







storm简介
Storm 是 Twitter 开源的、分布式的、容错的实时计算系统
Storm进程常驻内存Storm数据不经过磁盘,在内存中处理
Storm 可以方便地在一个计算机集群中编写与扩展复杂的实时计算, Storm 之于实时处理,就好比 Hadoop 之于批处理。 Storm 保证每个消息都会得到处理,而且它很快——在一个小集群中,每秒可以处理数以百万计的消息。 Storm 的处理速度非常惊人:经测试,每个节点每秒可以处理 100 万个数据元组
storm的设计思想
在 Storm 中也有对流(Stream)的抽象,流是一个不间断的、无界的连续 Tuple(Storm在建模事件流时,把流中的事件抽象为 Tuple 即元组)。Storm 认为每个流都有一个 Stream 源,也就是原始元组的源头,所以它将这个源头抽象为 Spout, Spout 可能连接 Twitter API 并不断发出推文( Tweet),也可能从某个队列中不断读取队列元素并装配为 Tuple 发射。
有了源头即 Spout 也就是有了流,同样的思想, Twitter 将流的中间状态转换抽象为Bolt, Bolt 可以消费任意数量的输入流,只要将流方向导向该 Bolt,同时它也可以发送新的流给其他 Bolt 使用,这样一来,只要打开特定的 Spout(管口),再将 Spout 中流出的 Tuple导向特定的 Bolt,由 Bolt 处理导入的流后再导向其他 Bolt 或者目的地。
假设 Spout 就是一个一个的水龙头,并且每个水龙头里流出的水是不同的,想获得哪种水就拧开哪个水龙头,然后使用管道将水龙头的水导向到一个水处理器(Bolt),水处理器处理后使用管道导向另一个处理器或者存入容器中。图 1 和图 2 为 Spout、 Tuple 和 Bolt 之间的关系和流程。

图 1 Spout、 Bolt 顺序处理数据流图

图2 Bolt 多输入数据流图
为了增大水处理效率,可以在同一个水源处接上多个水龙头并使用多个水处理器,如图 3 所示。

图 3 多 Spout、多 Bolt 处理流程图
对应上文的介绍,可以很容易地理解图 3,这是一张有向无环图。 Storm 将这个图抽象为 Topology(即拓扑),拓扑是 Storm 中最高层次的一个抽象概念,提交拓扑到 Storm 集群执行,一个拓扑就是一个流转换图。图中的每个节点是一个 Spout 或者 Bolt,图中的边是指Bolt 订阅了哪些流
Topology – DAG有向无环图的实现
对于Storm实时计算逻辑的封装
即,由一系列通过数据流相互关联的Spout、Bolt所组成的拓扑结构
生命周期:此拓扑只要启动就会一直在集群中运行,直到手动将其kill,否则不会终止
(区别于MapReduce当中的Job,MR当中的Job在计算执行完成就会终止)
Tuple – 元组
Stream中最小数据组成单元
Stream – 数据流
从Spout中源源不断传递数据给Bolt、以及上一个Bolt传递数据给下一个Bolt,所形成的这些数据通道即叫做Stream
Stream声明时需给其指定一个Id(默认为Default)
实际开发场景中,多使用单一数据流,此时不需要单独指定StreamId
Spout – 数据源
拓扑中数据流的来源。一般会从指定外部的数据源读取元组(Tuple)发送到拓扑(Topology)中
一个Spout可以发送多个数据流(Stream)
可先通过OutputFieldsDeclarer中的declare方法声明定义的不同数据流,发送数据时通过SpoutOutputCollector中的emit方法指定数据流Id(streamId)参数将数据发送出去
Spout中最核心的方法是nextTuple,该方法会被Storm线程不断调用、主动从数据源拉取数据,再通过emit方法将数据生成元组(Tuple)发送给之后的Bolt计算
Bolt – 数据流处理组件
拓扑中数据处理均有Bolt完成。对于简单的任务或者数据流转换,单个Bolt可以简单实现;更加复杂场景往往需要多个Bolt分多个步骤完成
一个Bolt可以发送多个数据流(Stream)
可先通过OutputFieldsDeclarer中的declare方法声明定义的不同数据流,发送数据时通过SpoutOutputCollector中的emit方法指定数据流Id(streamId)参数将数据发送出去
Bolt中最核心的方法是execute方法,该方法负责接收到一个元组(Tuple)数据、真正实现核心的业务逻辑
Stream Grouping – 数据流分组(即数据分发策略)
Storm 架构设计
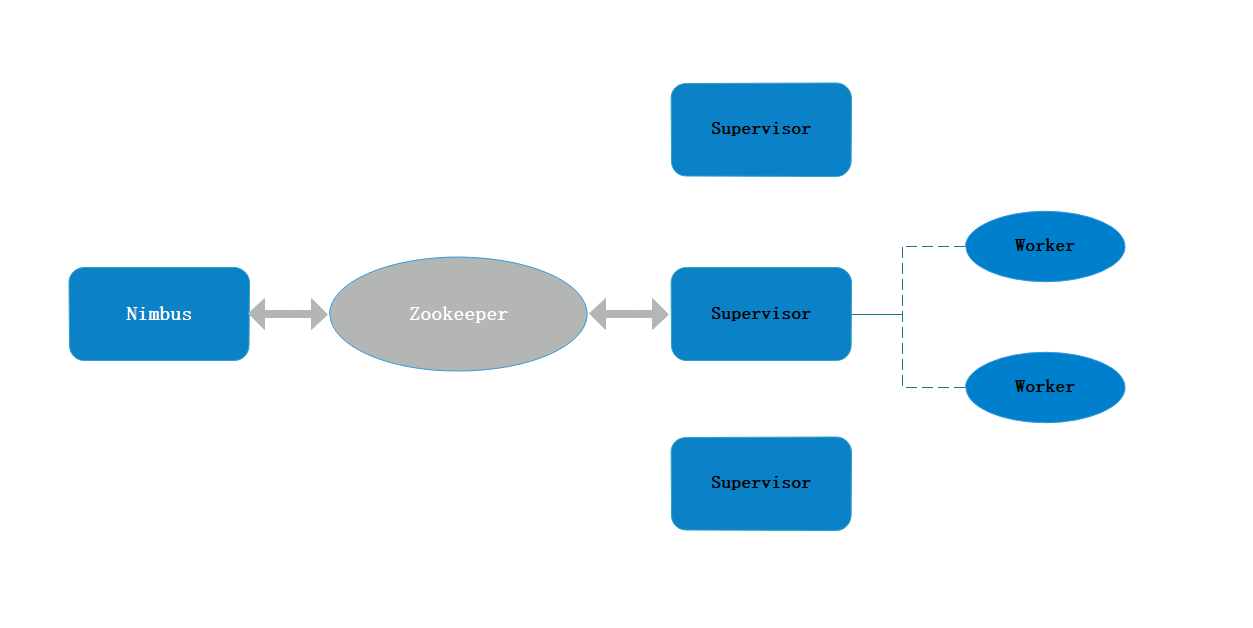
Nimbus、 Supervisor 与 ZooKeeper 关系图
1、主节点 Nimbus
主节点通常运行一个后台程序——Nimbus,用于响应分布在集群中的节点,分配任务和监测故障,这类似于 Hadoop 中的 JobTracker。
Nimbus 进程是快速失败( fail-fast)和无状态的,所有的状态要么在 ZooKeeper 中,要么在本地磁盘上。可以使用 kill -9 来杀死 Nimbus 进程,然后重启即可继续工作。
2、工作节点 Supervisor
工作节点同样会运行一个后台程序——Supervisor,用于收听工作指派并基于要求运行工作进程。每个工作节点都是Topology中一个子集的实现。而Nimbus 和 Supervisor 之间的协调则通过 ZooKeeper 系统。
同 样,Supervisor进程也是快速失败(fail-fast)和无状态的, 所有的状态要么在ZooKeeper中,要么在本地磁盘上,用kill -9来杀死Supervisor进程,然后重启就可以继续工作。
ZooKeeper 是完成 Nimbus 和 Supervisor 之间协调的服务。 Storm使用ZooKeeper 协调集群,由于ZooKeeper 并不用于消息传递,所以Storm给ZooKeeper 带来的压力相当低。 在大多数情况下,单个节点的 ZooKeeper 集群足够胜任,不过为了确保故障恢复或者部署大规模Storm集群,可能需要更大规模的 ZooKeeper 集群 。 Nimbus、 Supervisor 与 ZooKeeper 的关系如图 1 所示。
4、其他核心组件
Storm 的组件不止上面的,还有一些组件也是 Storm 的核心,缺一不可。下面简单介绍Worker 和 Task。
1)具体处理事务进程 Worker:运行具体处理组件逻辑的进程。
2)具体处理线程 Task : Worker 中的每一个 Spout/Bolt 线程称为一个 Task。在 Storm 0.8之后, Task 不再与物理线程对应,同一个 Spout/Bolt 的 Task 可能会共享一个物理线程,该线程称为 Executor。
Storm与Hadoop、SprakStreaming简单对比
Storm:进程、线程常驻内存运行,数据不进入磁盘,数据通过网络传递。
MapReduce:为TB、PB级别数据设计的批处理计算框架。


Storm:纯流式处理
专门为流式处理设计
数据传输模式更为简单,很多地方也更为高效
并不是不能做批处理,它也可以来做微批处理,来提高吞吐
Spark Streaming:微批处理
将RDD做的很小来用小的批处理来接近流式处理
基于内存和DAG可以把处理任务做的很快
















 7562
7562

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









