







goroutine 看一个需求
需求:要求统计1-200000000000的数字中,哪些是素数?
分析思路:
1)传统的方法,就是使用一个循环,循环的判断各个数是不是素数(一个任务就分配给一个cpu去做,这样很不划算,而且非常慢)
2)使用并发或者并行的方式,将统计素数的任务分配给多个goroutine去完成,这时就会使用到goroutine(速度和核数有关)
goroutine可以做一个并发和并行处理,可以让一个很大的任务分解到各个goroutine去完成。
进程和线程说明
(1)进程就是程序程序在操作系统中的一次执行过程,是系统进行资源分配和调度的基本单位
(2)线程是进程的一个执行实例,是程序执行的最小单元,它是比进程更小的能独立运行的基本单位。
(3)一个进程可以创建核销毁多个线程,同一个进程中的多个线程可以并发执行。
(4)一个程序至少有一个进程,一个进程,至少有一个线程
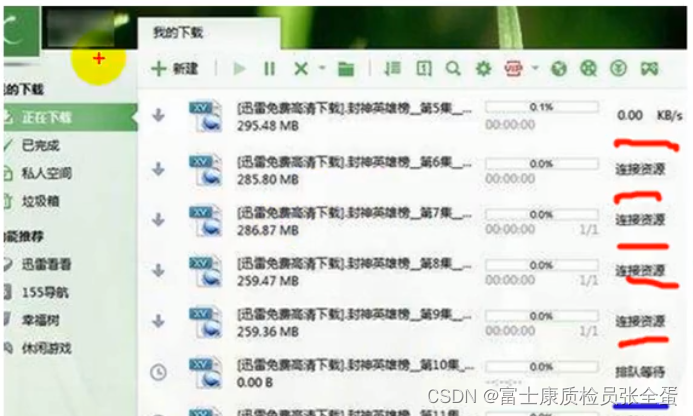
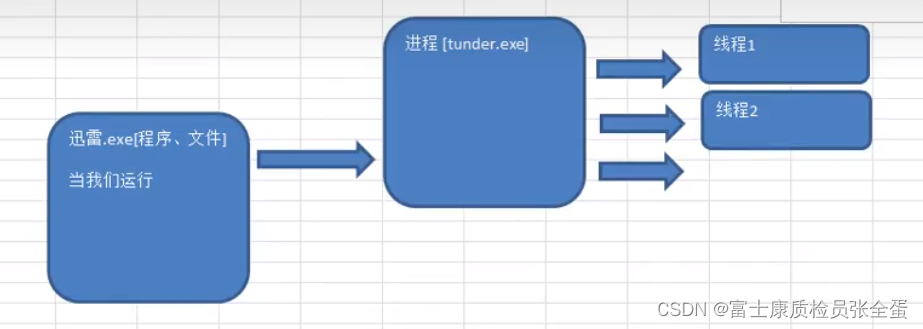
双击迅雷就会启动一个进程,一个迅雷可以下载多个文件。每个下载任务可以看成一个线程,这样才能够发挥cpu最大的一个性能。
并发,不是并行,从效果上说好像是5个同时下载,其实就是时间片很短,从微观的角度看其实就是一个时间点只有一个文件在下载。
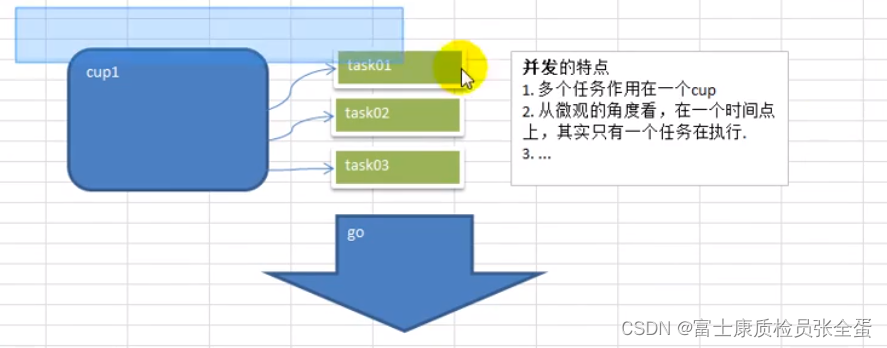
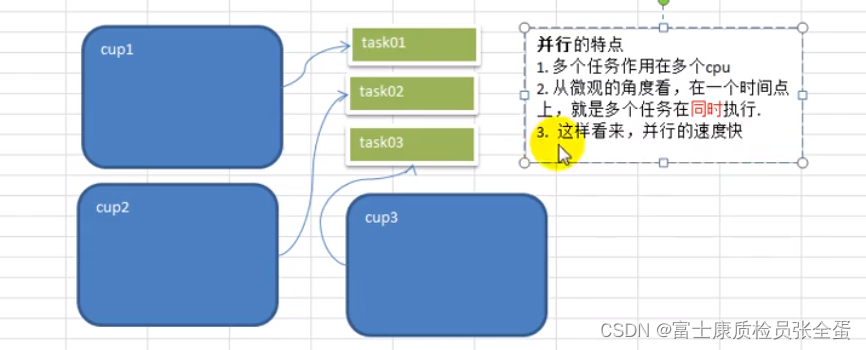
并发和并行
1)多线程程序在单核上运行,就是并发
2)多线程程序在多核上运行,就是并行
并发:因为是在一个cpu上,比如有10个线程,每个线程执行10毫秒(进行轮询操作),从人的角度看,好像这10个线程都在运行,但是从微观上看,在某一个时间点看,其实只有一个线程在执行,这就是并发。
并行:因为是在多个cpu上(比如有10个cpu),比如有10个线程,每个线程执行10毫秒(各自在不同cpu上执行),从人的角度看,这10个线程都在运行,但是从微观上看,在某一个时间点看,也同时有10个线程在执行,这就是并行。
传统的编程语言,即使有多任务也是分配在一个cpu上面的,这样多核是不能发挥威力。go语言就是要将并发转化为并行。
协程是一个更加轻量级的线程
Thead vs.Groutine
1.创建时默认的stack的大小
- JDK5以后Java Thread stack默认为1M
- Groutine的Stack初始化大小为2K,创建起来也会更加快
2.和KSE(Kernel Space Entity)的对应关系
- Java Thread是1:1
- Groutine是M:N
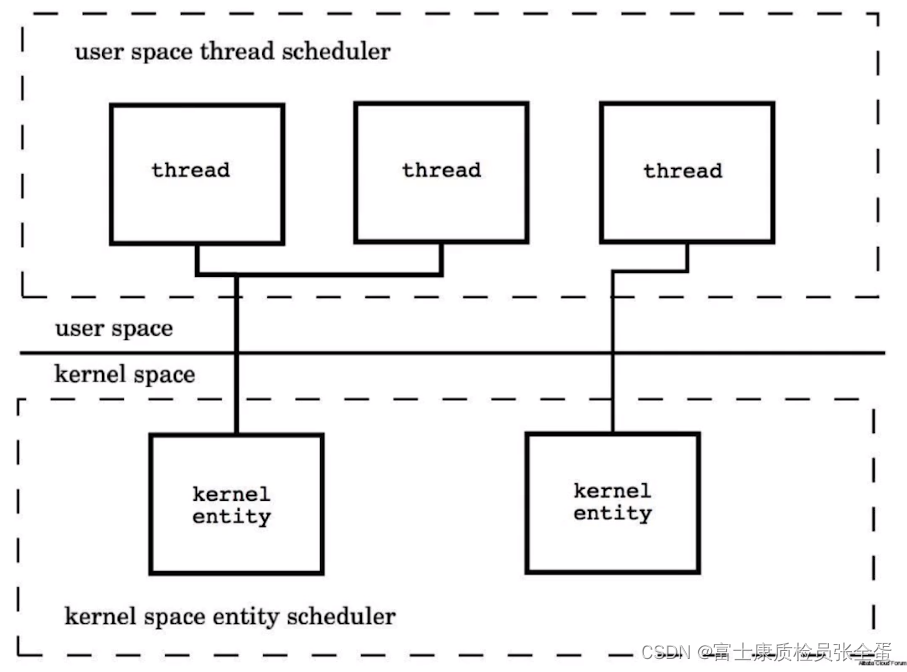
如果是1:1,系统线程是由cpu直接进行调度的,那么调度的效率非常的高。但是这里会存在一个问题就是如果线程之间发生了切换,那么会牵扯到内核对象的切换,这就是一件非常消耗的事。
如果m:n 多个协程或者线程都在一个系统线程里面,或者说和一个系统内核对象对应,那么它们之间的切换消耗就会小非常多。
- M系统线程,也就是kennel entity。
- process并不是真正意义上的处理器,而是go语言实现的协程处理器。
- G就是协程了。
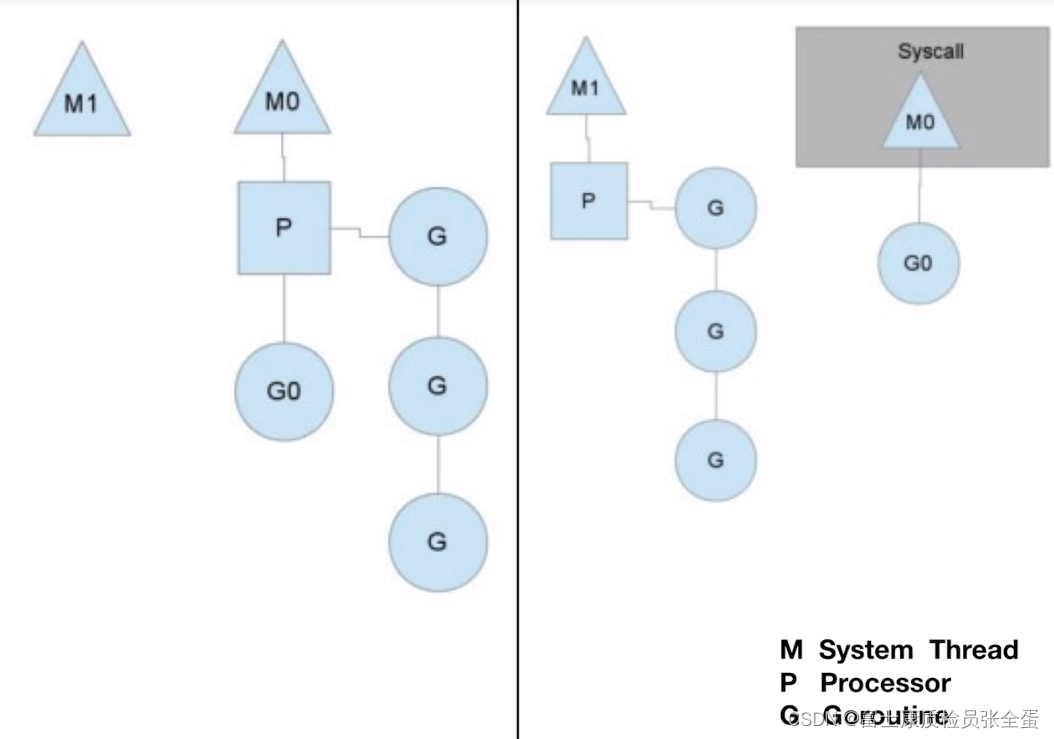
process在不同的系统线程里面,但是每个process都挂载着准备运行的协程队列。可以有一个协程是在运行状态的,这个process就依次运行协程。
如果一个协程运行的时间特别长,将整个process都占有了,那么队列里面的协程会被延迟的很久了。
在go起来的时候会有一个守护线程做一个计数,记录每个process运行完成协程的数量,当有段时间发现某个process完成协程的数量没有发生变化,他就会往协程任务栈里面插入一个特殊的标记。
这个标记会将这个协程中断下来,插入到等待协程的队尾。然后切换为别的协程进一步继续运行。
当某一个协程被系统中断了,就是I/O需要等待的时候,为了提高整体的并发,所以这个process会将自己移到另外一个可以使用的系统线程当中,继续执行挂载在队列里的其他协程。当这个被终端的协程完全被唤醒之后,那么它会将自己加入到某个process的协程等待队列里,或者全局等待队列当中。
当一个协程被中断在寄存器里面的状态也会保存在协程对象里,当协程再次获得运行的机会这些又会被重新写到寄存器里面继续运行。
这样就可以看到协程和系统线程多对多的关系。以及如何来高效利用系统线程来尽量多的运行并发协程任务。















 2512
2512











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









