







一.大规模数据如何检索?
当数据不是很多时,关系型数据库比如mysql,sql server等能够应对查询,写入数据,可是当数据达到10亿、100亿条的时候该如何做呢?
(1)传统数据库的应对解决方案
对于关系型数据,我们通常采用以下或类似架构去解决查询瓶颈和写入瓶颈:
解决要点:
1)通过主从备份解决数据安全性问题;
2)通过数据库代理中间件心跳监测,解决单点故障问题;
3)通过代理中间件将查询语句分发到各个slave节点进行查询,并汇总结果

(2)非关系型数据库的解决方案
对于Nosql数据库,以mongodb为例,其它原理类似:
解决要点:
1)通过副本备份保证数据安全性;
2)通过节点竞选机制解决单点问题;
3)先从配置库检索分片信息,然后将请求分发到各个节点,最后由路由节点合并汇总结果

二.Elasticsearch介绍
1.ES定义
ES=elaticsearch简写, Elasticsearch是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别的数据。
Elasticsearch也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
2. ES特点和优势
1)分布式实时文件存储,可将每一个字段存入索引,使其可以被检索到。
2)实时分析的分布式搜索引擎。
分布式:索引分拆成多个分片,每个分片可有零个或多个副本。集群中的每个数据节点都可承载一个或多个分片,并且协调和处理各种操作;
负载再平衡和路由在大多数情况下自动完成。
3)可以扩展到上百台服务器,处理PB级别的结构化或非结构化数据。也可以运行在单台PC上(已测试)
4)支持插件机制,分词插件、同步插件、Hadoop插件、可视化插件等。
3. ES国内外使用优秀案例
1) 2013年初,GitHub抛弃了Solr,采取ElasticSearch 来做PB级的搜索。 “GitHub使用ElasticSearch搜索20TB的数据,包括13亿文件和1300亿行代码”。
2)维基百科:启动以elasticsearch为基础的核心搜索架构。
3)SoundCloud:“SoundCloud使用ElasticSearch为1.8亿用户提供即时而精准的音乐搜索服务”。
4)百度:百度目前广泛使用ElasticSearch作为文本数据分析,采集百度所有服务器上的各类指标数据及用户自定义数据,通过对各种数据进行多维分析展示,辅助定位分析实例异常或业务层面异常。目前覆盖百度内部20多个业务线(包括casio、云分析、网盟、预测、文库、直达号、钱包、风控等),单集群最大100台机器,200个ES节点,每天导入30TB+数据。
4.Lucene与ES关系?
1)Lucene只是一个库。想要使用它,你必须使用Java来作为开发语言并将其直接集成到你的应用中,更糟糕的是,Lucene非常复杂,你需要深入了解检索的相关知识来理解它是如何工作的。
2)Elasticsearch也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
5. ES主要解决问题:
1)检索相关数据;
2)返回统计结果;
3)速度要快。
6. ES核心概念
1)Cluster:集群。
ES可以作为一个独立的单个搜索服务器。不过,为了处理大型数据集,实现容错和高可用性,ES可以运行在许多互相合作的服务器上。这些服务器的集合称为集群。
2)Node:节点。
形成集群的每个服务器称为节点。
3)Shard:分片。
当有大量的文档时,由于内存的限制、磁盘处理能力不足、无法足够快的响应客户端的请求等,一个节点可能不够。这种情况下,数据可以分为较小的分片。每个分片放到不同的服务器上。
当你查询的索引分布在多个分片上时,ES会把查询发送给每个相关的分片,并将结果组合在一起,而应用程序并不知道分片的存在。即:这个过程对用户来说是透明的。
4)Replia:副本。
为提高查询吞吐量或实现高可用性,可以使用分片副本。
副本是一个分片的精确复制,每个分片可以有零个或多个副本。ES中可以有许多相同的分片,其中之一被选择更改索引操作,这种特殊的分片称为主分片。
当主分片丢失时,如:该分片所在的数据不可用时,集群将副本提升为新的主分片。
5)全文检索。
全文检索就是对一篇文章进行索引,可以根据关键字搜索,类似于mysql里的like语句。
全文索引就是把内容根据词的意义进行分词,然后分别创建索引,例如”你们的激情是因为什么事情来的” 可能会被分词成:“你们“,”激情“,“什么事情“,”来“ 等token,这样当你搜索“你们” 或者 “激情” 都会把这句搜出来。
7. ES数据架构的主要概念(与关系数据库Mysql对比)
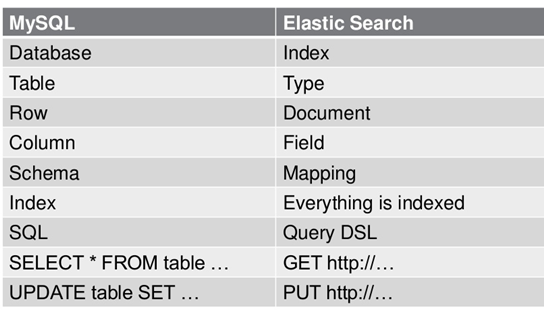
(1)关系型数据库中的数据库(DataBase),等价于ES中的索引(Index)
(2)一个数据库下面有N张表(Table),等价于1个索引Index下面有N多类型(Type),
(3)一个数据库表(Table)下的数据由多行(ROW)多列(column,属性)组成,等价于1个Type由多个文档(Document)和多Field组成。
(4)在一个关系型数据库里面,schema定义了表、每个表的字段,还有表和字段之间的关系。 与之对应的,在ES中:Mapping定义索引下的Type的字段处理规则,即索引如何建立、索引类型、是否保存原始索引JSON文档、是否压缩原始JSON文档、是否需要分词处理、如何进行分词处理等。
(5)在数据库中的增insert、删delete、改update、查search操作等价于ES中的增PUT/POST、删Delete、改_update、查GET.
8. 我们也需要
实际项目开发实战中,几乎每个系统都会有一个搜索的功能,当搜索做到一定程度时,维护和扩展起来难度就会慢慢变大,所以很多公司都会把搜索单独独立出一个模块,用ElasticSearch等来实现。
近年ElasticSearch发展迅猛,已经超越了其最初的纯搜索引擎的角色,现在已经增加了数据聚合分析(aggregation)和可视化的特性,如果你有数百万的文档需要通过关键词进行定位时,ElasticSearch肯定是最佳选择。当然,如果你的文档是JSON的,你也可以把ElasticSearch当作一种“NoSQL数据库”, 应用ElasticSearch数据聚合分析(aggregation)的特性,针对数据进行多维度的分析。
三.Elasticsearch的使用场景深入详解
1.使用Elasticsearch作为唯一的数据存储,以帮助保持你的设计尽可能简单。
此种场景不支持包含频繁更新、事务(transaction)的操作。
2.在现有系统中增加elasticsearch
由于ES不能提供存储的所有功能,一些场景下需要在现有系统数据存储的基础上新增ES支持。

举例1:ES不支持事务、复杂的关系(至少1.X版本不支持,2.X有改善,但支持的仍然不好),如果你的系统中需要上述特征的支持,需要考虑在原有架构、原有存储的基础上的新增ES的支持。
举例2:如果你已经有一个在运行的复杂的系统,你的需求之一是在现有系统中添加检索服务。一种非常冒险的方式是重构系统以支持ES。而相对安全的方式是:将ES作为新的组件添加到现有系统中。
如果你使用了如下图所示的SQL数据库和ES存储,你需要找到一种方式使得两存储之间实时同步。需要根据数据的组成、数据库选择对应的同步插件。可供选择的插件包括:
1)mysql、oracle选择 logstash-input-jdbc 插件。
2)mongo选择 mongo-connector工具。
假设你的在线零售商店的产品信息存储在SQL数据库中。 为了快速且相关的搜索,你安装Elasticsearch。
为了索引数据,您需要部署一个同步机制,该同步机制可以是Elasticsearch插件或你建立一个自定义的服务。此同步机制可以将对应于每个产品的所有数据和索引都存储在Elasticsearch,每个产品作为一个document存储(这里的document相当于关系型数据库中的一行/row数据)。
当在该网页上的搜索条件中输入“用户的类型”,店面网络应用程序通过Elasticsearch查询该信息。 Elasticsearch返回符合标准的产品documents,并根据你喜欢的方式来分类文档。 排序可以根据每个产品的被搜索次数所得到的相关分数,或任何存储在产品document信息,例如:最新最近加入的产品、平均得分,或者是那些插入或更新信息。 所以你可以只使用Elasticsearch处理搜索。这取决于同步机制来保持Elasticsearch获取最新变化。
ps:
使用 logstash-input-jdbc 同步数据带来的问题:
1.elasticsearch数据重复以及增量同步
2.数据同步频繁,影响mysql数据库性能
3.elasticsearch存储容量不断上升
4.增量同步和mysql范围查询导致mysql数据库有修改时无法同步到以前的数据
四:相关组件说明
1.elk:日志分析系统
ELK=elasticsearch+Logstash+kibana
elasticsearch:后台分布式存储以及全文检索
logstash: 日志加工、“搬运工”
kibana:数据可视化展示。
ELK架构为数据分布式存储、可视化查询和日志解析创建了一个功能强大的管理链。 三者相互配合,取长补短,共同完成分布式大数据处理工作。
2.spring boot集成elasticsearch6.1.1
3.插件应用及说明:
elasticsearch-head:用于网页查询elasticsearch数据
logstash-input-jdbc,用于mysql和elasticsearch同步
分词器插件
五:正式搭建及应用
1.搭建elasticsearch6.1.1
tar -zxvf elasticsearch6.1.1.tar.gz
mv elasticsearch /usr/local/elasticsearch
./bin/elasticsearch
此处一般会报错,因为不建议或者不允许以root用户启动elasticsearch
建立子用户
groupadd esgroup
useradd esuser -g esgroup -p 123456
更改elasticsearch文件夹及内部文件的所属用户及组:
cd /usr/local/elasticsearch chown -R esuser:esgroup elasticsearch-6.1.1
切换用户并运行:
su esuser ./bin/elasticsearch
后台运行:
./bin/elasticsearch -d
外网访问:
vim config/elasticsearch.yml
network.host: 0.0.0.0
可能汇报java内存不够用的错
vim conf/jvm.options

增大2倍即可,一直到可用
elasticsearch6.0版本安装head插件
- 下载到/shenfeng/elastcisearch
- unzip xxx.zip
- 安装nodejs
yum install nodejs
- 安装grunt
npm install -g grunt -cli
cd /shenfeng/elastcisearch/head
- npm install
 出现一下字样则成功
出现一下字样则成功
- grunt server运行
可能报错,报错则添加
vim elasticsearch安装目录/config/elasticsearch.yml
http.cors.enabled: true
http.cors.allow-origin: "*"
- 重新启动

2.搭建logstash6.1.1
tar -zxvf logstash6.1.1.tar.gz
mv logstash6.1.1 /usr/local/logstash
1.一般会./bin/logstash -f xxx.conf启动
其中xxx.conf是连接到elasticsearch的一些配置,自行上网搜
2.显示已安装的插件
./bin/logstash-plugin list 显示所有已安装好的plugin
3.安装plugin
./bin/logstash-plugin install logstash-input-log4j
如果安装较慢或者无反应
按照如下更改国内镜像库:
-------更改方法---------
如果没有gem命令的话,需要先安装一下子(root用户才可以)
yum install gem- 1
替换ruby镜像库为国内的库,因为国外的库,国内是访问不到的,然后国内有两个库,两个库都是可以用的:
1、替换成ruby-china的库
gem sources --add https://gems.ruby-china.org/ --remove https://rubygems.org/- 1
查看是否成功
gem sources -l- 1

2、国内还有一个库,是淘宝的:
gem sources --add https://ruby.taobao.org/ --remove https://rubygems.org/- 1
可以同样用gem sources -l查看是否替换成功。
替换完之后,进入logstash-5.5.0,修改Gemfile文件里面的数据源:
vi Gemfile- 1
修改成这个样子:
source "https://gems.ruby-china.org"- 1
如果用的用的是淘宝的库,就修改成这样
source "https://ruby.taobao.org"- 1
好了,这样ruby的安装环境就算是配好了。
进入到logstash的bin下
cd bin
./bin/logstash-plugin install logstash-input-log4j
---------完成-----------
logstash-input-log4j插件介绍:
通过配置可将mysql数据同步到elasticsearch,以下介绍如何进行同步
进入到logstash的bin目录下,
mkdir config-mysql
cd config-mysql
vim mysql2.conf
input {
stdin {
}
jdbc {
# 数据库
jdbc_connection_string =>
"jdbc:mysql://localhost:3306/elasticsearchSynchronize"
# 用户名密码
jdbc_user =>
"root"
jdbc_password =>
"123456"
# jar包的位置
jdbc_driver_library =>
"/usr/local/logstash/logstash-6.1.1/bin/config-mysql/mysql-connector-java-5.1.45-bin.jar"
# mysql的Driver
jdbc_driver_class =>
"com.mysql.jdbc.Driver"
jdbc_paging_enabled =>
"true"
jdbc_page_size =>
"50000"
#需要执行的脚本
statement_filepath =>
"config-mysql/jdbc.sql"
#statement =>
"select * from persion"
schedule =>
"* * * * *"
#索引的类型
type =>
"jdbc"
# 是否记录上次执行结果, 如果为真,将会把上次执行到的 tracking_column 字段的值记录下来,保存到 last_run_metadata_path 指定的文件中
record_last_run =>
"true"
# 是否需要记录某个column 的值,如果record_last_run为真,可以自定义我们需要 track 的 column 名称,此时该参数就要为
true
. 否则默认 track 的是 timestamp 的值.
use_column_value =>
"true"
# 如果 use_column_value 为真,需配置此参数. track 的数据库 column 名,该 column 必须是递增的. 一般是mysql主键
tracking_column =>
"id"
last_run_metadata_path =>
"/usr/local/logstash/logstash-6.1.1/bin/config-mysql/last_id"
# 是否清除 last_run_metadata_path 的记录,如果为真那么每次都相当于从头开始查询所有的数据库记录
clean_run =>
"false"
#是否将 字段(column) 名称转小写
lowercase_column_names =>
"false"
}
}
filter {
json {
source =>
"message"
remove_field => [
"message"
]
}
}
output {
elasticsearch {
hosts =>
"127.0.0.1:9200"
# index名
index =>
"sychronize_mysql"
# 需要关联的数据库中有有一个id字段,对应索引的id号
document_id =>
"%{id}"
}
stdout {
codec => json_lines
}
}
|
此处需要mysql-connector-java-5.1.45-bin.jar包,自行下载
jdbc.sql说明
SELECT
*
FROM
persion
WHERE
id > :sql_last_value
|
./bin/logstash -f config-mysql/mysql2.conf
如未报错,则去localhost:9100去查看数据是否已经同步.
六,可能遇到的问题
1.elasticsearch数据重复以及增量同步
在默认配置下,tracking_column这个值是@timestamp,存在elasticsearch就是_id值,是logstash存入elasticsearch的时间,这个值的主要作用类似mysql的主键,是唯一的,但是我们的时间戳其实是一直在变的,所以我们每次使用select语句查询的数据都会存入elasticsearch中,导致数据重复。
解决方法:在要查询的表中,找主键或者自增值的字段,将它设置为_id的值,因为_id值是唯一的,所以,当有重复的_id的时候,数据就不会重复
// 是否记录上次执行结果, 如果为真,将会把上次执行到的 tracking_column 字段的值记录下来,保存到 last_run_metadata_path 指定的文件中
record_last_run => "true"
// 是否需要记录某个column 的值,如果record_last_run为真,可以自定义我们需要 track 的 column 名称,此时该参数就要为 true. 否则默认 track 的是 timestamp 的值.
use_column_value => "true"
// 如果 use_column_value 为真,需配置此参数. track 的数据库 column 名,该 column 必须是递增的. 一般是mysql主键
tracking_column => "autoid"
2.数据同步频繁,影响mysql数据库性能
我们写入jdbc.sql文件的mysql语句是写死的,所以每次查询的数据库有很多是已经不需要去查询的,尤其是每次select * from table;的时候,对mysql数据库造成了非常大的压力
解决:(1)根据业务需求,可以适当修改定时同步时间,我这里对实时性相对要求较高,因此设置了10分钟
// 这里类似crontab,可以定制定时操作,比如每10分钟执行一次同步(分 时 天 月 年)
schedule => "*/10 * * * *"(2)设置mysql查询范围,防止大量的查询拖死数据库
// 如果 use_column_value 为真,需配置此参数. track 的数据库 column 名,该 column 必须是递增的. 一般是mysql主键
tracking_column => "autoid"
// 上次执行数据库的值,该值是上次查询时tracking_column设置的字段最大值
last_run_metadata_path => "/opt/logstash/conf/last_id"
// 是否清除 last_run_metadata_path 的记录,如果为真那么每次都相当于从头开始查询所有的数据库记录
clean_run => "false"在sql语句这里设置select * from WHERE autoid > :sql_last_value;
注意:如果你的语句比较复杂,autoid > :sql_last_value一定要写在WHERE后面,然后接AND即可
3.elasticsearch存储容量不断上升
稍微观察下就会发现,即使没有新的数据写入到elasticsearch里面,但只要logstash定时每次运行,elasticsearch容量就不断上升

过一段时间看,占用空间增大,其实elasticsearch数据是一样的
![]()
原因:在elasticsearch/nodes/0/indices/jdbc/{0,1,2,3,4}/下有个translog,这个是elasticsearch的事务日志,类似mysql的binlog。elasticsearch为了数据安全,接收到数据后,先将数据写入内存和translog,然后再建立索引写入到磁盘,这样即使突然断电,重启后,还可以通过translog恢复,不过这里由于我们每次查询都有很多重复的数据,而这些重复的数据又没有写入到elasticsearch的索引中,所以就囤积了下来

解决:查询官网说会定期refresh,会自动清理掉老的日志,因此可不做处理
4.增量同步和mysql范围查询导致mysql数据库有修改时无法同步到以前的数据
增量同步解决了,mysql每次都小范围查询,解决了数据库压力的问题,不过却导致无法同步老数据的修改问题
解决:可根据业务状态来做,如果你数据库是修改频繁类型,那只能做全量更新了,但是高频率大范围扫描数据库来做的索引还不如不做索引了(因为建立索引也是有成本的),我们做索引主要是针对一些数据量大,不常修改,很消耗数据库性能的情况。我这里是数据修改较少,而且修改也一般是近期数据,因为同步时,我在mysql范围上面稍微调整一下
如:autoid > (:sql_last_value-100000),每次扫描上次扫描范围往之前再多10W行,这样扫描的数据量相对较小,也照顾到了可能会修改的数据类型
但是范围扫描还存在一个问题,就是过往的数据写入了elasticsearch之后,如果有修改,而又不在范围扫描以内,那么elasticsearch就不会同步到。因此,我们还可以定期做一次全量或者更大范围的同步,只需要修改范围值即可。具体的值当然可以根据业务来定
未完待续......















 1293
1293

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









