







数据压缩是提高 Web 站点性能的一种重要手段。对于有些文件来说,高达 70% 的压缩比率可以大大减低对于带宽的需求。随着时间的推移,压缩算法的效率也越来越高,同时也有新的压缩算法被发明出来,应用在客户端与服务器端。
在实际应用时,web 开发者不需要亲手实现压缩机制,浏览器及服务器都已经将其实现了,不过他们需要确保在服务器端进行了合理的配置。数据压缩会在三个不同的层面发挥作用:
- 首先某些格式的文件会采用特定的优化算法进行压缩
- 其次在 HTTP 协议层面会进行通用数据加密,即数据资源会以压缩的形式进行端到端传输
- 最后数据压缩还会发生在网络连接层面,即发生在 HTTP 连接的两个节点之间
文件格式压缩
每一种文件类型都会存有冗余,也就是浪费的空间。如果一个典型的文本文件存在 60% 的冗余的话,那么对于其他类型的文件,例如音频或视频文件来说,这个比率会更高。不同于文本文件,这些其他类型的媒体文件占据的空间也更大,所以很早就出现了回收这些浪费的空间的需求。工程师们设计了可以应用于特定用途的文件类型的经过优化的算法。用于文件的压缩算法可以大致分为两类:
- 无损压缩。在压缩与解压缩的循环期间,不会对要恢复的数据进行修改。复原后的数据与原始数据是一致的(比特与比特之间一一对应)。对于图片文件来说,
gif或者png格式的文件就是采用了无损压缩算法。 - 有损压缩。在压缩与解压缩的循环期间,会对原始数据进行修改,但是会(希望)以用户无法觉察的方式进行。网络上的视频文件通常采用有损压缩算法,
jpeg格式的图片也是有损压缩。
一些特定的文件格式既可以采用无损压缩算法,又可以采用有损压缩算法,例如 webp,并且有损压缩算法可以对压缩比率进行配置,当然这会导致压缩品质的不同。为了使一个站点获得更好的性能,理想情况是在保持可以接受的品质水准的前提下,压缩比率尽可能得高。对于图片来说,通过压缩工具生成的图片对于 Web 应用来说,优化程度可能依然不够高。
端到端压缩技术
对于各种压缩手段来说,端到端压缩技术是 Web 站点性能提升最大的地方。端到端压缩技术指的是消息主体的压缩是在服务器端完成的,并且在传输过程中保持不变,直到抵达客户端。不管途中遇到什么样的中间节点,它们都会使消息主体保持原样。

所有的现代浏览器及服务器都支持该技术,唯一需要协商的是所采用的压缩算法。这些压缩算法是为文本内容进行过优化的。在上世纪 90 年代,压缩技术快速发展,为数众多的算法相继出现,扩大了可选的范围。如今只有两种算法有着举足轻重的地位:gzip 应用最广泛,br 则是新的挑战者。
为了选择要采用的压缩算法,浏览器和服务器之间会使用主动协商机制。浏览器发送 Accept-Encoding 标头,其中包含有它所支持的压缩算法,以及各自的优先级,服务器则从中选择一种,使用该算法对响应的消息主体进行压缩,并且发送 Content-Encoding 标头来告知浏览器它选择了哪一种算法。由于该内容协商过程是基于编码类型来选择资源的展现形式的,在响应时,服务器至少发送一个包含 Accept-Encoding 的 Vary 标头以及该标头;这样的话,缓存服务器就可以对资源的不同展现形式进行缓存。
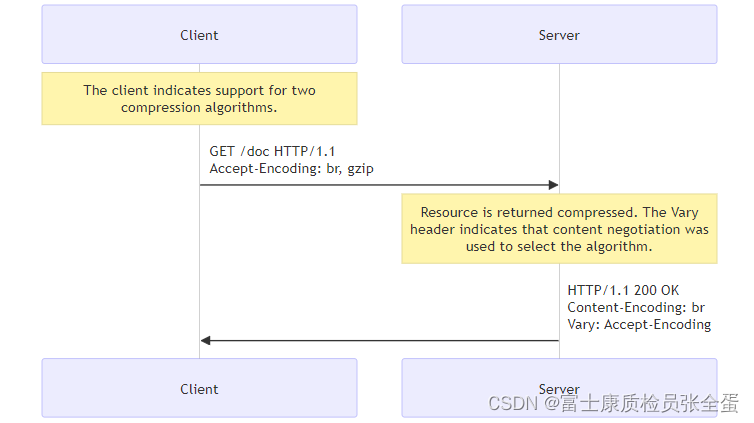
由于压缩技术可以带来很大的性能提升,建议对除了已经经过压缩的文件如图片、音频和视频文件之外的其他类型的文件均进行压缩。
Apache 服务器支持数据压缩,有 mod_deflate可供使用;nginx 中有ngx_http_gzip_module 模块;在 IIS 中则可以使用 <httpCompression> 元素。
Accept-Encoding
Accept-Encoding 请求 HTTP 标头表示客户端能够理解的内容编码(通常是某种压缩算法)。服务器使用内容协商从中选择一个提议,并通过 Content-Encoding 响应标头告知客户端这一选择。
即使客户端和服务器都支持相同的压缩算法,在 identity 值可以被接受的情况下,服务器也可以选择不对响应体进行压缩。导致出现这种情况的常见原因有两个:
- 要发送的数据已经经过压缩,再次压缩不会减少传输的数据量。这适用于预先压缩过的图像格式(如 JPEG)。
- 服务器过载,无法分配计算资源来进行压缩。例如,微软建议如果服务器使用超过其计算能力的 80%,则不应进行压缩。
只要 identity;q=0 或 *;q=0 指令不明确禁止表示无编码的 identity 值,服务器就绝对不应返回 406 Not Acceptable 错误。
Accept-Encoding: gzip
Accept-Encoding: compress
Accept-Encoding: deflate
Accept-Encoding: br
Accept-Encoding: zstd
Accept-Encoding: identity
Accept-Encoding: *// 使用质量价值语法对多个算法进行加权:
Accept-Encoding: deflate, gzip;q=1.0, *;q=0.5
Content-Encoding
实体消息首部 Content-Encoding 列出了对当前实体消息(消息荷载)应用的任何编码类型,以及编码的顺序。它让接收者知道需要以何种顺序解码该实体消息才能获得原始荷载格式。Content-Encoding 主要用于在不丢失原媒体类型内容的情况下压缩消息数据。
请注意原始媒体/内容的类型通过 Content-Type 首部给出,而 Content-Encoding 应用于数据的表示,或“编码形式”。如果原始媒体以某种方式编码(例如 zip 文件),则该信息不应该被包含在 Content-Encoding 首部内。
一般建议服务器应对数据尽可能地进行压缩,并在适当情况下对内容进行编码。对一种压缩过的媒体类型如 zip 或 jpeg 进行额外的压缩并不合适,因为这反而有可能会使荷载增大。
语法
Content-Encoding: gzip Content-Encoding: compress Content-Encoding: deflate Content-Encoding: br // 多个,按应用的编码顺序列出 Content-Encoding: deflate, gzip
客户端可以事先声明一系列可以支持的压缩模式,与请求一齐发送。Accept-Encoding 这个首部就是用来进行这种内容编码形式协商的:
-
Accept-Encoding: gzip, deflate
服务器在 Content-Encoding 响应首部提供了实际采用的压缩模式:
-
Content-Encoding: gzip
需要注意的是,服务器端并不强制要求一定使用何种压缩模式。采用哪种压缩方式高度依赖于服务器端的设置,及其所采用的模块。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









