






 本文详细介绍了如何使用Python的Scrapy框架爬取双色球开奖数据,并将其保存至CSV、MySQL和MongoDB数据库,包括项目创建、爬虫逻辑、数据存储管道的实现和运行过程。
本文详细介绍了如何使用Python的Scrapy框架爬取双色球开奖数据,并将其保存至CSV、MySQL和MongoDB数据库,包括项目创建、爬虫逻辑、数据存储管道的实现和运行过程。
使用Scrapy爬取双色球开奖数据:CSV、MySQL和MongoDB存储解决方案 🎲📊
在本篇文章中,我们将探讨如何使用Python的Scrapy框架爬取双色球开奖数据,并将这些数据保存到CSV文件、MySQL数据库以及MongoDB数据库中。通过这个实战项目,你不仅能够学会如何创建和运行一个Scrapy爬虫,还能掌握数据存储的多种实用技术。
创建Scrapy项目
首先,我们需要创建一个Scrapy项目。在终端或命令提示符中,导航到你希望创建项目的目录,并运行以下命令:
scrapy startproject caipiao
接着,为目标网站500.com生成一个爬虫:
cd caipiao
scrapy genspider shuangseqiu 500.com
编写爬虫逻辑
在生成的shuangseqiu爬虫文件中,我们定义了爬虫的解析逻辑,用于从双色球开奖数据页面提取期号、红球和蓝球数据:
import scrapy
from caipiao.items import CaipiaoItem
class ShuangseqiuSpider(scrapy.Spider):
name = "shuangseqiu"
allowed_domains = ["500.com"]
start_urls = ["https://datachart.500.com/ssq/"]
def parse(self, response):
tr_list = response.xpath("//tbody[@id='tdata']/tr")
for tr in tr_list:
if tr.xpath("./@class").extract_first() == "tdbck":
continue
red_ball = tr.xpath("./td[@class='chartBall01']/text()").extract()
blue_ball = tr.xpath("./td[@class='chartBall02']/text()").extract_first()
qh = tr.xpath("./td[1]/text()").extract_first()
yield CaipiaoItem(name="双色球", qihao=qh, red_ball=red_ball, blue_ball=blue_ball)
Item实体类
在items.py中,我们定义了用于存储爬取数据的CaipiaoItem实体类:
import scrapy
class CaipiaoItem(scrapy.Item):
name = scrapy.Field()
qihao = scrapy.Field()
red_ball = scrapy.Field()
blue_ball = scrapy.Field()
数据存储方案
CSV文件存储
我们在pipelines.py中定义了CaipiaoPipeline,用于将爬取的数据保存到CSV文件中:
class CaipiaoPipeline:
def open_spider(self, spider):
self.f = open("双色球.csv", "a", encoding="utf-8")
def close_spider(self, spider):
self.f.close()
def process_item(self, item, spider):
self.f.write(f"{item['name']},{item['qihao']},{','.join(item['red_ball'])},{item['blue_ball']}\n")
return item
MySQL数据库存储
MysqlPipeline类实现了将数据存储到MySQL数据库的逻辑:
class MysqlPipeline:
def open_spider(self, spider):
import pymysql
self.conn = pymysql.connect(
host="localhost", user="root", password="123456", database="python", charset="utf8")
self.cursor = self.conn.cursor()
print("爬虫开始了")
def close_spider(self, spider):
self.cursor.close()
self.conn.close()
print("爬虫结束了")
def process_item(self, item, spider):
# 将红球列表转换成逗号分隔的字符串
red_ball_str = ','.join(item['red_ball'])
# SQL语句
sql = "insert into shuangseqiu(name, qihao, red_ball, blue_ball) values(%s, %s, %s, %s)"
# 执行SQL语句,注意将红球列表转换后的字符串传递给SQL
self.cursor.execute(sql, (item['name'], item['qihao'], red_ball_str, item['blue_ball']))
self.conn.commit()
return item
MongoDB数据库存储
MongDBPipeline类实现了将数据存储到MongoDB数据库的逻辑:
class MongDBPipeline:
def open_spider(self, spider):
from pymongo import MongoClient
self.client = MongoClient("mongodb://localhost:27017/")
self.db = self.client["caipiao"] # 创建数据库
self.collection = self.db["shuangseqiu"] # 创建集合
print("爬虫开始了")
def close_spider(self, spider):
self.client.close()
print("爬虫结束了")
def process_item(self, item, spider):
self.collection.insert_one(dict(item))
return item
启用管道
在settings.py中启用上述定义的管道:
ITEM_PIPELINES = {
'caipiao.pipelines.CaipiaoPipeline': 300,
'caipiao.pipelines.MongDBPipeline': 299,
'caipiao.pipelines.MysqlPipeline': 298,
}
建表语句
CREATE TABLE `python`.`shuangseqiu` (
`name` varchar(255) NULL,
`qihao` varchar(255) NULL,
`red_ball` varchar(255) NULL,
`blue_ball` varchar(255) NULL
);
运行爬虫
最后,运行爬虫,开始爬取双色球开奖数据:
scrapy crawl shuangseqiu
保存结果
csv
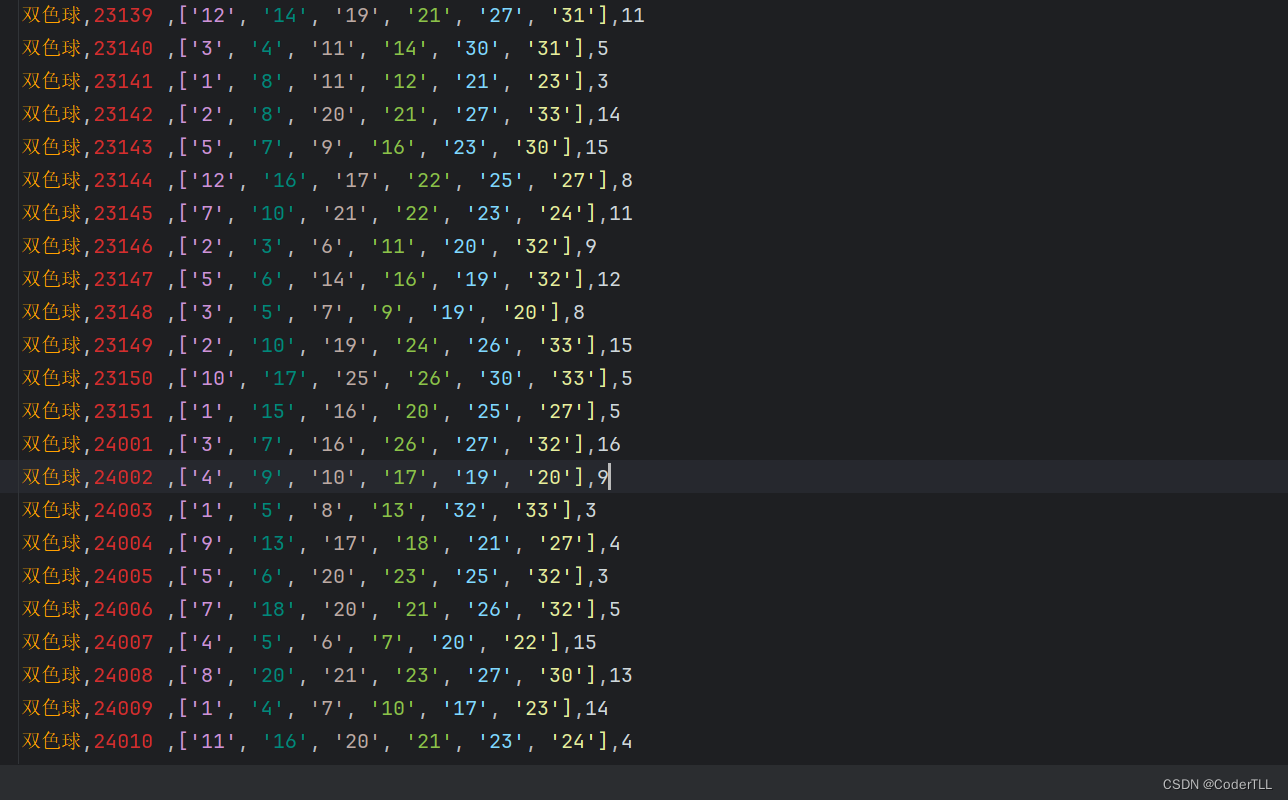
mysql
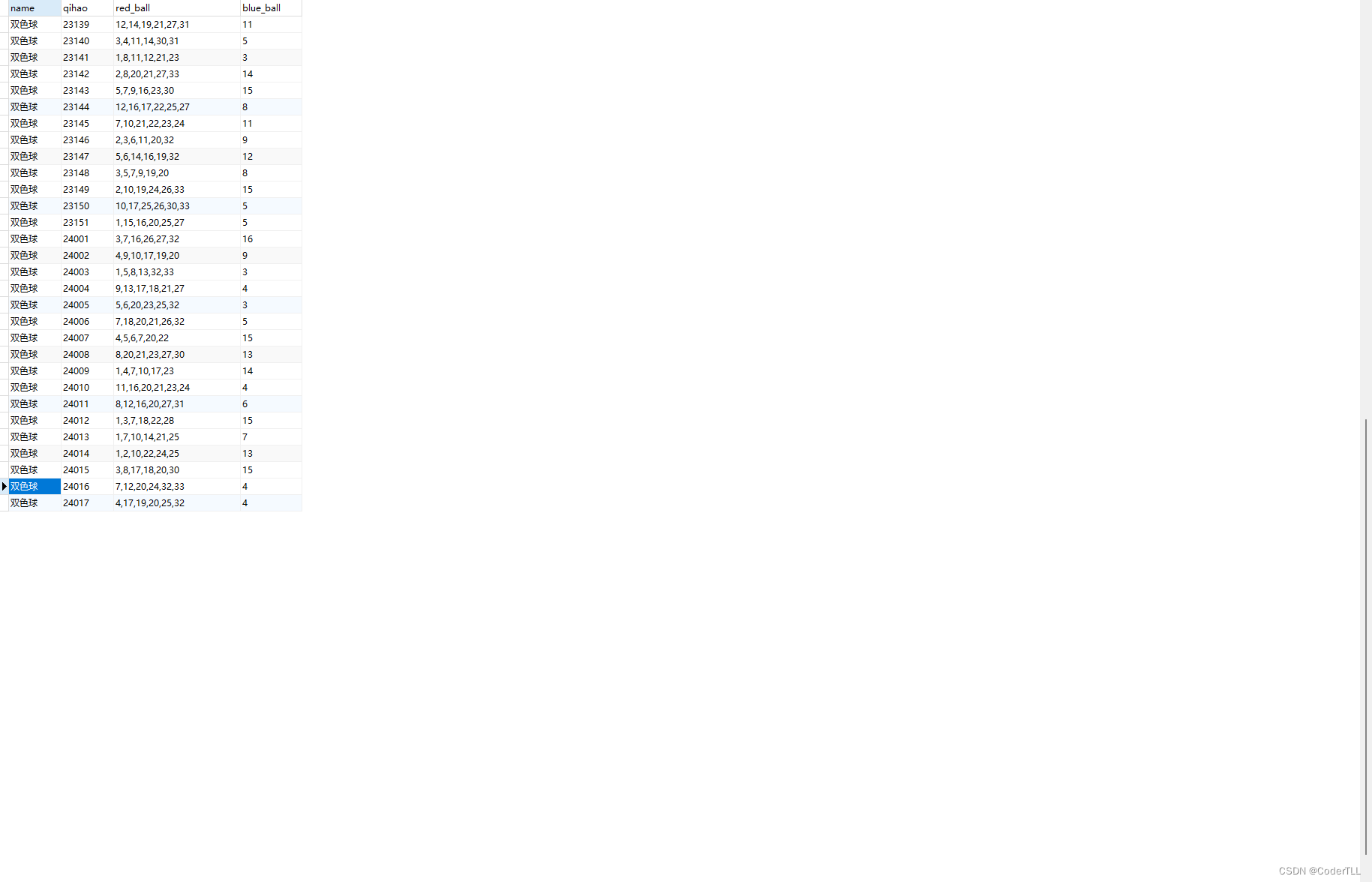
MongoDB

免责声明 ⚠️
本文提供的代码和操作指南仅供学习和研究目的使用。在实际应用中,请严格遵守相关法律法规和目标网站的使用政策。未经允许,不得将爬取的数据用于商业或其他非法用途。作者不承担因使用本文内容而引发的任何法律责任或其他后果。
结语 🌟
通过本文的介绍,你现在应该对如何使用Scrapy框架爬取网页数据,并将数据存储到CSV文件、MySQL和MongoDB数据库中有了一个基本的了解。Scrapy的强大功能和灵活性使其成为处理复杂数据爬取任务的理想选择。
希望这篇文章能够帮助你入门Scrapy,并在数据爬取的领域中迈出坚实的一步。Scrapy的学习之路充满了无限的可能性和挑战,希望你能够不断探索,发现更多的知识和技巧。
如果你觉得这篇文章对你有所帮助,不妨给个👍点赞支持一下。同时,也欢迎关注和收藏,这样你就不会错过更多精彩内容。你的支持是我不断前进和分享的动力!
最后,如果有任何问题或想法,欢迎在评论区留言交流。让我们一起学习,一起进步!

















 589
589

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









