







kube-proxy

它本身也是控制器模式的组件,基本上任何kubernetes任何组件,它的模式都是一样的,针对kube-proxy来说,它有它所关注的对象,它关注的是service和endpoint以及endpoint slice的变化,它通过操作系统的内核能力来配置负载均衡。
负载均衡最主要的是NAT,是最常见的实现方式,内核协议栈有一定的NAT能力,kube-proxy基于内核的能力实现了网络地址转换,最终达到负载均衡的目的。
内核不会去解应用包,所谓你内核就是给我TCP包,在内核层面只是处理这些TCP包头或者UDP的包头,这个数据包最终会丢回用户态,由用户的应用程序来读取具体的数据的。
所以内核只能处理TCP UDP这层,更加高层的应用层的数据它是碰不到的。
kube-proxy支持几种模式,最早期userspace,相当于用go语言写了一个代理软件,当你访问一个服务,这个服务最终将请求转到kube-proxy里面go语言的负载均衡逻辑,然后由他来决定往哪转。
当你任何的网络调用,你客户端发起的请求都会先交给内核,如果它是在用户态处理负载均衡,它还会从内核态转会用户态,这样反复的跳转对整个网络效率都不高。
所以userspace是一种低效的方式,它只有在你内核没有办法支持所说的网络协议栈的网络地址转化的能力才会去使用。
所谓的iptables和ipvs都是Linux内核协议栈里面,有个框架叫做netfilter,iptables和ipvs是netfilter框架里面不同的plugin。
Linux内核处理数据包:Netfilter框架
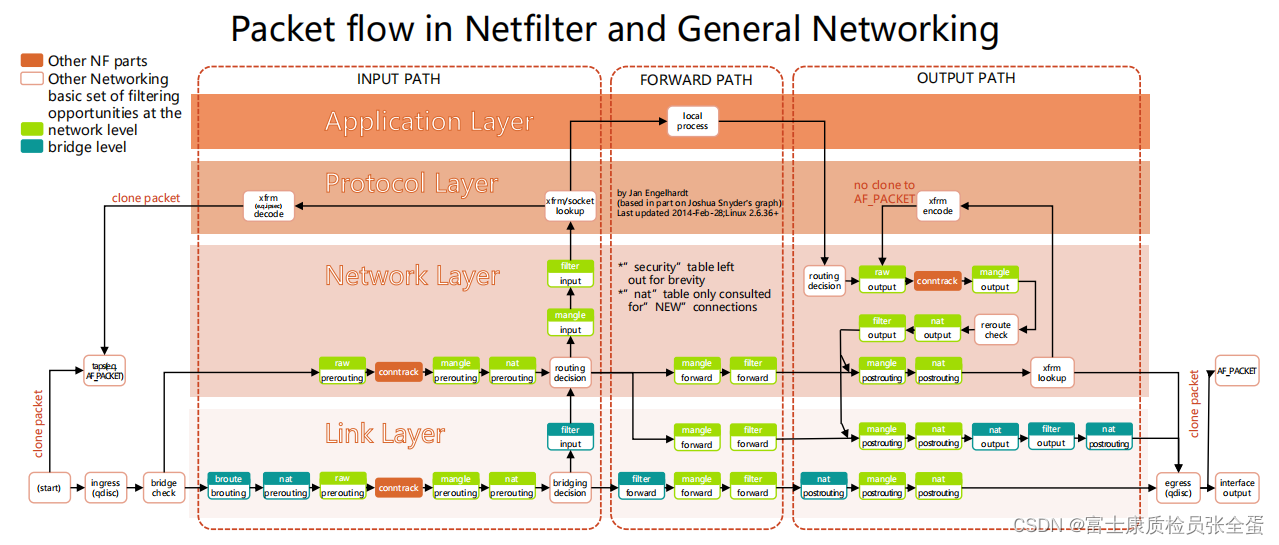
这个图展示是一个数据包,被一个Linux接收到之后,内核在处理这些数据包的时候会经历哪些扭转,这个扭转的框架叫做netfilter。
整个网络的分层为应用层,传输层,网络层,链路层。
应用层跑的是各种用户态的进程,下部分就是内核态,就是由Linux内核去处理数据包的时候可以采取的一些动作。
比如一个数据包被网卡接收到了,链路层接收到数据包之后,如果它是本机的数据包,那么它会将这个包发送到netfilter框架,这个包回去被网络层处理,在处理的时候整个net filter会提供一个一个的hook点,就是一个一个的钩子,在这个钩子里面,这个数据包在处理的时候首先有个柔婷 descision,它会去看这个数据包的五元组,这个数据包里面存的是源IP,源端口,目标IP和端口,以及协议,代表协议的请求和流向。
一个数据包在Linux内核处理的时候,它首先要去判断数据包应该往哪走,是本机要接受的还是不是本机要接受的,如果是我本机的地址,它就会丢到local的process去处理,如果不是它就将包转发出去。
所以在这里就有路由判决,在路由判决前后,它就提供了很多的hook点,所谓的hook点就是一个一个的钩子,它允许你在用户态设置一些规则,它来读取这些规则,这些规则对什么元组的数据我要做什么样的行为。
绿色的方框都是一个一个的hook点,它会去hook点去读取你的用户态配置的规则,来看你这个规则和它现在所处理的数据包是不是一致,规则里面有匹配条件,第二会有行为,如果是防火墙规则,那么就会将数据包丢掉,如果是负载均衡的策略,就需要做类似于网络地址转换,就将目标地址换一下。
我们这里最关心的就是nat和filter,他就是用来修改数据包的,包头里面地址的,所谓的filter,filter一般都是过滤的,所以它就是防火墙规则,nat就是负载均衡的规则。
既然有了这些能力,那么就可以在不同的点上面插入一些不同的规则,然后来控制数据包的流转。
Netfilter和Iptables
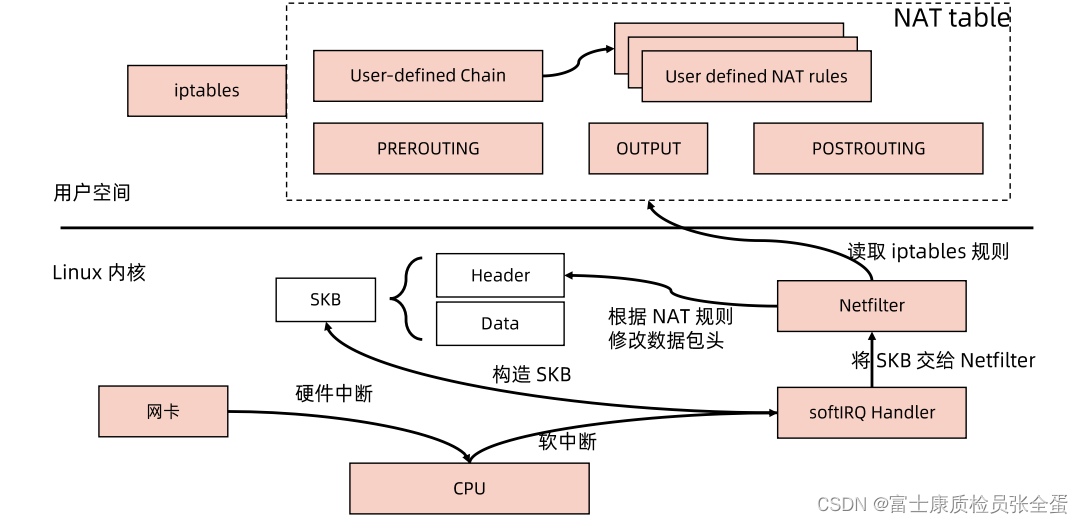
一个数据包被网卡接收到的之后,在用户态Linux允许用户去配置一些具体的规则,如果针对kube-proxy这种目的,我们要去做这种负载均衡的,我们要去访问clusterip,clusterip是一个虚拟地址,用户去访问虚拟地址的时候,要由我们的kube-proxy配置的一些规则将其转到后端真实的pod里面。
所以需要在用户态配置一些nat规则,这些规则要去定义说如果你要访问clusterip,我就要将你的数据包跳转到,也就是将目标地址转换为后端的pod,这是我们需要达到的一个目的,正是iptables支持了这种目的。
一个数据包被网卡接收到之后都是在用户态处理,网卡收到这个包之后,它会发起一个中断,它要告诉cpu我这边有数据包了,cpu不会立刻去读取这些数据,因为cpu被中断之后它就不能响应其他事件了,通常硬件中断要快速结束,所以cpu基本上会响应这个中断,会去调用软中断,在linux里面你可以看到softirqd这样的一些进程,这些进程就是用来处理软中断的,cpu就会去调用softirqd里面的handler来真正的处理数据包。
网卡驱动会通过直接内存访问的方式将这些数据复制到kernel里面某块内存空间。
内存空间里面softirq,会从内存空间里面读取这些数据包,并且构造一个一个的skb,它数据结构叫做skbuffer,skbuffer里面就包含了真实的数据以及header。
构造完数据包之后,skb会被交到netfilter的framework,就是说有这样的数据包了,你需要来处理。
netfilter的framework在处理数据包的时候,它就会去用户态读取配置的iptables规则,如果匹配上执行相应的action,这个action往往都是修改目标地址。
IPtables
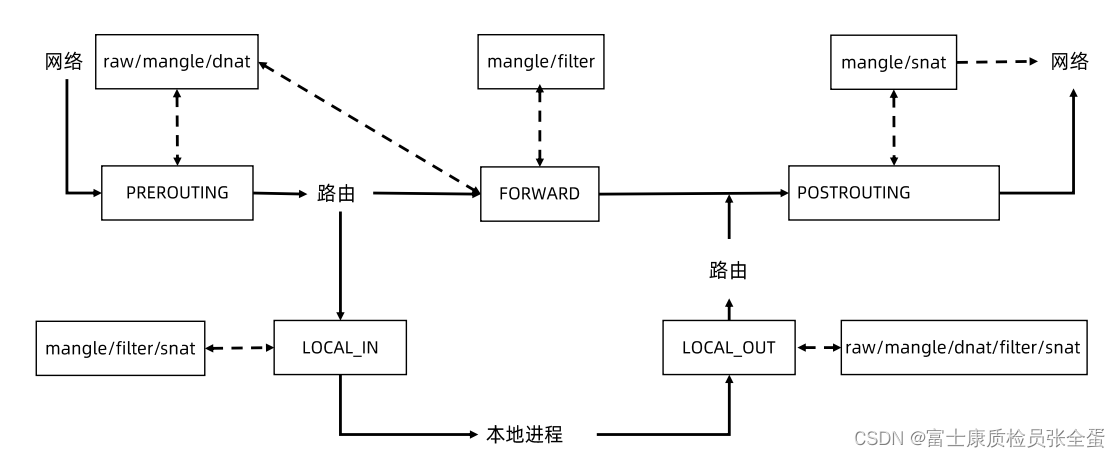
prerouting:就是一个网络包发送过来,在做任何的路判断之前,有个prerouting的hook点,这里面是可以插入iptables规则的。
过了prerouting之后就是系统去做路由判断的,他会去判断如果包的目标地址是我本机的,它会走local_in的这个hook,这里面又会有一些hook点可以插入iptables规则。local_in进来之后就会被本地程序处理,如果发现地址不是本机地址,他就会走forward表把这个包丢出去。
如果是本地进程要往外发请求,作为一个客户端往外发请求,它就会走local_out,在进行路由判决之后,有个post routing,这个网络包就出去了。
我们要改写目标地址,希望将clusterip改为真实的pod ip,我们就需要找到dnat去哪里做,prerouting是可以去做dnat的。
kube-proxy工作原理
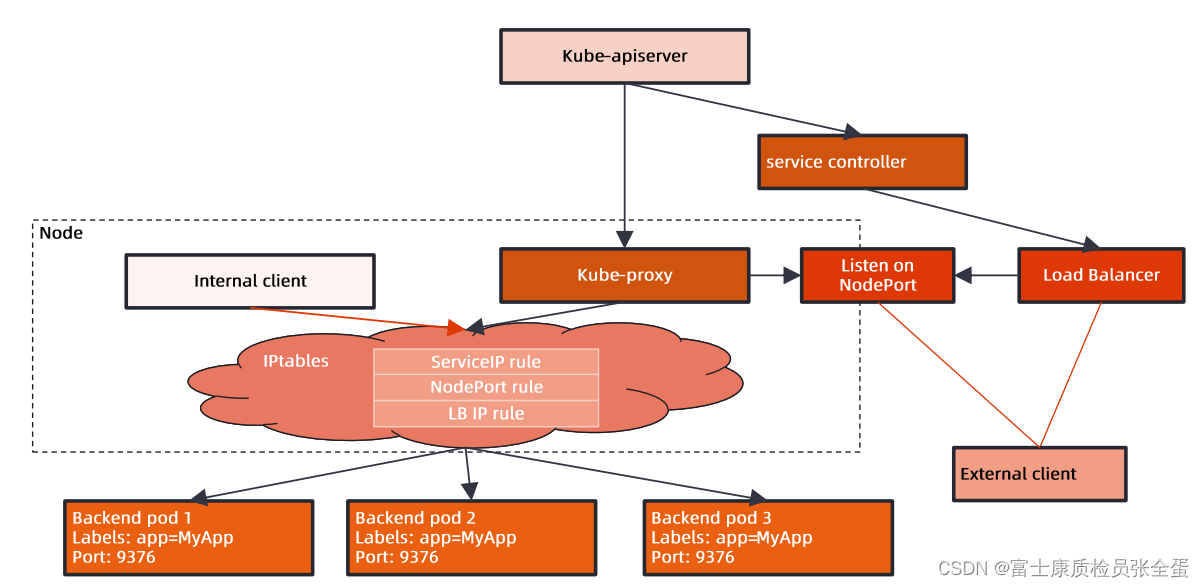
kube-proxy是工作在每个节点上面的组件,它会去watch apiserver,watch apiserver之后kube-proxy,假设kube-proxy工作在iptables模式下面,它就会去调用iptables的命令,去生成这样一些规则,无非就是说你的目标IP是某个clusterIP,那我就应该去写一些dnat的跳转规则,让后端数据包的目标地址变为后端pod的IP地址,这是kube-proxy希望去实现的一个目标。
经过IP tables之后,你访问cluster ip,你要将数据包转到后端的pod里面去,这是我们要达到的一个目的。
kubernetes IP tables规则
一个包进来或者出去之后,它都是怎么流转的,这就是kube-proxy配置的一些具体的规则。
对于任何iptables规则来说,当我们去加一条规则的时候,通常会去指定几个属性,-A就是iptables里面会有chain和rule的概念,所谓的chain就是一些规则的组合,一个链下面可以有一堆的规则,这些规则是自上而下一条一条执行的。

这里面就是说希望往KUBE-SERVICE链里面加入一些规则,这些规则前面的部分都是匹配规则,后面的部分是action,如果匹配了,后面需要做什么样的事情,如果你对数据包的目标地址,目标地址是164.239,如果你的协议是TCP,如果你的端口是80,那么我就要去执行KUBE-SVV-WWR....这个动作。
这个动作是什么呢?它也是一个chain,这个chain里面的行为会有多条rule,也就是一条chain里面有多条规则。就是随机的按照33%的机率,让它执行这个chain里面的action,以50%执行这个,然后100%去执行最后一个action。

这里面定义了三个action,这三个action分别以35% 50% 100%的几率去命中,iptables规则是自上而下的,如果我有三条这样的规则,那意味着如果它进入到这里,它会使用33%几率去执行第一个action,如果第一个没有命中,那么会以50%几率去执行这一条action,如果50%都没有撞到的话,如果50%都没有撞到的话,它就会以100%几率来执行这个action。

百分之33几率命中这个规则LTL,这个规则它会去做DNAT,就是有33%转到这个pod,50%几率转到ZHE这个规则,这个规则是165, 如果上面两条规则都没有命中那么会以100%几率转到167。
iptables规则是自上而下执行的,它是以几率命中的这种方式来决定说到底由哪个后端的pod来处理这个请求,它会按照33% 50% 100%这样的几率依次去碰撞。
如果碰撞到了就由前面的规则执行,如果没有撞到由后面的规则兜底,就是这样的工作原理。
这个chain和原生的linux kernel里面内置的hook点是怎么产生绑定关系的呢?可以看到将kube-service这个chain加入到pretouting和output这两个hook点里面,
也就意味着,所有进入到Linux内核的数据包,以及linux系统里面的进程,向外发起请求的这些数据包全部都需要走kube-servcie,那么就意味着任何请求都会经过这些规则去处理。

假设本地有一个pod,要去访问nginx-basic这个服务,这个数据包意味是从本地的pod发出的,所以它先要走本地的kernel的output表,output就会去执行kube-service,走kube-service就会去看如果你的clusterip是符合我刚才service的clusterip的话,它就会经由展示的那些规则一个一个去命中。命中的话就将clusterip换成了目标pod的IP,这样就完成了一个负载均衡的目标,这一切是在k8s节点的主机网络空间里面去做的。

IPVS

iptables是kube-proxy工作的一种模式,它本身是有一些问题的,它的问题是对于任何负载均衡的配置都需要很多的配置去堆叠,负载均衡的策略有点粗犷,比如30% 50% 100%,这种按照几率去命中就意味着数据包的转发一定不会高效,假设你有1w个pod在后面,你的iptables规则是怎么样的,它的值到底是百分之多少呢?如果是自上而下的命中,那么就意味着一些包要经过1w条规则的过滤,然后hit到了一个兜底的规则,这样就一定决定了数据包的转发效率会非常低的。
因为iptables是很早以前为人的手工服务的,它可能一些基本的防火墙规则,一个linux上面几条规则就搞定了,kubernetes用的iptables规则之后,就很迅速的规则将iptables规则从几条,几十条变为了几千几万条,这样数据包的整个转发效率就不会高了,还有iptables要刷新这些规则的时候,kube_proxy没有做增量的检查,它是将原来整个的iptables规则清空掉,然后重新刷。
如果量很大,那么整个刷新的效率会非常的低下。
也就是说在iptables规则下,整个集群的规模不能太大,service不能太多,service对应的pod也不能太多,这样的话就有了一些限制。
ipvs是netfilter另外一种工作模式,另外一种plugin,ipvs本身是lvs的一部分,或者说二者是可以等价的,lvs更多的是为负载均衡服务,所以对nat网络包的处理,有更好的支持。
ipvs和iptables不一样,它所支持的hook点不一样,它没有prerouting的支持,它只有local_in的支持,有local_out的支持,只有local int out可以让我们去添加一些规则。
因为iptables模式下面,当你去访问clusterip,在做路由判决之前就将目标地址换掉了,进来的数据包是通过prerouting去做的dnat,这个时候路由判决还没有做,所以那个clusterip可以不绑在任何的路由设备上面,在路由判决的时候那个IP已经变成了pod的真实IP。
针对ipvs来说,从外面发进来的一个包,由Linux kernel来处理,如果访问的是clusterIP,那么在prerouting这里是没有ipvs的hook点的,也就是路由判决的时候,这个ip还是你service对应的clusterip,也就说在路由判决的时候,linux kernel会去判断,你所访问的目标地址,是不是在我本机一个有效地址,如果是无效就将这个包丢掉,针对ipvs模式,有一个额外的操作,要将所有的service cluster ip绑在当前节点的dump设备上面,这样的话才能判断我这个本机上面是有这个IP的,它是一个有效IP,又因为它是本机的,它会走到local_in这个hook点,在这里就可以插入一些ipvs规则的。
出去的包也一样在local_out去做。
这是本质的区别,针对ipvs这种模式,你的clusterip是要绑在本机的某个interface上面的。














 1458
1458











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









