







wor2vec 讲解
结合三个我看过的比较好的网站,这里我重新整理和总结一下word2vec的一些基本原理。
公式讲解清楚:https://plmsmile.github.io/2017/11/12/cs224n-notes1-word2vec/
图讲解清楚:http://www.hankcs.com/nlp/word2vec.html#h3-12
有一个实际的小例子怎么用而不是公式:cs224n第二章的PPT
符号定义
一定要先明白每个符号的意义,有时候看paper看着看着就蒙圈,最后发现问题就出在自己没有一开始就把所有符号定义单独写出来,导致公式推着推着就不理解了。
针对每个词汇,我们主要学习以下两个参数:
U:映射矩阵1(shape:VXd)
V:映射矩阵2(shape:dXV)
理解这里比较重要,因为u,v不过只是UV中的某一行,所以实际上最后想要的就是这两个映射矩阵
u:上下文单词向量
v:中心单词向量
x:词汇表向量,长度为V的01变量
N:词汇表的长度
ω i \omega_i ωi:词汇表第i个单词
d:映射后的向量维度(即我们希望的维度)
U:映射矩阵1(shape:VXd)
V:映射矩阵2(shape:dXV)
u i u_i ui:U的第i行,就是u
v i v_i vi:V的第i行,就是v
m:窗口大小
c:中心词汇位置
在这里还有一个概念要描述清楚:
词向量和上下文向量:我们希望的到有意义的稠密向量
词汇表向量:指由词汇表构造的稀疏01向量。
CBOW
输入:上下文向量
输出:当前位置词向量
流程图如下:
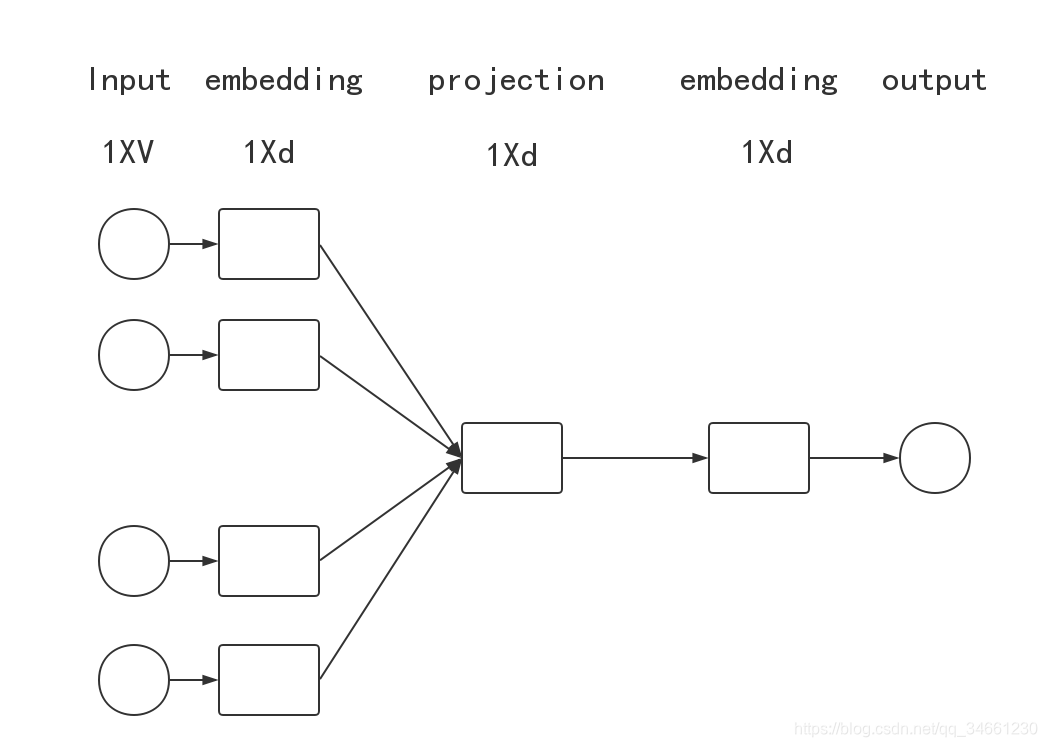
需要注意的是就是有两个个embedding映射的过程,这在很多教程里面都省略了这一步,导致会有些混淆。实际上我们要求的也是这个两个映射矩阵
求解流程
1.获得输入变量
得到一系列的(
x
c
−
m
x^{c-m}
xc−m …
x
c
+
m
x^{c+m}
xc+m)上下文词汇表向量,共2m个,维度1XV
2.通过映射层转换为上下文向量(稠密向量)
通过xV得到
(
v
c
−
m
,
v
c
−
m
+
1
,
.
.
.
,
v
c
+
m
)
(v_{c-m},v_{c-m+1},...,v_{c+m})
(vc−m,vc−m+1,...,vc+m)上下文向量,共2m个,维度(1XV)X(VXd)=(1Xd)
3.通过投影层转换为平均上下文词向量
v
^
=
v
c
m
+
.
.
.
v
c
+
m
2
m
\hat v=\frac{v_{c_m}+...v_{c+m}}{2m}
v^=2mvcm+...vc+m
4.计算得分向量
z
=
U
v
^
z=U\hat v
z=Uv^
矩阵点积,发现其实公式的意义是v与U中的每个V进行点积的结果。(word2vec采用点积计算单词相似性,单词越相似,得分越高)
5.得分向量转换为概率向量
y
^
=
R
(
z
)
\hat y=R(z)
y^=R(z)
这里一开始R采用的是softmax函数,即
z
c
=
e
U
c
v
^
∑
j
N
e
U
j
v
^
z_c=\frac {e^{U_c\hat v}}{\sum^N_j e^{U_j\hat v}}
zc=∑jNeUjv^eUcv^
6.计算损失函数
采用交叉熵
J
=
−
∑
j
N
y
j
l
o
g
(
y
^
j
)
J=-\sum^N_jy_jlog(\hat y_j)
J=−j∑Nyjlog(y^j)
注意这里只是一个样本的cost而已,即j是指各个维度
由于y是01变量,只有当j==c的时候为1,其余均为0
因此
J
=
−
l
o
g
(
y
^
c
)
J=-log(\hat y_c)
J=−log(y^c)
7.SGD的梯度求导
U
c
U_c
Uc要考虑分子和分母的求导,而
U
k
U_k
Uk(除c外的其他)只需要考虑分母的求导,所以分开,写代码的时候可以将他们进行一个合并。
∂
J
∂
v
=
∑
i
N
e
x
p
(
u
i
v
)
∑
j
N
e
x
p
(
u
j
v
)
u
i
−
u
c
\frac{\partial J}{\partial v}=\sum^N_i\frac{exp(u_iv)}{\sum^N_j exp(u_jv)}u_i-u_c
∂v∂J=i∑N∑jNexp(ujv)exp(uiv)ui−uc
∂
J
∂
U
c
=
e
x
p
(
u
c
v
)
∑
j
N
e
x
p
(
u
j
v
)
v
−
v
\frac{\partial J}{\partial U_c}=\frac{exp(u_cv)}{\sum^N_j exp(u_jv)}v-v
∂Uc∂J=∑jNexp(ujv)exp(ucv)v−v
∂
J
∂
U
k
=
e
x
p
(
u
c
v
)
∑
j
N
e
x
p
(
u
j
v
)
v
\frac{\partial J}{\partial U_k}=\frac{exp(u_cv)}{\sum^N_j exp(u_jv)}v
∂Uk∂J=∑jNexp(ujv)exp(ucv)v
Skip-gram
输入:当前位置词向量
输出:上下文向量
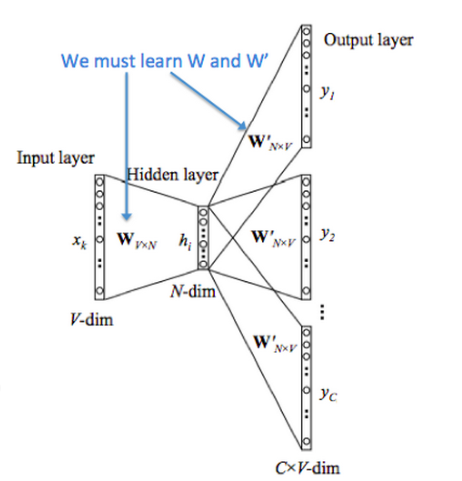
有了前面的思想,skip-gram的原理就好理解了。
特点:
- 没有投影层,直接传递
- CBOW输出的是c位置的概率,skip-gram输出的是c-m…c+m 共2m位置的概率。
求解步骤
1.获得输入变量
得到中心单词的词汇表向量,x,维度是VX1
2.通过映射层转换为上下文向量(稠密向量)
通过xV得到v向量,维度(1XV)X(VXd)=(1Xd)
3.没有投影层直接传递
4.计算得分向量
z
=
U
v
z=U v
z=Uv
矩阵点积,发现其实公式的意义是v与U中的每个V进行点积的结果。(word2vec采用点积计算单词相似性,单词越相似,得分越高)
5.得分向量转换为概率向量
y
^
=
R
(
z
)
\hat y=R(z)
y^=R(z)
这里一开始R采用的是softmax函数,即
z
c
=
e
U
c
v
^
∑
j
N
e
U
j
v
z_c=\frac {e^{U_c\hat v}}{\sum^N_j e^{U_jv}}
zc=∑jNeUjveUcv^
6.计算损失函数
采用交叉熵
由于它预测的是2m个的目标上下文单词是中心单词的概率
J
=
−
l
o
g
P
(
w
c
−
m
.
.
.
w
c
−
1
,
w
c
+
1
,
.
.
.
w
c
+
m
)
J=-logP(w_{c-m}...w_{c-1},w_{c+1},...w_{c+m})
J=−logP(wc−m...wc−1,wc+1,...wc+m)
采取上下文无关的假设(缺陷没有考虑词的相互位置顺序)
J
=
−
l
o
g
∏
j
=
0
,
j
≠
m
2
m
P
(
w
c
−
m
+
j
∣
w
c
)
J=-log\prod_{j=0,j\neq m}^{2m}P(w_{c-m+j}|w_c)
J=−logj=0,j̸=m∏2mP(wc−m+j∣wc)
化简,就是2m个交叉熵的和,即总误差
7.SGD求导
这里就不求了,因为后面要换negative_sample
计算实例如下:
只是注意W和
W
′
W^{'}
W′不是同一个东西

negative_sample
softmax函数,会有一个计算复杂的问题,就是公式下方的求和,需要计算词汇表中的V次,而V往往会很大。
因为就提出了negative_sample,就是取词汇表中其他位置的K个单词,这K个单词为负样本,采用sigmod函数。
改动的只是损失函数
CBOW
J
=
−
log
σ
(
u
c
T
⋅
v
^
)
−
∑
k
=
1
K
log
σ
(
−
u
ˉ
k
T
⋅
v
^
)
J = - \log \sigma (u_c^T \cdot \hat v) - \sum_{k=1}^K \log \sigma (- \bar u_k^T \cdot \hat v)
J=−logσ(ucT⋅v^)−k=1∑Klogσ(−uˉkT⋅v^)
skip-gram
J
=
−
∑
j
=
0
,
j
≠
m
2
m
log
σ
(
u
c
−
m
+
j
T
⋅
v
c
)
−
∑
k
=
1
K
log
σ
(
−
u
ˉ
k
T
⋅
v
c
)
J = - \sum_{j=0, j \neq m}^{2m} \log \sigma (u_{c-m+j}^T \cdot v_c) - \sum_{k=1}^K \log \sigma (-\bar u_{k}^T \cdot v_c)
J=−j=0,j̸=m∑2mlogσ(uc−m+jT⋅vc)−k=1∑Klogσ(−uˉkT⋅vc)
求导代码
想知道自己求导的形式对不对,我觉得看代码是最好的,毕竟代码不仅把公式求对了,而且还考虑了一些优化的情况。
不管是CBOW还是skip-gram 其内层损失函数的形式是一致的,因此只用实现一次
softmaxCost
def softmaxCostAndGradient_sol(predicted, target, outputVectors, dataset):
""" Softmax cost function for word2vec models """
# Implement the cost and gradients for one predicted word vector
# and one target word vector as a building block for word2vec
# models, assuming the softmax prediction function and cross
# entropy loss.
# Inputs:
# - predicted: numpy ndarray, predicted word vector (\hat{v} in
# the written component or \hat{r} in an earlier version)
# - target: integer, the index of the target word
# - outputVectors: "output" vectors (as rows) for all tokens
# - dataset: needed for negative sampling, unused here.
# Outputs:
# - cost: cross entropy cost for the softmax word prediction
# - gradPred: the gradient with respect to the predicted word
# vector
# - grad: the gradient with respect to all the other word
# vectors
# We will not provide starter code for this function, but feel
# free to reference the code you previously wrote for this
# assignment!
### YOUR CODE HERE
probabilities = softmax(predicted.dot(outputVectors.T))
cost = -np.log(probabilities[target])
delta = probabilities
delta[target] -= 1# 这个减一很重要,推导的时候发现式子可以合并减1的
N = delta.shape[0]
D = predicted.shape[0]
grad = delta.reshape((N,1)) * predicted.reshape((1,D))
gradPred = (delta.reshape((1,N)).dot(outputVectors)).flatten()
### END YOUR CODE
return cost, gradPred, grad
negSampling
def negSamplingCostAndGradient_sol(predicted, target, outputVectors, dataset,
K=10):
""" Negative sampling cost function for word2vec models """
# Implement the cost and gradients for one predicted word vector
# and one target word vector as a building block for word2vec
# models, using the negative sampling technique. K is the sample
# size. You might want to use dataset.sampleTokenIdx() to sample
# a random word index.
#
# Note: See test_word2vec below for dataset's initialization.
#
# Input/Output Specifications: same as softmaxCostAndGradient
# We will not provide starter code for this function, but feel
# free to reference the code you previously wrote for this
# assignment!
### YOUR CODE HERE
grad = np.zeros(outputVectors.shape)
gradPred = np.zeros(predicted.shape)
indices = [target]
for k in range(K):
newidx = dataset.sampleTokenIdx()
while newidx == target:
newidx = dataset.sampleTokenIdx()
indices += [newidx]
labels = np.array([1] + [-1 for k in range(K)])
vecs = outputVectors[indices,:]
t = sigmoid(vecs.dot(predicted) * labels)
cost = -np.sum(np.log(t))
delta = labels * (t - 1)
gradPred = delta.reshape((1,K+1)).dot(vecs).flatten()
gradtemp = delta.reshape((K+1,1)).dot(predicted.reshape(
(1,predicted.shape[0])))
for k in range(K+1):
grad[indices[k]] += gradtemp[k,:]
# t = sigmoid(predicted.dot(outputVectors[target,:]))
# cost = -np.log(t)
# delta = t - 1
# gradPred += delta * outputVectors[target, :]
# grad[target, :] += delta * predicted
# for k in range(K):
# idx = dataset.sampleTokenIdx()
# t = sigmoid(-predicted.dot(outputVectors[idx,:]))
# cost += -np.log(t)
# delta = 1 - t
# gradPred += delta * outputVectors[idx, :]
# grad[idx, :] += delta * predicted
### END YOUR CODE
return cost, gradPred, grad
其他
关于求导
1.当初我在看公式的时候,发现一个很奇怪的东西,为什么求导需要对损失函数里的所有参数都求导,没有x的吗?
认真查看后发现,原来是有x的是,只是x被省略掉了而已,因为v=Vx的,只是x是01变量,所以不影响而已。

















 1264
1264

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









