







大端与小端字节数据详解
转自:https://blog.csdn.net/dosthing/article/details/80641173
前言
计算机的数据以01构成的字节存储,这就涉及数据大小端的问题。计算机是大端数据模式还是小端数据模式对于普通的应用程序没有什么影响,但是在诸如网络编程、芯片寄存器操作的时候就有必要区分一下了,要不然会遇到程序的逻辑设计完全没问题,但得到的数据总是错误的尴尬。这里详细介绍一下这两种数据模式的差异,以及结合实际应用例子来检验我们主机的字节顺序模式。
字节顺序模式
计算机的字节顺序模式分为大端数据模式和小端数据模式,它们是根据数据在内存中的存储方式来区分的。小端字节顺序的数据存储模式是按内存增大的方向存储的,即低位在前高位在后;大端字节顺序的数据存储方向恰恰是相反的,即高位在前,低位在后。纯文字描述有点抽象。
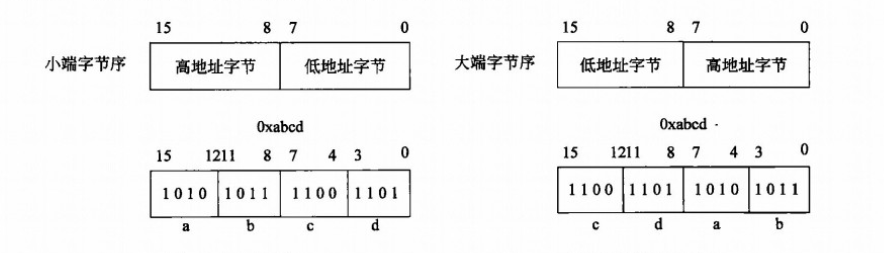
我们结合一个例子来说明,如图一个16位的数据0xabcd在不同字节顺序的计算机内存中的存储情况。小端字节顺序中的数据存储是按照内存增长的方向存储的。
0xabcd中的0xcd属于低位数据,故存在Bit[0,7],11001101;
0xab属于高位数据,故存储在Bit[8,15],10101011;
组合起来就是两个字节16bit——》1010 1011 1100 1101 == 0xabcd;
大端字节顺序中的数据存储就反过来,高位数据0xab存储在低位Bit[0,7],低位数据0xcd存储在高位Bit[8,15]。小结:计算机的字节顺序模式就是数据在内存中存储方式的不同,小端数据模式与内存增长方向一致,大端数据模式与内存增长方向相反。
字节顺序应用
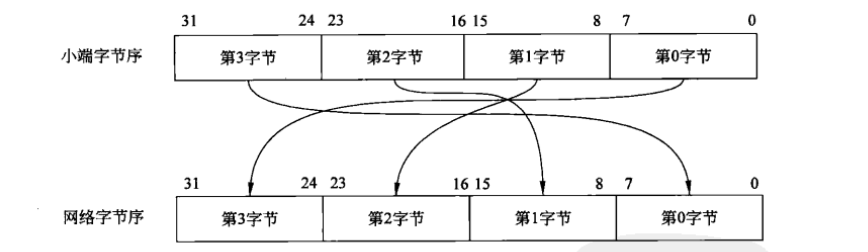
对字节顺序敏感的编程涉及的范围较多,这里以网络编程和芯片操作来说明大小端数据模式的转换问题。首先来说说网络编程,我们知道模式进网络上的数据都是以大端数据模式进行交互的,而我们的主机大多数是以小端数据行理,它们如果不处进行转换的话,势必会引起数据混乱。如图,我们主机的32位数据通过转换为网络字节序,转换的过程非常简单,将小端字节序的第3字节与网络字节序的第0字节对换、小端字节序的第2字节与网络字节序的第1字节对换、小端字节序的第1字节与网络字节序的第2字节对换、小端字节序的第0字节与网络字节序的第3字节对换。这个过程可以交由标准的POSIX库函数来完成,如htons()、htonl()分别将16位、32位主机数据转换为网络字节序;ntohs()、ntohl()则分别将16位、32位网络字节序转换为主机数据。
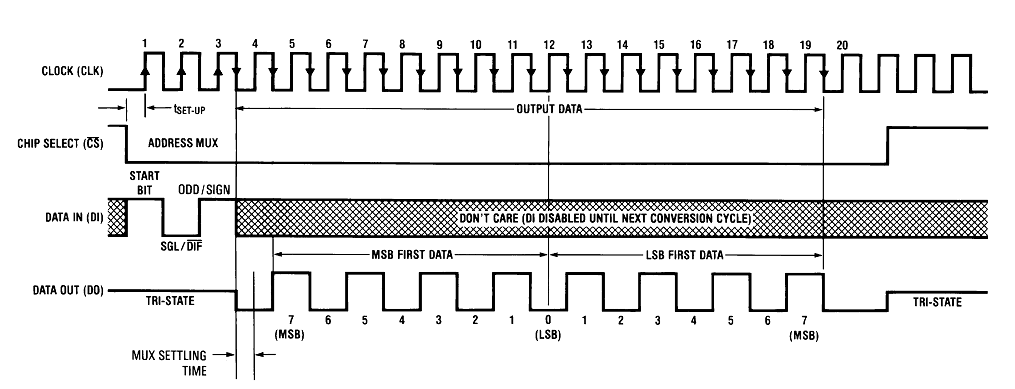
另一个应用是芯片操作,这一块在嵌入式系统中应用比较多,一般在芯片的说明手册中都会详细说明芯片通信时使用的数据格式,如果遇到与主机的字节顺序不一样的,我们必须进行转换。这里拿经典的AD转换芯片ADC0832来说明,ADC0832是一款将模拟信号转为数字信号的芯片,从它数据格式输出的时序图中也可以看出,它支持大端数据格式,也支持小端数据格式。假设ADC0832输出选用大端数据格式、主机是小端数据格式,当它们进行数据交互时,需要进行转换,比如主机想要发送一个16位的操作指令,我们可以通过移位、位与、位或等操作将数据进行字节顺序的转换。(下图截取之ADC0832芯片手册的ADC0832芯片数据操作时序图)
检测主机字节顺序样例
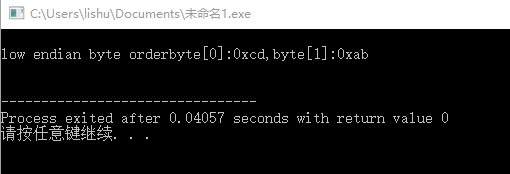
了解大小端字节顺序后,我们如何知道我们的主机是用什么字节顺序呢,这里提供一个样例,它兼容Window、linux等通用操作系统平台,编译运行即可。它的原理也很简单,利用共用体共用一段相同的内存,然后我们定义两个的变量(这里是short int与char),然后对长变量(short int 16位)进行初始化,接着按字节(char 8位)读取打印出来比较即可知道主机的字节顺序。
/*Describe: this program is used to check the host byteorder
**Author:shuang liang li
**Date:2018-06-10
*/
#include<stdio.h>
//共用体类型的变量类型,用于测试字节序
//成员value的高低字节可以由成员type按字节访问
typedef union{
unsigned short int value;//短整型变量
unsigned char byte[2]; //字符型
}to;
int main(int argc,char*argv)
{
to typeorder;
typeorder.value=0xabcd;
if(typeorder.byte[0]==0xcd&&typeorder.byte[1]==0xab)//小端字节顺序
{
printf("\nlow endian byte order""byte[0]:0x%x,byte[1]:0x%x\n\n",typeorder.byte[0],typeorder.byte[1]);
}
if(typeorder.byte[0]==0xab&&typeorder.byte[1]==0xab)//大端字节顺序
{
printf("\nhight endian byte order""byte[0]:0x%x,byte[1]:0x%x\n\n",typeorder.byte[0],typeorder.byte[1]);
}
return 0;
}
总结
计算机的字节顺序模式有两种,大端数据模式和小端数据模式,在网络编程和芯片操作编程中应注意这两者的区别,以保证数据处理的正确性。














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









