







目录
一、技术背景
如果要彻底明白select机制,还是要首先去了解IO,网络编程、Blocking IO、No Blocking IO的相关概念及底层实现。下面只是作为技术背景去介绍这几个概念。
1、理解IO本质
IO从英文本身去解释就是输入输出(Input/Output),这里不去过分深究计算机IO的这个概念,从通俗的来讲,可以理解为将数据(二进制)输入到计算机中,或者将数据从计算机输入到其他的硬件设备,如磁盘,网卡、其他外设之类的。
2、网络编程
所谓的网络编程,这里我也不细扣网上的概念,因为概念比较抽象,按照我的理解实际上就是把数据由内存写到网卡,或者网卡读取到远端传过来的数据,写入到内存,然后再由计算机程序去处理的一个交互的过程。对比磁盘IO,就是磁盘变成了所谓的网卡。
备注:下面讲的阻塞IO还是非阻塞IO均是针对网络编程这块。
3、阻塞IO
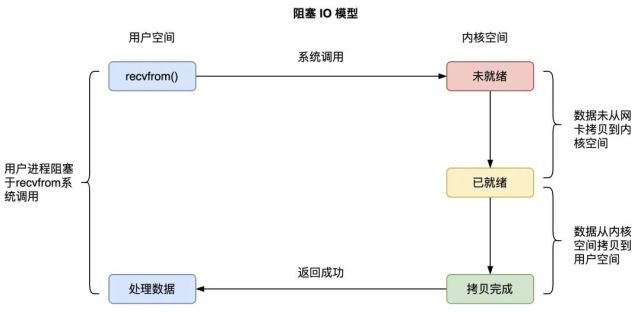
阻塞IO的全称即是BIO(Blocking IO),从它的英文来说都知道是阻塞IO,但是我们要弄懂阻塞IO阻塞的是哪部分。
从linux的库函数去理解,即就是recvfrom方法的系统调用,就会把当前进程(或线程)阻塞,等到操作系统数据将数据由内核态拷贝到用户态才会进行返回。如下图所示:
4、非阻塞IO
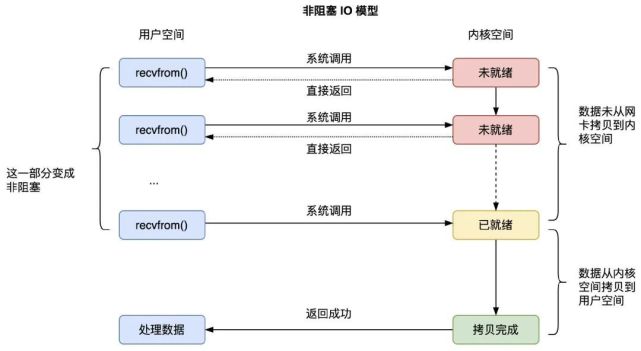
非阻塞IO的全称即是 No Blocking IO,也称为我们常说的NIO,它其实与BIO的本质区别就是数据未就绪的情况调用的时候立即返回,但是如果有数据已就绪的情况下。还是会阻塞等到数据拷贝完成,才进行返回。
至于什么是数据就绪,我个人理解分为两种情况:
(1)数据没有就绪
- 即要么网卡没有收到远程客户端的数据。
- 网卡收到了远程客户端的数据,但还没有拷贝到内核态。
(2)数据就绪
- 网卡收到了远程客户端的数据,拷贝数据到内核态完成。
5、整体理解
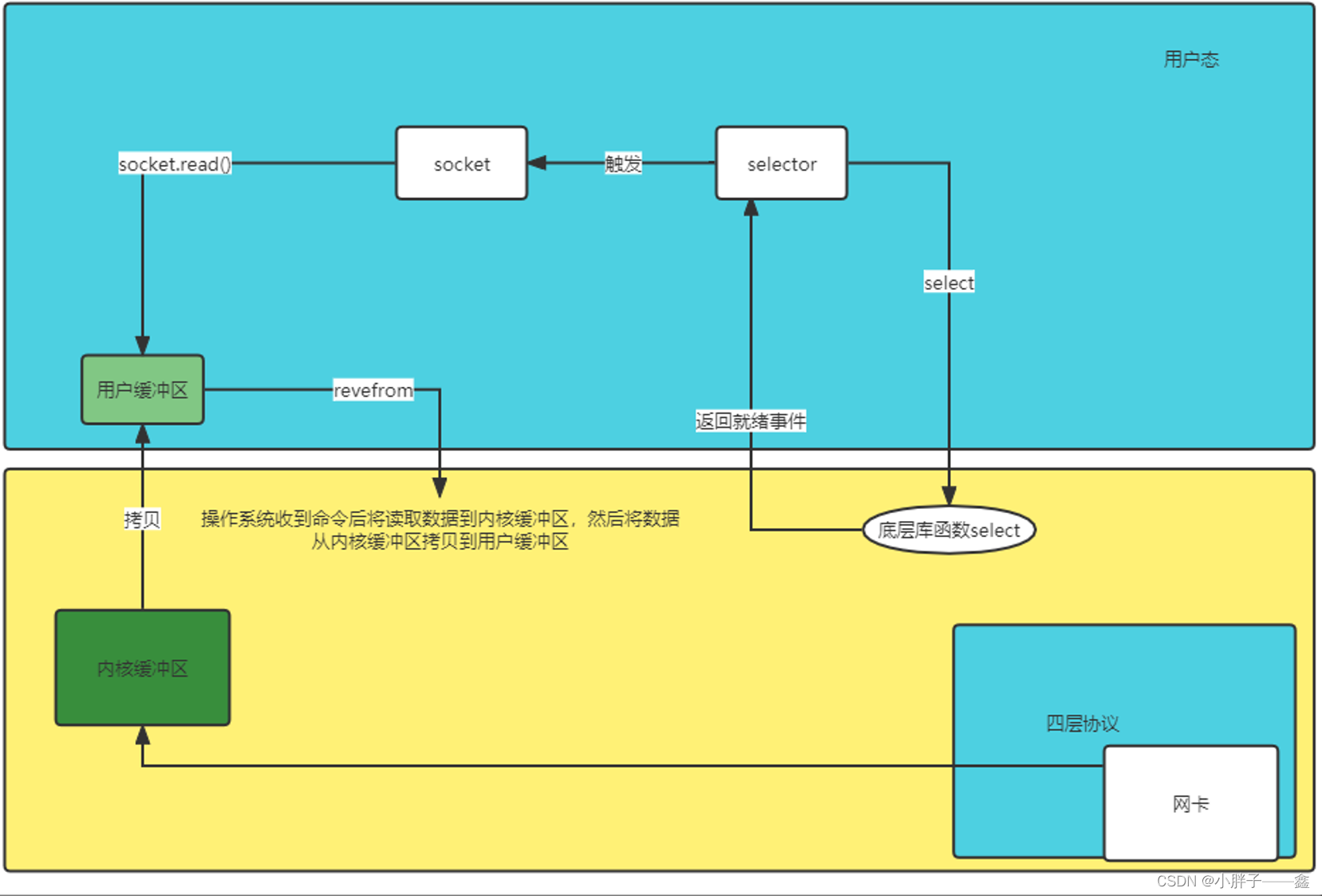
下面是个人结合客户端服务端、七层网络协议、用户态内核态、socket编程后。对整个计算机的网络读取响应的理解所画的图。
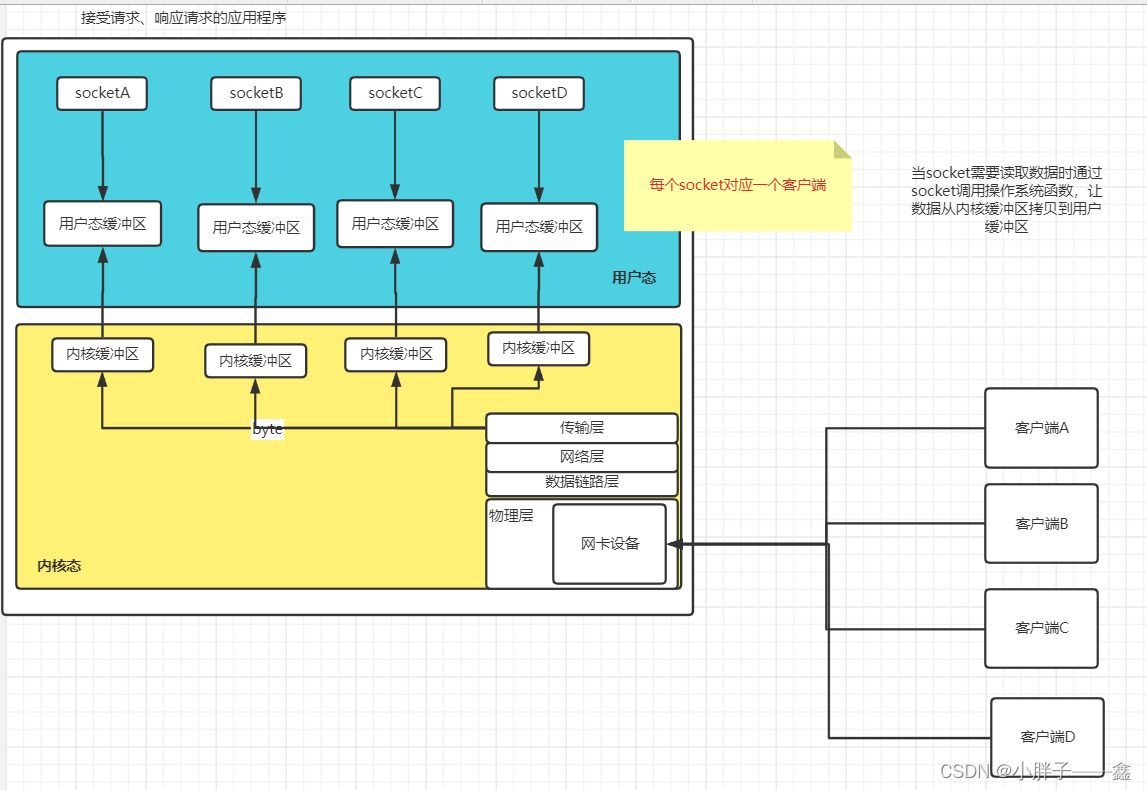
可以看出可以把socket理解为对底层操作系统的逻辑的屏蔽所封装出来,提供给我们进行网络IO交互的对象,通过对象我们可以读数据以及写数据。
二、select机制与在整个读取数据过程中的关系。
通过技术背景下的整个交互图来看。设想假如没有select(IO多路复用)机制,如果让我们想想现有的流程,我们怎么实现网络数据的读取。
1、BIO机制的引入
这里是不是可以用到我们上面说的BIO机制,通过recvform函数的调用,对当前进程(线程)进行阻塞,当远程客户端有数据发送到服务器这边,再进行返回。如下图所示。
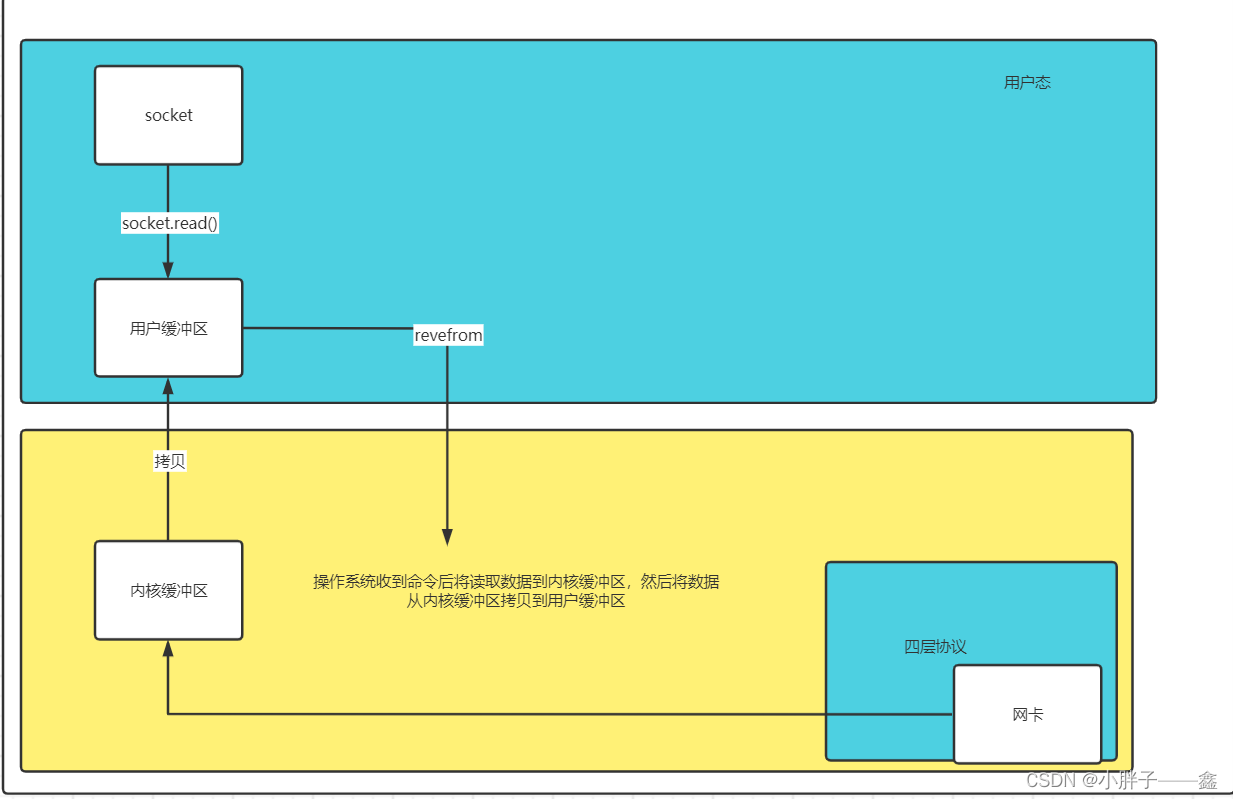
通过上面流程我们是可以也可以实现远程网络数据的读取。但是你使用BIO会导致一个什么问题?答案就是阻塞进程(阻塞线程),想想如果我们以进程(线程)级别去调用,拿线程来说,我们的线程就会被挂起,这时候就有以前BIO的解决方案,那就是多线程+线程池的模式。如下图所示

这个时候确实能支撑多个连接请求的问题,但是这个时候就会有个致命的问题。那就是线程池的数量有限,同时开启了多个线程对CPU负载很高,所以这个模型的缺陷导致无法支持更多的客户端请求。
2、NIO机制的引入
于是乎想到不是有NIO吗?如果使用NIO是不是就不用阻塞,用一个特有的线程去处理接受请求以及返回数据。没错,使用NIO确实解决了多线程的问题。但是NIO也会有一个问题,就是处理请求的线程会一直空转,因为要时刻监听发生了什么事件。如下图NIO代码所示。
public class NioServer {
// 保存客户端连接
static List<SocketChannel> channelList = new ArrayList<>();
public static void main(String[] args) throws IOException {
// 创建NIO ServerSocketChannel,与BIO的serverSocket类似
ServerSocketChannel serverSocket = ServerSocketChannel.open();
// 绑定端口号 9000
serverSocket.socket().bind(new InetSocketAddress(9000));
// 设置ServerSocketChannel为非阻塞
serverSocket.configureBlocking(false);
System.out.println("服务启动成功");
while (true) {
// 这个 while 循环就一直在跑
// 非阻塞模式 accept 方法不会阻塞,否则会阻塞
// NIO的非阻塞是由操作系统内部实现的,底层调用了linux内核的accept函数
SocketChannel socketChannel = serverSocket.accept();
// 如果有客户端进行连接
if (socketChannel != null) {
System.out.println("连接成功");
// 设置SocketChannel为非阻塞,读取数据前不阻塞
socketChannel.configureBlocking(false);
// 保存客户端连接在List中,将刚刚客户端与服务器建立的通道放到这个list中
channelList.add(socketChannel);
}
// 遍历连接进行数据读取,不管这个通道有木有数据都会遍历
Iterator<SocketChannel> iterator = channelList.iterator();
while (iterator.hasNext()) {
SocketChannel sc = iterator.next();
ByteBuffer byteBuffer = ByteBuffer.allocate(128);
// 非阻塞模式read方法不会阻塞,否则会阻塞
int len = sc.read(byteBuffer);
// 如果有数据,把数据打印出来
if (len > 0) {
System.out.println("接收到消息:" + new String(byteBuffer.array()));
// 如果客户端断开,把socket从集合中去掉
} else if (len == -1) {
iterator.remove();
System.out.println("客户端断开连接");
}
}
}
}
}可以看到如上面NIO代码所示,需要不停的while循环进行空转来获取感兴趣的监听事件。非常消耗CPU的资源。到这里我们是不是应该思考,还有什么方式既能够实现NIO的方式,又能不空转,不浪费CPU资源呢?
3、select机制的引入
没错,其实你想实现的,linux的设计者也想到了,所以在linux早期就提供了select机制加上NIO的模式去实现处理客户端的请求的模式。select是linux最早期IO多路复用机制。其实本质上NIO的过程是不变的,变的是由操作系统告知我们有事件变更了,我们才去读取事件,而不是不断轮询去读取事件。如下图所示(以一个客户端为例)
这个时候借助了IO多路复用机制,监听我们的感兴趣的事件发生后再进行数据的读取,就可以避免多余的CPU空转导致的CPU浪费的问题。变成了比较完善的一套机制。此时在这里可以下结论IO多路复用机制其实就是帮助我们高效的处理客户的请求。
三、Select机制的原理
上面说到既然select机制能够这样帮我们去处理程序,那么它本身的实现原理是什么呢?同时它本身又有什么局限性呢?带着这个疑问我们继续挖掘这个select技术的本质。
1、底层库函数
我们做技术人讲究的是源代码,那好我们就来深入select的源码看看,其实select机制如果深挖到代码级别对应的就是linux系统下的一个底层库函数,我们来看看select函数
int select (int __nfds, fd_set *__restrict __readfds,
fd_set *__restrict __writefds,
fd_set *__restrict __exceptfds,
struct timeval *__restrict __timeout);既然看到这个函数,那我们来看看函数的参数到底代表什么?
参数说明:
__nfds:集合中所有文件描述符的范围,需设置为所有文件描述符中的最大值加1。
readfds:要进行监听的是否可以读文件的文件描述符集合。
writefds:要进行监听的是否可以写文件的文件描述符集合。
errorfds:要进行监听的是否发生异常的文件描述符集合。
timeval:select的超时时间,它可以使select处于三种状态:
1、若将NULL以形参传入,即不传入时间结构,就是将select至于阻塞状态,一定要等到监视的文件描述符集合中某个文件描述符发生变化为止。
2、若将时间值设为0秒0毫秒,就变成一个纯粹的非阻塞函数,不管文件描述符是否发生变化,都立刻返回继续执行,文件无变化返回0,有变化返回一个正值。
3、timeout的值大于0,这就是等待的超时时间,即select在timeout时间内阻塞,超时时间之内有事件到来就返回,否则在超时后不管怎样一定返回。
4、函数的返回值:
返回值 > 0:表示被监视的文件描述符有变化。数值表示变化的个数
返回值 = -1:表示select出错。
返回值 = 0:表示超时。
其实参数本身也是很好理解,linux一切皆文件的前提下,linux操作系统会为每一个Socke分配一个文件文件描述符去标识一个socket,通过文件描述符能对socket进行读写操作。所以fd_set就是文件描述符的集合。
那么fd_set又是怎样的一个结构呢?我们看看linux源码是怎么写的
typedef __kernel_fd_set fd_set;
#undef __FD_SETSIZE
#define __FD_SETSIZE 1024
typedef struct {
unsigned long fds_bits[__FD_SETSIZE / (8 * sizeof(long))];
} __kernel_fd_set;可以看到,它本质上是一个结构体,这是C语言的语法。然后一个结构体里面会有一个long的数组。那么这个long型的数组是如何存储我们的文件描述符的呢?我们一步步来
(1)首先看这个数组的大小,__FD_SETSIZE / (8 * sizeof(long)) = 1024 / (8 * 8) = 16
我们来看看这个计算规则,sizeof(long) 如果是64位计算机系统,则占8个字节,所以这个数组就是16个元素。
那么它是如何做到用16个元素的long数组存储1024个文件描述符的呢?
这里能用位存储的思路去理解,想想一个16个元素的long数组,而long本身占8个字节,那么总共可以表示16 * 8 * 8(一个字节等于8位) = 1024位,没错就是__FD_SETSIZE的值。还记得我们文件描述符是整形吗,那么就可以这样进行表示出文件描述符与Socket的关系,如下图所示。
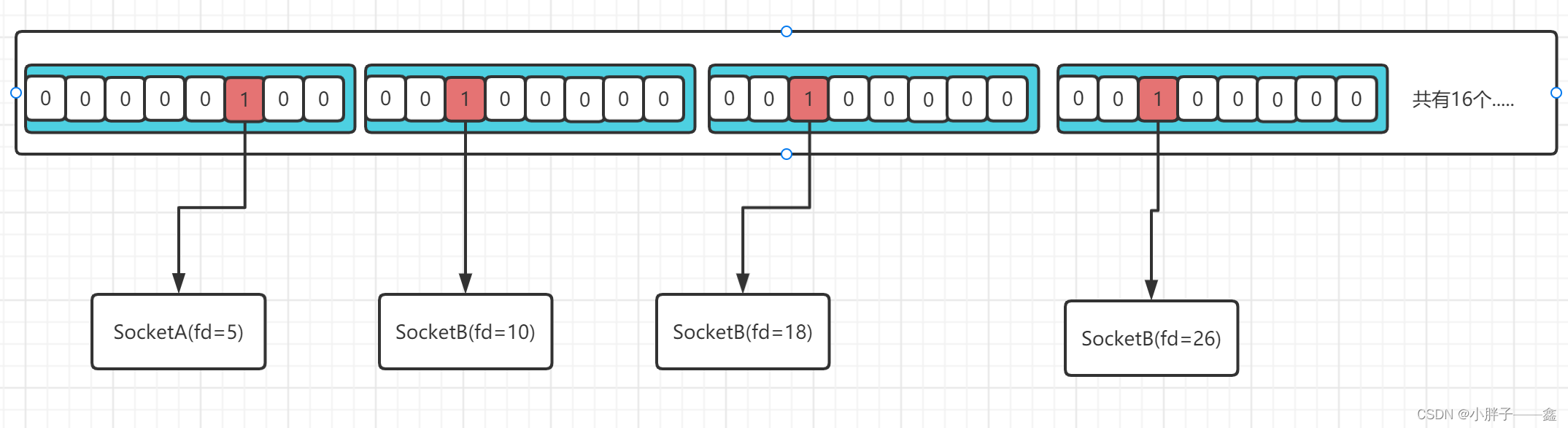
使用位存储的好处是什么?当然是节省空间,用更小的空间结构存储更多的映射关系。
所以在这里我们就可以知道为什么select是有上限的,最大只能监听1024个文件描述符,是因为linux代码写死了1024,如果想要监听更多的文件描述符,只有修改linux源码才可以实现。
2、Select机制是如何实现我们的事件监听的呢?
这里其实我本质上也是看网上的分析,推荐几篇文章
深入select多路复用内核源码加驱动实现 - 黑客画家的个人空间 - OSCHINA - 中文开源技术交流社区
讲的还是挺不错的,这里我就在这个基础上进行一些自己对select机制的理解与总结,如下图所示。
源码调用链:select ---> sys_select ----> core_sys_select ----> do_select
结合源码与网上的介绍文章,结合我自己的理解,我重新总结了一张图:
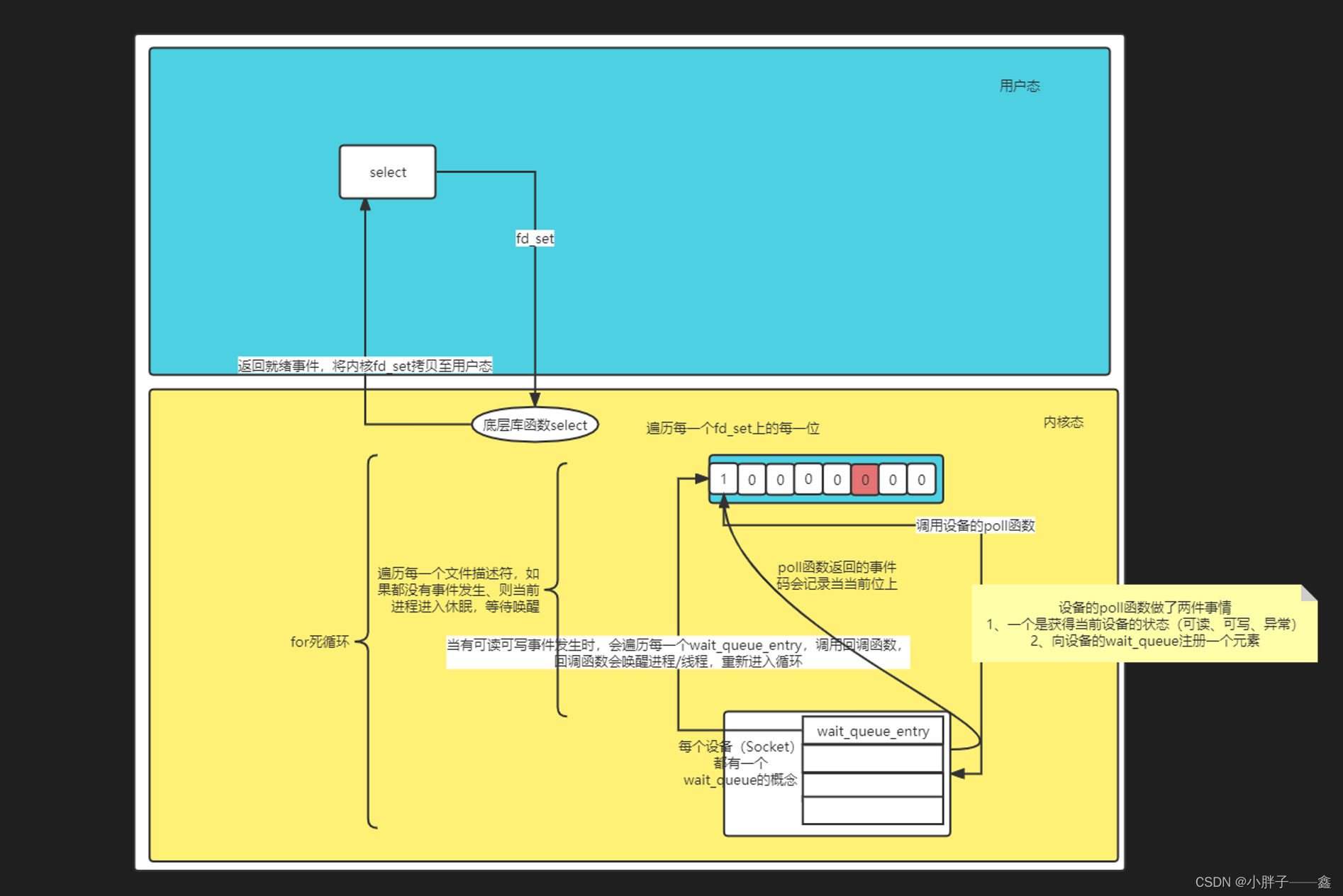
图中省略了复杂的数据结构,只留下整体的运转流程。
其实select机制说白了也是要借助底层驱动的支持,即当有事件发生时能够触发事件回调。由硬件层通知到我们的内核态,然后由内核态通知到我们的应用态的一个过程。
3、关于Select机制的总结
- 由于底层数据结构的写死,所以select最多支持1024个文件描述符,也就是1024个连接。
- 以fd_set为例,每次都要从用户态拷贝至内核态,同时还要在内核态进行循环遍历,然后把有事件的响应的文件描述符fd_set返回,又要从内核态拷贝至用户态。用户态拿到这个有事件的文件描述符返回,还要针对返回的描述符进行遍历,才能知道哪个文件描述符对应的Socket可写可读,总共经历了两次遍历,两次拷贝,所以说为什么Select在文件描述符比较多的情况,效率为什么是低下的原因。如下动图可看到。
fd_set拷贝
- 因为Select返回后会污染入参的fd_set,所以每次调用都要重设fd_set,也是一个比较麻烦的点。
四、总结
1、关于Select就写到这里了,个人认为理解了Select机制再去理解Poll、Epoll会更容易理解,因为这两个就是在Select的基础上进行优化后的机制。所以才会深入研究下。















 1172
1172











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









