







先建立几个常识:
- 一般机器的字节序大小端和比特序大小端是一致的。
- 人类阅读时,从左向右进行阅读,所以先看到数字的高位,最后才能看到数字的低位。所以,人类的阅读顺序,天然是大端顺序。大端顺序是更方便人类阅读和表述的顺序。比如0xfedc,我们是认为f是最高位,c是最低位;比如0b01101111,我们是将0看成是最高位,1看成是最低位。
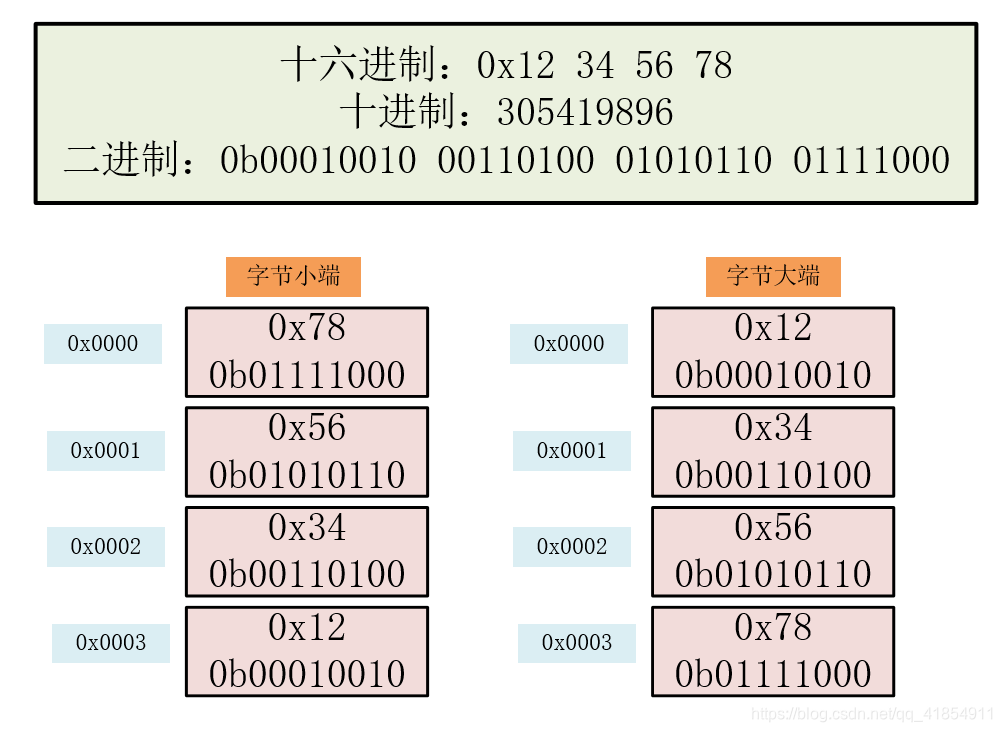
字节序大小端
大端:存储值的高位在低地址,存储值的低位在高地址。比如0x01是该数字的最高字节,但却是存储在0x100,最低的地址;0x67是该数字的最小值的字节,存储在0x103这个最高地址。
小端:存储值的高位在高地址,存储值的低位在低地址。
字节序转化函数
- uint16_t htons(uint16_t):用于将按本机字节序存储的16位整数转化为网络字节序;
- uint16_t ntohs(uint16_t):用于将按网络字节序存储的16位整数转化为本机字节序;
- uint32_t htonl(uint32_t):用于将按本机字节序存储的32位整数转化为网络字节序;
- uint32_t ntohl(uint32_t):用于将按网络字节序存储的32位整数转化为本机字节序;
以上四个函数名中,h,n,s,l分别代表主机,网络,短整数,长整数。前两个函数在网络编程中常用于转换端口号,后面个则是用于转换ipv4地址。
通过字节转换函数我们就可以在字节大小端之间根据需要进行转换。
比特序大小端
字节序是一个对象中的多个字节之间的顺序问题,比特序就是一个字节中的8个比特位(bit)之间的顺序问题。一般情况下系统的比特序和字节序是保持一致的。一个字节由8个bit组成,这8个bit也存在如何排序的情况,跟字节序类似的有最高有效比特位、最低有效比特位。比特序(LSB)1 0 0 1 0 0 1 0(MSB)在大端系统中最高有效比特位为1、最低有效比特位为0,字节的值为0x92。在小端系统中最高、最低有效比特位则相反为0、1,字节的值为0x49。跟字节序类似,要想保持一个字节值不变那么就要使系统能正确的识别最高、最低有效比特位。
-
比特序小端:将最高有效比特位放在了bit0,将最低有效比特位放在了bit7;
-
比特序大端:将最高有效比特位放在了bit7,将最低有效比特位放在了bit0;
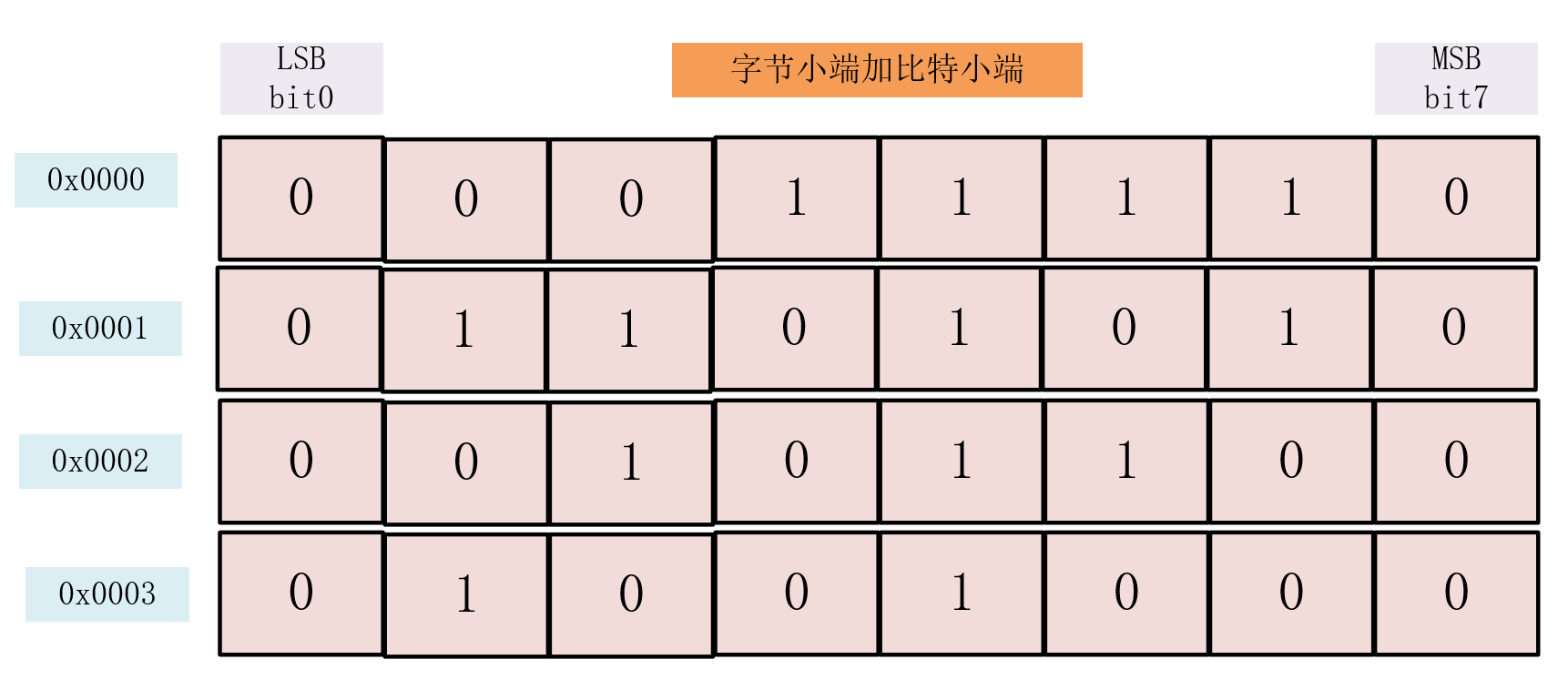
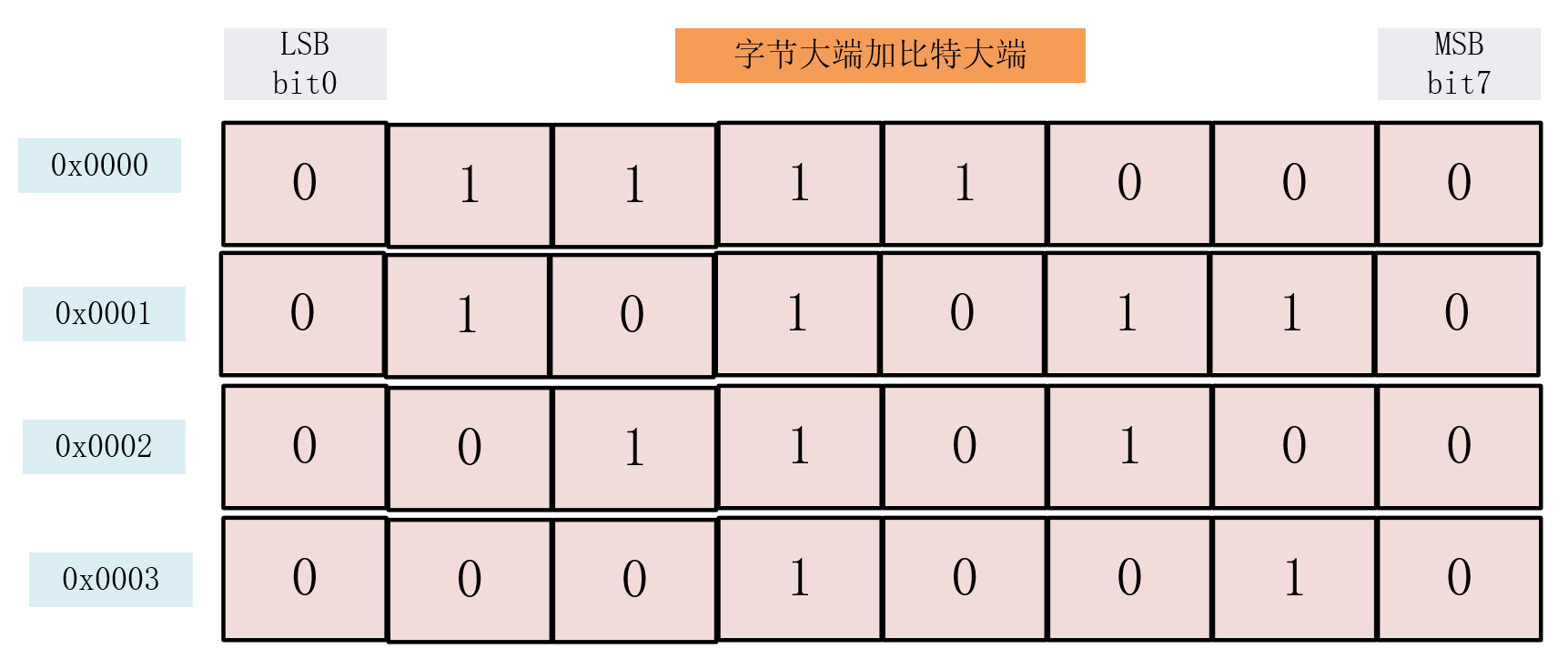
通过上图我们知道 字节地址顺序和比特顺序是不变的,大小端的不同在于机器怎么对这些地址空间进行填充。
我们可以将字节地址顺序和比特顺序看作是硬件性质。
字节序转换后我在想是不是比特序也一同进行了转换?
为什么会有这个疑问呢,因为前文可知系统的比特序和字节序是一致的,现在字节序已经从小端变成了大端那么比特序应该也要一起转换。而且如果比特序不变化那么当这些字节到了目标大端序系统中后每一个字节的值都会发生变化,因为同样的比特序列在小端和大端系统中识别的字节值会不一样。
首先从htonl、ntohl的源码来看确实只进行了字节序的转换并没有进行比特序的转换,再有就是以前socket编程的时候只调用了ntohl、htonl等函数并没有调用(而且系统也没有提供)比特序转换函数,但是最后的结果都是正确的,并没有发现上面提到的字节值发生变化的问题。
那么这个”神奇”的事情是怎么解决的呢,好像系统本身就给我们”悄悄”的解决了我担心的问题。
比特(bit)的发送和接收顺序
比特的发送、接收顺序是指一个字节中的bit在网络电缆中是如何发送、接收的。在以太网(Ethernet)中,是从最低有效比特位到最高有效比特位的发送顺序,也就是最低有效比特位首先发送,参考资料:frame。
在以太网中这个规定有点奇怪,因为字节序我们是按照大端序来发送,但是比特序却是按照小端序的方式来发送,下图是直接从网上找来的一张图,主机序本身是大端序

比特的发送、接收顺序对CPU、软件都是不可见的,因为我们的网卡会给我们处理这种转换,在发送的时候按照小端序发送比特位,在接收的时候会把接收到的比特序转换成主机的比特序,下面是一个小端机器发送一个int整型给一个大端机器的示意图:

- htonl、ntohl函数肯定是不会同步转换一个字节中的比特序的,因为如果比特序也发生了转换的话那么这个字节的值也就发生了变化,记住htonl、ntohl只是字节序转换函数。
- 比特序按照小端的方式发送,首先发送的是最低有效比特位,最后发送的是最高有效比特位,接收端的网卡在接收到比特序列后按照主机的比特序把接收到的”小端序”比特流转换成主机对应的比特序列。
- 可以假设存在ntohb、htonb(b代表bit)这样的两个函数,网卡进行了比特序的转换,不过是这两个函数是网卡自动调用的,我们平时不用关注。
按照规则,发送、接收的时候进行比特序的转换,那么就能保证在不同的机器之间进行通信不会发生我担心的字节值发生变化的问题。
大小端转换综合应用
现在假设两种应用场景:
- 大端机器接收来自小端机器的数据,在此过程中我们不做任何处理,看看应该怎么使用这个数据。
- 小端机器接收来自大端机器的数据,在此过程中我们不做任何处理,看看应该怎么使用这个数据。
大端机器接收来自小端机器的数据
假设下图是来自小端机器的数据,现在原封不动的传入到大端机器中

大端机器其实会将上图数据解释成

如果我们传输的这个4个字节的数据包含一定含义,那么在大端机器上,我们要怎么还原出这个含义呢?
假设这4个字节在原来小段机器上的含义如下图
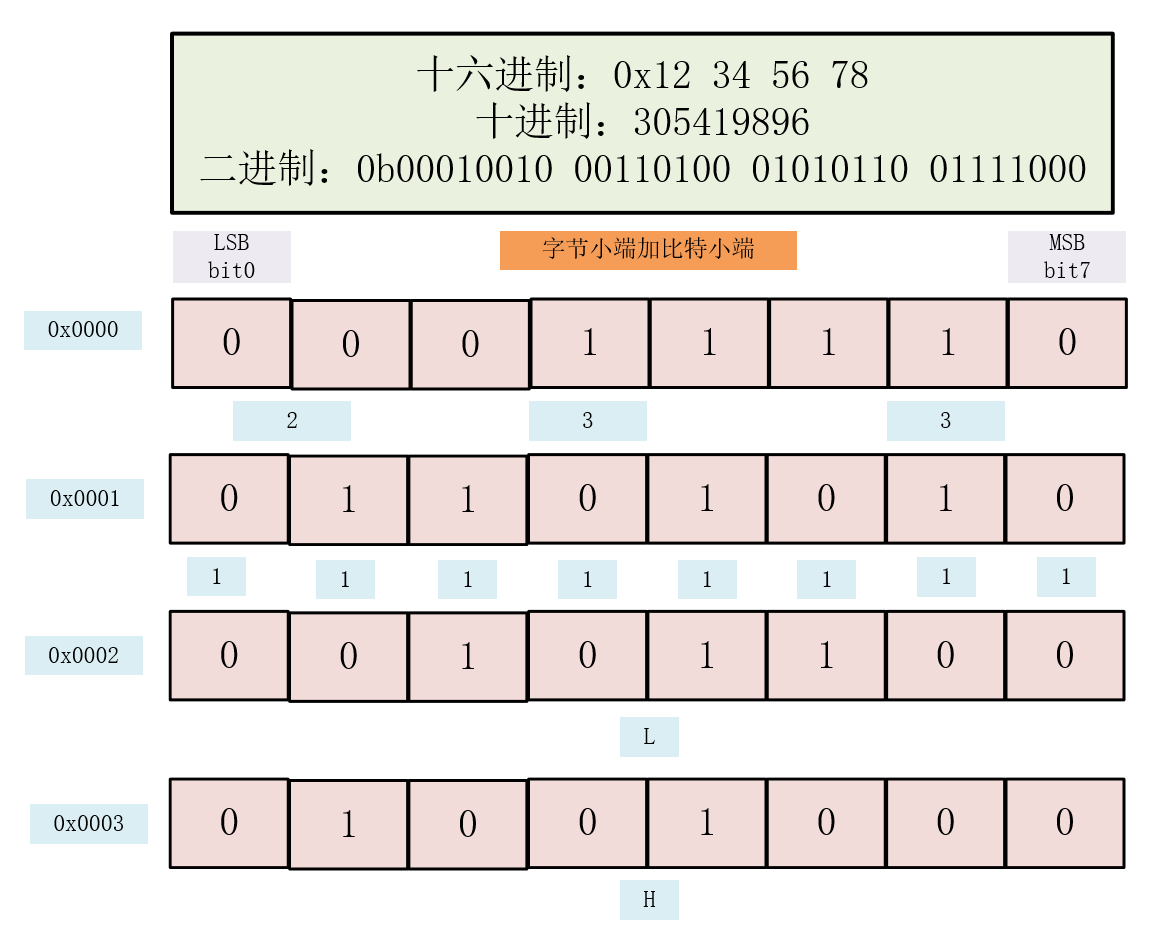
字节0x0000是一个位域
字节0x0001也是一个位域
字节0x0002和字节0x0003代表一个short整型数据的两个字节。
可以看出,要想在大端机器上还原小端机器上数据的含义还是很麻烦的。
要还原字节0x0002和字节0x0003代表的short整型数据,我们既要倒置字节的位置,还要倒置比特的位置,用起来很麻烦。
字节0x0000和字节0x0001都是使用一个字节中的位,因此还原起来还是比较简单的。因为比特序大小端的不同,原来我们在小端机器上的低位,在大端机器上就变成了高位。
如果位域中的元素每一位都是一个比特,那还比较好理解,但是如果位域中的元素超过一个比特,那应该怎么还原呢?
对于位域有一个约定:在C语言的结构体中如果包含了位域,如果位域A定义在位域B之前,那么位域A总是出现在低序的比特位。
我们还是要旋转位才能还原数据的含义。
总结
可以看出,字节大小端和比特大小端还是很多需要注意的地方,不过只有我们掌握了怎么测试机器的字节序大小端和比特序大小端,了解怎么转换字节序和比特序,我们就可以将数据还原成数据本身的含义。


















 8265
8265

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











