







对于非结构化的数据存储系统来说,LIST 操作通常都是非常重量级的,不仅占用大量的磁盘 IO、网络带宽和 CPU,而且会影响同时间段的其他请求(尤其是响应延迟要求极高的 选主请求),是集群稳定性的一大杀手。
例如,对于 Ceph 对象存储来说,每个 LIST bucket 请求都需要去多个磁盘中捞出这个 bucket 的全部数据;不仅自身很慢,还影响了同一时间段内的其他普通读写请求,因为 IO 是共享的,导致响应延迟上升乃至超时。如果 bucket 内的对象非常多(例如用作 harbor/docker-registry 的存储后端),LIST 操作甚至都无法在常规时间内完成( 因而依赖 LIST bucket 操作的 registry GC 也就跑不起来)。
又如 KV 存储 etcd。相比于 Ceph,一个实际 etcd 集群存储的数据量可能很小(几个 ~ 几十个 GB),甚至足够缓存到内存中。但与 Ceph 不同的是,它的并发请求数量可能会高几个量级,比如它是一个 ~4000 nodes 的 k8s 集群的 etcd。单个 LIST 请求可能只需要 返回几十 MB 到上 GB 的流量,但并发请求一多,etcd 显然也扛不住,所以最好在前面有 一层缓存,这就是 apiserver 的功能(之一)。K8s 的 LIST 请求大部分都应该被 apiserver 挡住,从它的本地缓存提供服务,但如果使用不当,就会跳过缓存直接到达 etcd,有很大的稳定性风险。
本文深入研究 k8s apiserver/etcd 的 LIST 操作处理逻辑和性能瓶颈,并提供一些基础服务的 LIST 压力测试、 部署和调优建议,提升大规模 K8s 集群的稳定性。
kube-apiserver LIST 请求处理逻辑:
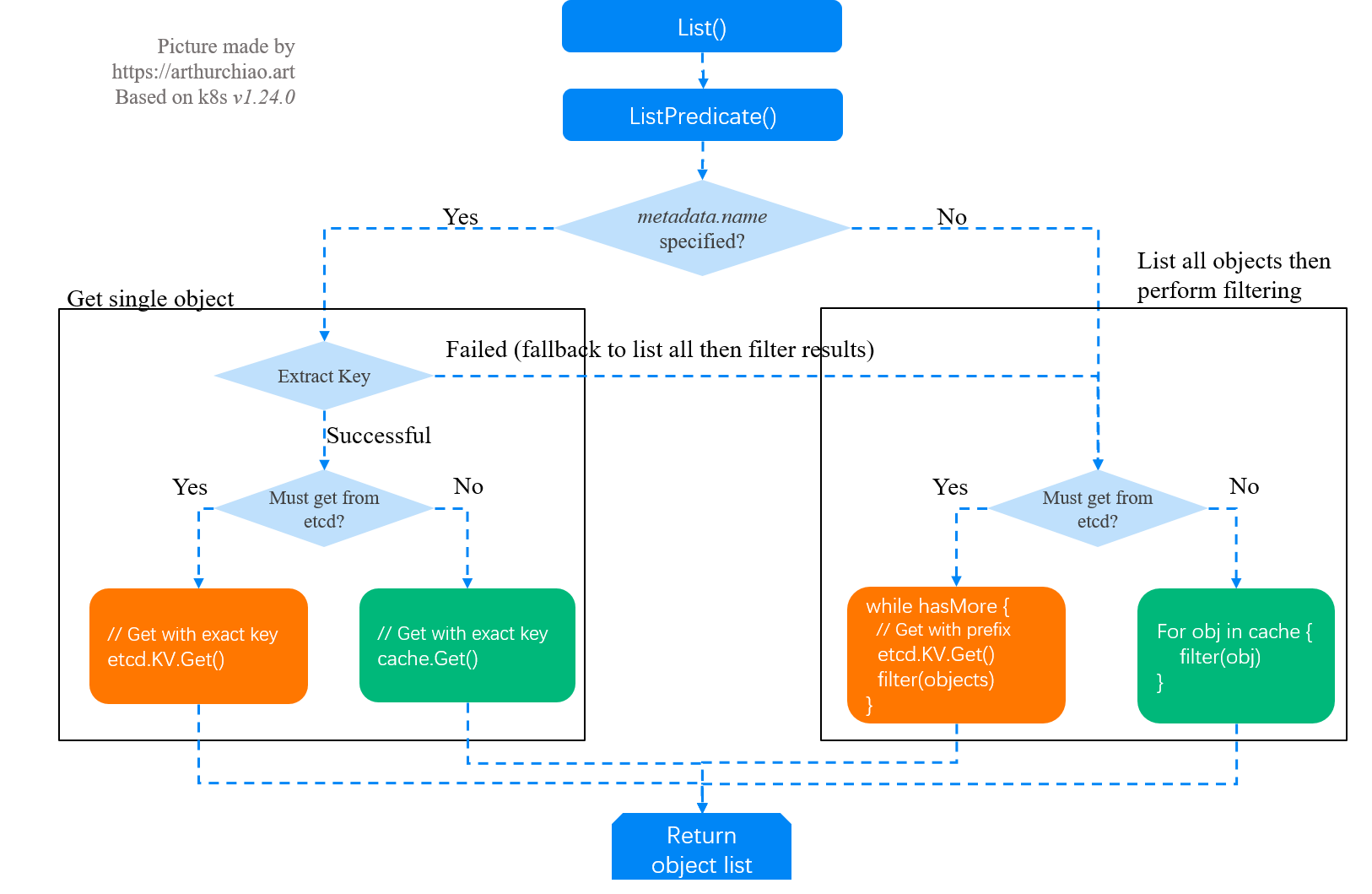
分页查询

很多时候etcd里面存储的对象是非常多的,如果任何的查询都要将全量返回回来,你可想而知开销有多大,我们希望在做操作的时候返回output的量,在查询数据库的时候不能全量返回,要做分页查询。
那么我们去get某个对象的时候,kubelet其实默认加了一个限制,叫做limit,limit其实默认是查询500个,返回前500之后,返回的list里面会给你一个continue的token,k8s会按照这个token继续往下查下一部分。
所以做大数据查询的时候,基本上都是通过这种方式去做分页查询的,先返回500给你一个token,下次加上continue token,它就知道这次查询的时候是和上次连接起来的,它就会将下一批发送给你。
新的查询又会给你新的continue token,你带着新的continue token它就会给你返回1000-1500。
通过这样机制就做了分页查询的支持。
ResourceVersion

resource version到底怎么使用,我们任何的对象都有resource version,可以看到为204,所以单个对象的resourceversion就是对象最后修改的时间,之前说过最后修改时间就是它的mode version,这个对象会被创建,会被修改,他的mode reversion就是当这个对象修改的时候这个etcd里面reversion的增长的值,注意不同的对象的reversion是公用同一个增长序列的,这个reversion是整个集群增长的,不同的对象它的mode reversion就是它最后修改一次的reversion,这个reversion就是当你查询对象它显示的resourceversion。
再来回顾乐观锁,当两个控制器要去修改一个对象的时候,那么这两个进程拿到的是当前这个对象的mode reversion,当一个进程要去修改它,这个请求先发过去了,修改对象resource version也就是mode reversion,和etcd里面是一样的,这个请求被接受并且被修改了,那么这个对象的mode reversion是发生变化了的,这个时候第二个请求再发过去,它基于老的mode reversion,在这个请求被etcd处理的时候他就会发现你是基于老版本,我现在已经增长了,所以你这个请求是不合法的,它就给你返回409 conflict,这个时候客户端有责任去拉去新的版本,包括新的reversion,在那个基础之上重新做修改。

如果list对象的时候,不加resource version,这就意味着告诉apiserver说我不相信你的cache,你要把最新的数据还给我,就会导致请求穿透apiserver,直接到etcd,在写代码的时候一定要注意。
当使用label去做对象过滤查询的时候,这个过滤时在apiserver做的,etcd本身是没有过滤能力的,所以apiserver依然会将全量请求发送到etcd里面,发过来以后再apiserver这边做过滤。
上面是容易出问题的点。
1 引言
1.1 K8s 架构:环形层次视图
从架构层次和组件依赖角度,可以将一个 K8s 集群和一台 Linux 主机做如下类比:
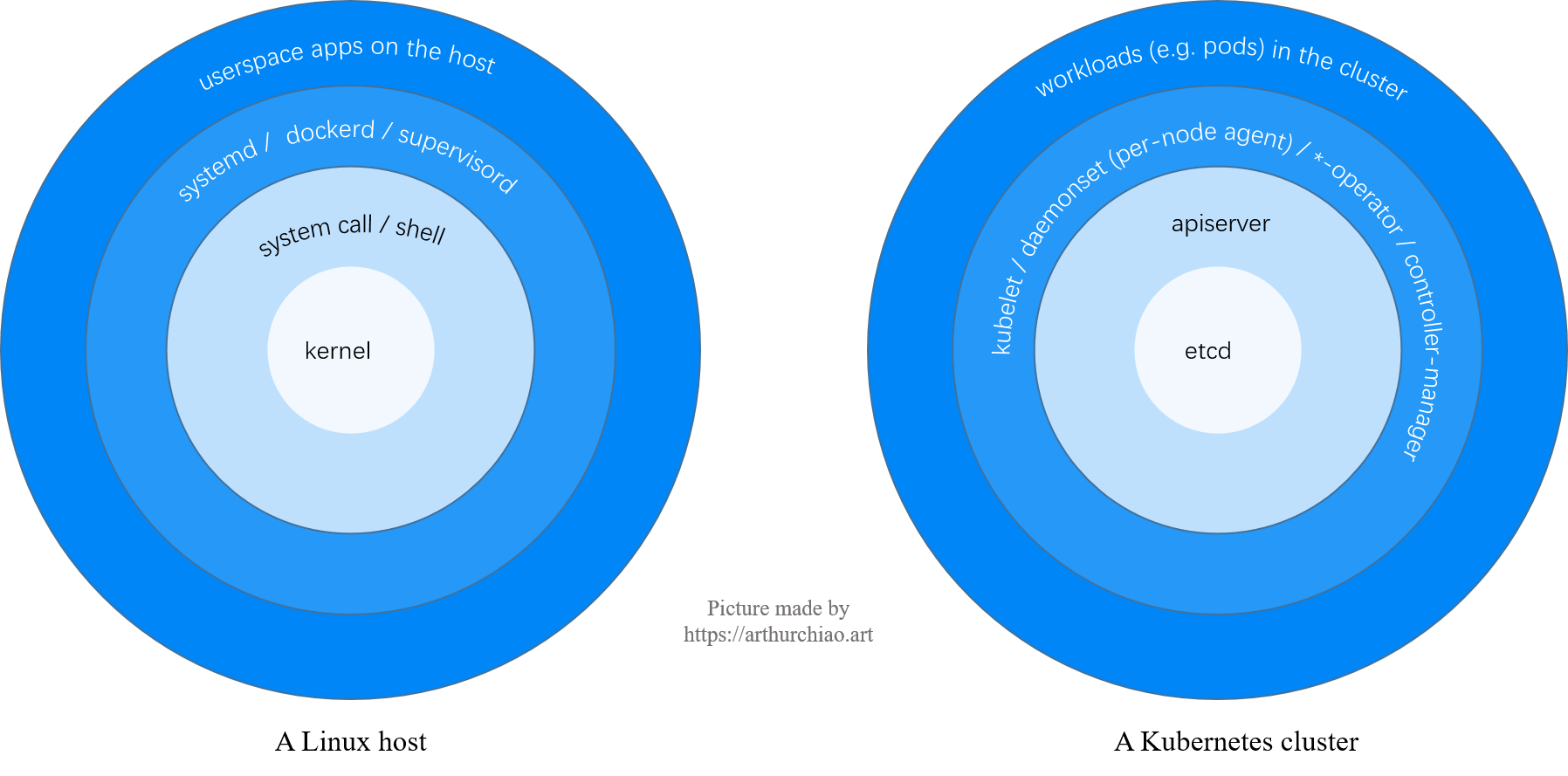
Fig 1. Anology: a Linux host and a Kubernetes cluster
对于 K8s 集群,从内到外的几个组件和功能:
- etcd:持久化 KV 存储,集群资源(pods/services/networkpolicies/…)的唯一的权威数据(状态)源;
- apiserver:从 etcd 读取(
List Watch)全量数据,并缓存在内存中;无状态服务,可水平扩展; - 各种基础服务(e.g.
kubelet、*-agent、*-operator):连接 apiserver,获取(List/ListWatch)各自需要的数据; - 集群内的 workloads:在 1 和 2 正常的情况下由 3 来创建、管理和 reconcile,例如 kubelet 创建 pod、cilium 配置网络和安全策略。
1.2 apiserver/etcd 角色
以上可以看到,系统路径中存在两级 List/ListWatch(但数据是同一份):
- apiserver List/ListWatch etcd
- 基础服务 List/ListWatch apiserver
因此,从最简形式上来说,apiserver 就是挡在 etcd 前面的一个代理(proxy),
+--------+ +---------------+ +------------+
| Client | -----------> | Proxy (cache) | --------------> | Data store |
+--------+ +---------------+ +------------+
infra services apiserver etcd
- 绝大部分情况下,apiserver 直接从本地缓存提供服务(因为它缓存了集群全量数据);
-
某些特殊情况,例如,
- 客户端明确要求从 etcd 读数据(追求最高的数据准确性),
- apiserver 本地缓存还没建好
apiserver 就只能将请求转发给 etcd —— 这里就要特别注意了 —— 客户端 LIST 参数设置不当也可能会走到这个逻辑。
1.3 apiserver/etcd List 开销
1.3.1 请求举例
考虑下面几个 LIST 操作:
-
LIST apis/cilium.io/v2/ciliumendpoints?limit=500&resourceVersion=0这里同时传了两个参数,但
resourceVersion=0会导致 apiserver 忽略limit=500, 所以客户端拿到的是全量 ciliumendpoints 数据。一种资源的全量数据可能是比较大的,需要考虑清楚是否真的需要全量数据。 后文会介绍定量测量与分析方法。
-
LIST api/v1/pods?filedSelector=spec.nodeName%3Dnode1这个请求是获取
node1上的所有 pods(%3D是=的转义)。根据 nodename 做过滤,给人的感觉可能是数据量不太大,但其实背后要比看上去复杂:
- 首先,这里没有指定 resourceVersion=0,导致 apiserver 跳过缓存,直接去 etcd 读数据;
- 其次,etcd 只是 KV 存储,没有按 label/field 过滤功能(只处理
limit/continue),所以,apiserver 是从 etcd 拉全量数据,然后在内存做过滤,开销也是很大的,后文有代码分析。
这种行为是要避免的,除非对数据准确性有极高要求,特意要绕过 apiserver 缓存。
-
LIST api/v1/pods?filedSelector=spec.nodeName%3Dnode1&resourceVersion=0跟 2 的区别是加上了
resourceVersion=0,因此 apiserver 会从缓存读数据,性能会有量级的提升。但要注意,虽然实际上返回给客户端的可能只有几百 KB 到上百 MB(取决于 node 上 pod 的数量、pod 上 label 的多少等因素), 但 apiserver 需要处理的数据量可能是几个 GB。 后面会有定量分析。
以上可以看到,不同的 LIST 操作产生的影响是不一样的,而客户端看到数据还有可能只是 apiserver/etcd 处理数据的很小一部分。如果基础服务大规模启动或重启, 就极有可能把控制平面打爆。
1.4 大规模部署时潜在的问题
再来看个例子,下面这行代码用 k8s client-go 根据 nodename 过滤 pod,
podList, err := Client().CoreV1().Pods("").List(ctx(), ListOptions{FieldSelector: "spec.nodeName=node1"})
看起来非常简单的操作,我们来实际看一下它背后的数据量。 以一个 4000 node,10w pod 的集群为例,全量 pod 数据量:
- etcd 中:紧凑的非结构化 KV 存储,在 1GB 量级;
- apiserver 缓存中:已经是结构化的 golang objects,在 2GB 量级( TODO:需进一步确认);
- apiserver 返回:client 一般选择默认的 json 格式接收, 也已经是结构化数据。全量 pod 的 json 也在 2GB 量级。
可以看到,某些请求看起来很简单,只是客户端一行代码的事情,但背后的数据量是惊人的。 指定按 nodeName 过滤 pod 可能只返回了 500KB 数据,但 apiserver 却需要过滤 2GB 数据 —— 最坏的情况,etcd 也要跟着处理 1GB 数据 (以上参数配置确实命中了最坏情况,见下文代码分析)。
集群规模比较小的时候,这个问题可能看不出来(etcd 在 LIST 响应延迟超过某个阈值后才开始打印 warning 日志);规模大了之后,如果这样的请求比较多,apiserver/etcd 肯定是扛不住的。
1.5 本文目的
通过深入代码查看 k8s 的 List/ListWatch 实现,加深对性能问题的理解,对大规模 K8s 集群的稳定性优化提供一些参考。















 4761
4761











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









