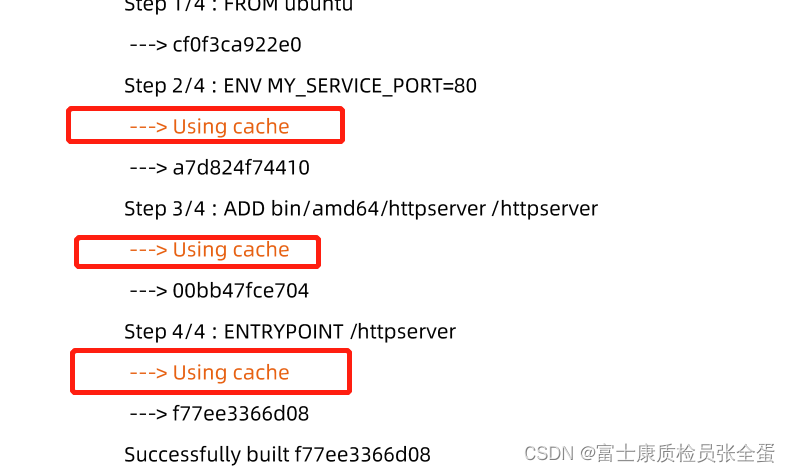
Docker 读取指令后,会先判断缓存中是否有可用的已存镜像,只有已存镜像不存在时才会重新构建。
- 通常 Docker 简单判断 Dockerfile 中的指令与镜像。
- 针对ADD和 COPY 指令,Docker 判断该镜像层每一个文件的内容并生成一个 checksum,与现存镜像比较时,Docker 比较的是二者的 checkSum。
- 其他指令,比如 RUN apt-get -y update,Docker 简单比较与现存镜像中的指令字串是否一致。
- 当某一层 cache 失效以后,所有所有层级的 cache 均一并失效,后续指令都重新构建镜像。(这个是联动的,这就给了我们指导理论,尽量将那些不动的层,很久才会更新的层放在下面,将频繁变更的层放在上面,用来防止一个层失效了,下面所有层都失效,这样可以尽可能的利用缓存,提升构建效率)
合理编排Dockerfile中命令的顺序
在Dockerfile中,每次更改项目代码都会重新下载依赖。那么我们可以把依赖下载安装放到COPY命令的前面,这样更改代码就不会在影响到环境layer(除非更改的是依赖文件),也就省去了环境构建的时间。一句话总结命令顺序的编排规则:越往后的命令,其涉及到的更改频率应该更高。
合理拆分构建命令
RUN命令支持使用 &&组合多个容器内命令,所以可以结合docker的缓存机制,合理的拆分搭配构建命令,加速镜像构建过程
优化依赖构建的命令
如果不可避免的涉及到(apt、pip、npm)依赖频繁的更改,也可以利用缓存机制节省时间。具体方法就是:
RUN \
--mount=type=cache,target=/var/cache/apt \
apt-get update && apt-get install -y git 将cache缓存到本机的文件系统中,下一次环境依赖重新构建就会使用target的依赖缓存。
多段构建(Multi-stage build)

在go语言项目里面,通过某种依赖管理工具去声明说,这个项目依赖于其他1,2,3三个项目,然后当我去构建的时候,要通过管理工具去拉取所有的源代码,然后再去完成整个项目的构建,但是最后是构建完成的二进制文件,中间的源代码其实是不需要的,但是整个编译的过程会将源代码拉取下来,如果不做清理,最终构建出来的容器镜像就将源代码包含进来了。
所以可以通过多段构建去优化,上面是完整的dockerfile,分成了两部分,第一个部分是将git下载下来,之后下载go语言的依赖管理工具dep,之后将依赖的文件拷贝到项目里面,之后下载源文件,这些准备好之后通过go build将源代码编译为二进制的文件。(下载管理工具,下载源码,拷贝依赖的文件)
上面这些步骤其实就有很多东西了,依赖程序dep,我的所有的依赖包,这些东西在生产环境是不需要的,所谓多段构建就是我先去构建这样一个容器镜像,它的产出是/bin/project,但是依赖程序,依赖包,这些东西不是我最终需要的,这时候需要多段构建,再去构建一个新的容器镜像,叫做from scrath,然后它会copy --from=build,将/bin/project拷贝出来,最后是entrypoint。
上面构建方式就是容器在构建的时候,首先会去构建一个容器镜像,其次通过第二段的构建,将其从第一段构建出来的project拷贝出来,最后变为新的容器镜像,这样就抛弃了在编译过程当中中间状态的文件。

user 切换容器默认运行的用户,在安全越来越高的现在,用的越来越频繁了,就是docker默认不切换任何用户的话,它会以root的身份运行容器,也就是在容器内部的所有文件,它是有访问权限的,但是有时候希望容器启动起来之后身份受限,那么可以使用non-root用户了。
总结

可以有个很大的容器镜像,大而全,想用的什么命令都在里面,第一占用空间,其次有安全漏洞。
控制进程数量,理想状态就是只有一个进程,后面管理起来非常简单。















 3068
3068











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









