










MirrorMaker原理架构

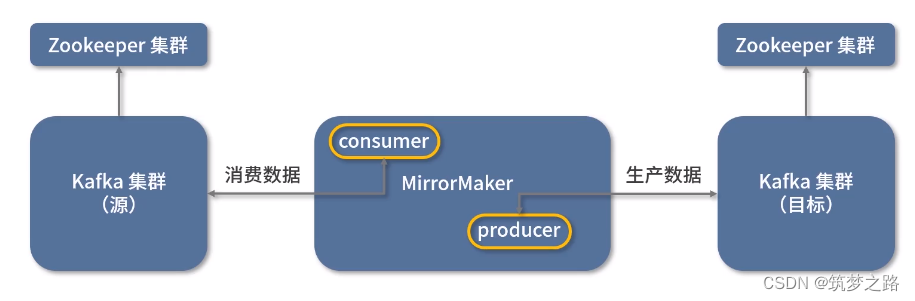
数据流向

上图也是一种比较常见的用法,这里作为记录。下面介绍一则实战案例。
网络架构

配置日志采集器filebeat
配置从哪里采集日志
 输出到kafka集群
输出到kafka集群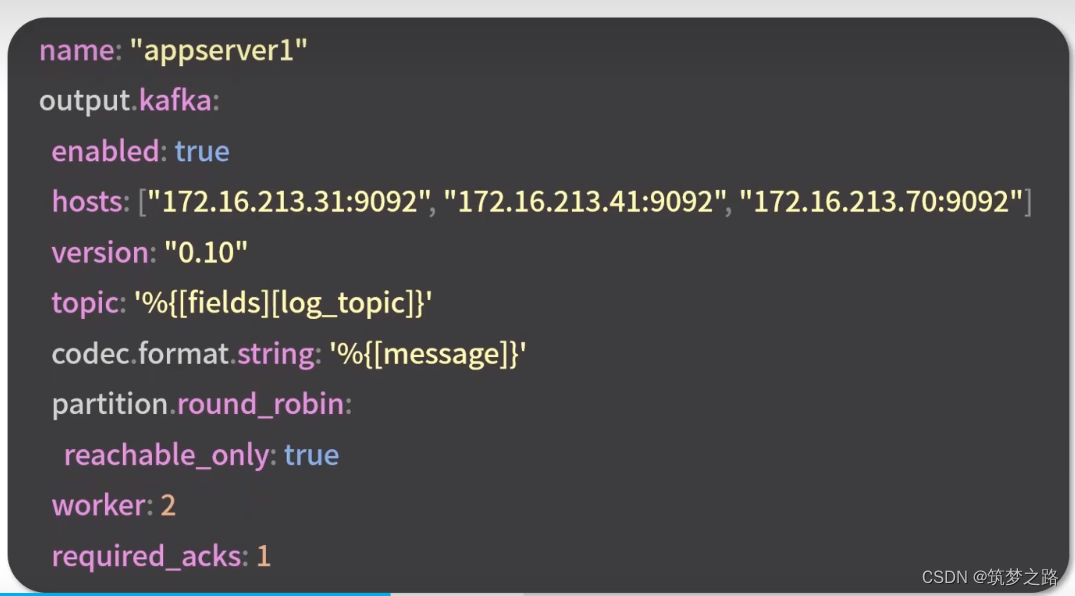

配置MirrorMaker消费者 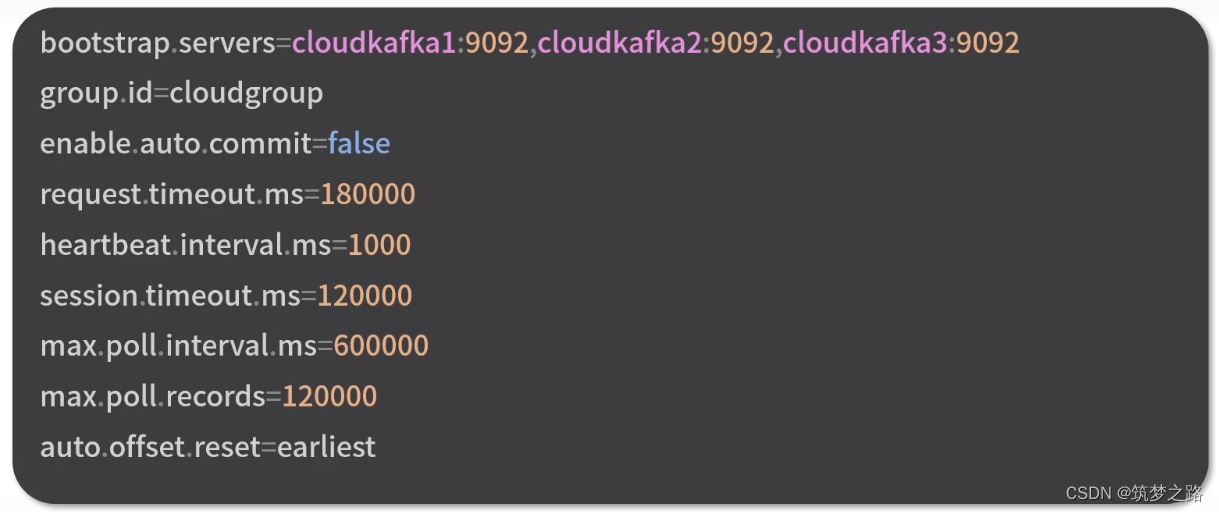
参数说明:
bootstrap.servers 指定消费哪个kafka的数据
group.id 指定消费者加入哪个消费组,一条消息可以被多个消费组消费,在一个消费组内只能被一个消费者消费
enable.auto.commit 默认true, 指定false表示不允许自动提交消费偏移量,避免重复消费、数据丢失
request.timeout.ms 设置请求的超时时间,发起请求不一定能很快收到响应
heartbeat.interval.ms 心跳间隔,确定消费者存活和退出检测机制
session.timeout.ms 消费者会话过期时间 必须大于心跳间隔 小于请求超时
max.poll.interval.ms 消费者处理逻辑的最大时间
max.poll.records 消费者每次取到的消息最大数量,过大会影响在指定时间内无法完成
auto.offset.reset 消费者在无效偏移量、没有偏移量的情况下如何处理,默认是latest,从最新记录读取,容易丢失数据,这里设置为从头开始,避免丢失数据。
配置MirrorMaker生产者
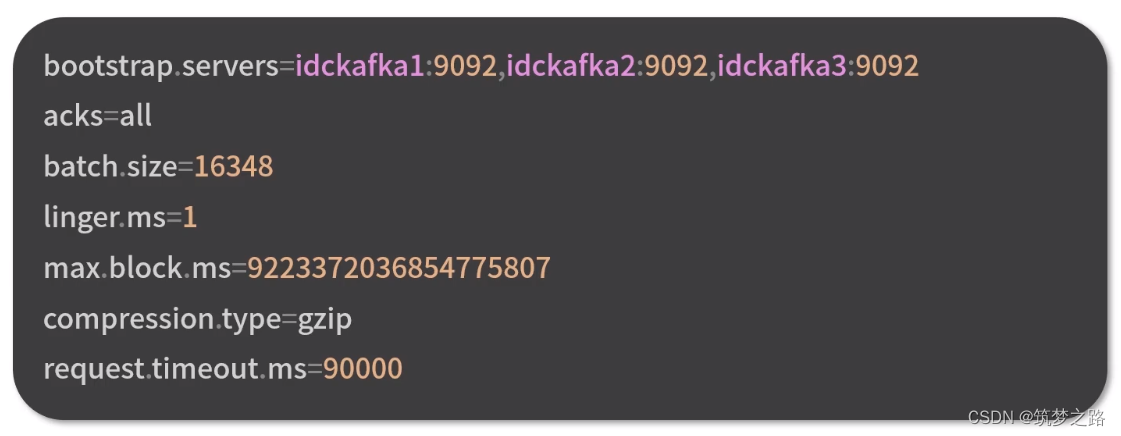
参数说明:
bootstrap.servers 生产者的地址
acks 指定在集群中有多少个分区副本收到消息,生产者才会认为消息写入成功,对于消息是否丢失有比较大的影响,有3个值可选,0 1 all , 其中0 、1都可能会丢失数据,all安全性最高,效率最低,2个以上分区副本时不丢失任何数据
batch.size 生产者批量发送的基本单位
linger.ms 限制batch无论是否写满在指定时间内必须发送,避免消息长期驻留在内存中一直不发送的情况
max.block.ms 获取kafka集群元数据时生产者阻塞时间,超出后生产者会抛超时异常
compression.type 指定消息发送到kafka broker前使用哪种压缩算法,gzip可降低网络传输、磁盘存储开销
request.timeout.ms 生产者发送数据等待kafka集群响应的超时时间
启动MirrorMaker
 启动先后顺序说明
启动先后顺序说明
查询消费情况

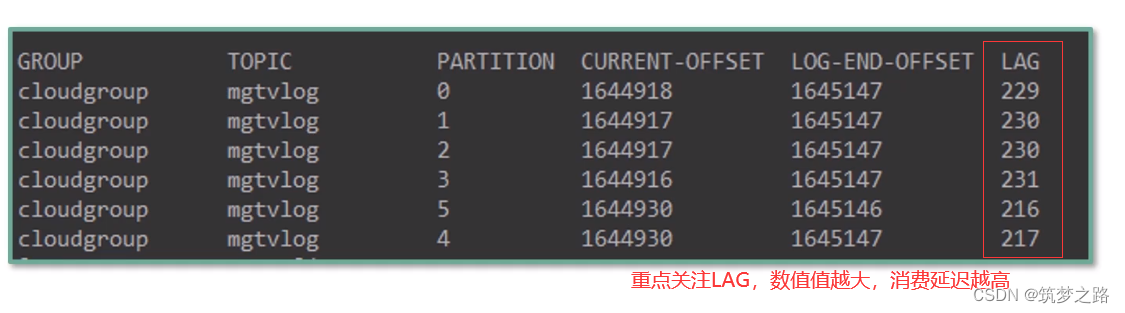
注意事项



这里采用的MirrorMaker1的方式来实现,kafka 2.4以后已经支持MirrorMaker2的方式。
MM1不足之处
- 目标集群的Topic使用默认配置创建,但通常需要手动repartition。
- acl和配置修改的时候不会自动同步,给多集群管理带来一些困难
- 消息会被
DefaultPartitioner打散到不同分区,即对一个topic ,目标集群的partition与源集群的partition不一致。- 任何配置修改,都会使得集群变得不稳定。比如比较常见的增加topic到whitelist。
- 无法让源集群的producer或consumer直接使用目标集群的topic。
- 不保证exactly-once,可能出现重复数据到情况
- mm1支持的数据备份模式较简单,比如无法支持active <-> active互备
- rebalance会导致延迟
















 2895
2895











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









