






版本: cs5
效果:

做法:
新建分项-彩色模板-方框形式,选择与图片底色相同颜色(白色)
放在视频上方,起始位置打点位置:
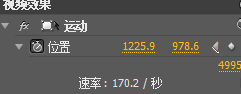
拖动方框全部盖住视频字幕

点击彩色模板的结束位置,将模板框拖到最右侧直到不挡住字幕
完成。
版本: cs5
效果:
做法:
新建分项-彩色模板-方框形式,选择与图片底色相同颜色(白色)
放在视频上方,起始位置打点位置:
拖动方框全部盖住视频字幕
点击彩色模板的结束位置,将模板框拖到最右侧直到不挡住字幕
完成。

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言























 1621
1621







