






 本文介绍了Python爬虫库autoscraper,教你如何快速安装并抓取链家房产信息,包括单个和批量抓取,以及结果查看和规则管理。
本文介绍了Python爬虫库autoscraper,教你如何快速安装并抓取链家房产信息,包括单个和批量抓取,以及结果查看和规则管理。
5分钟学会Python爬虫神器autoscraper——自动化爬虫必备
爬虫神器autoscraper介绍
今天给大家介绍一个非常智能的python爬虫库,5分钟就能上手,简直就是爬虫神器。它的名字就是autoscraper,GitHub主页是https://github.com/alirezamika/autoscraper ,截止2021年5月16日,star有3.5k,非常受欢迎。
安装
# 首先安装autoscraper,目前只支持python3
# 使用 pip 从 git 仓库安装最新版本
# pip install git+https://github.com/alirezamika/autoscraper.git
# 下载源码安装
# python setup.py install
# 从 PyPI 安装(推荐)
# pip install autoscraper
使用
比如我们要抓取链家上房屋信息数据,标题,销售价格,单价,房屋结构信息,网址等信息。
如下:
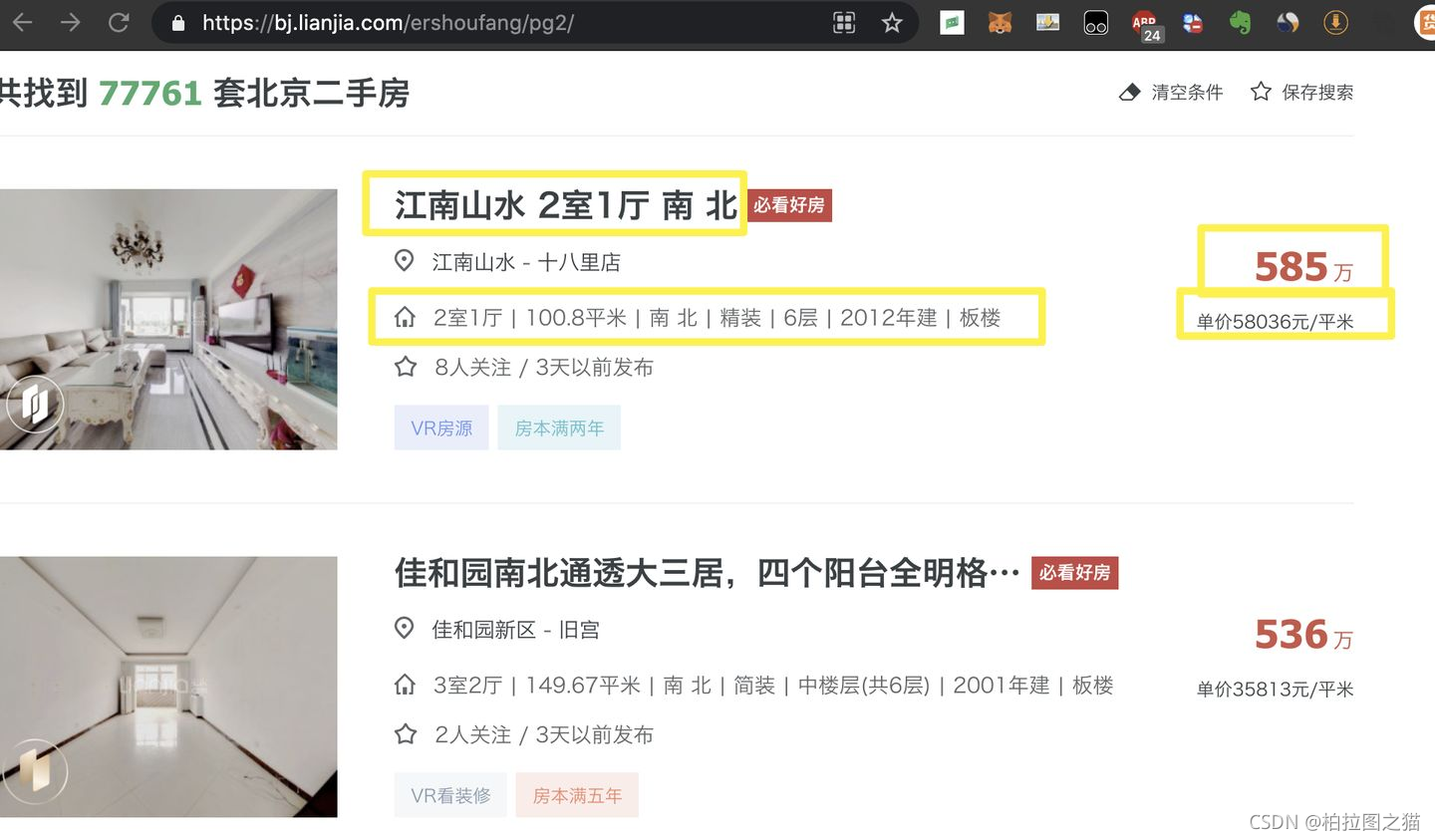
# 单个信息抓取
from autoscraper import AutoScraper
# 抓取的网址
url = 'https://bj.lianjia.com/ershoufang/pg2/'
# 输入你想抓取的标题信息(我们先随便写一个标题)
wanted_list = ["江南山水 2室1厅 南 北"]
scraper = AutoScraper()
result = scraper.build(url, wanted_list)
# 这样就把页面里面所有的标题都抓下来了
result
['江南山水 2室1厅 南 北',
'佳和园南北通透大三居,四个阳台全明格局,满五唯一',
'满5年眼镜户型,南北双通透,两梯两户,无遮挡',
'公元九里四居室洋房,次顶层,一天未住。',
'前半壁街 南北两居室 诚意出售',
'名都园 别墅区带电梯南北三居室 有钥匙看房随时',
'石景山五芳园 精装两居室 低楼层',
'御景园小区 东北向三居室 房子看房方便 看国贸',
'牡丹园马甸月季园小区优质三居室',
'二环里 东城区 两居室 采光好 无遮挡 满五年唯一',
'大屯里 东西三居 看房随时 诚意出售',
'华纺易城 满五年 东区中间位置 观景房 安静 南北通透',
'满五年唯一,有产权车位单独出售,中间单元,不临街',
'此房满五年唯一,格局好,明厨明卫,近地铁,近公园',
'阜光里小区 有电梯 满五年 户型方正',
'柏林爱乐四期 2室1厅 南 北',
'正阳小区 2室1厅 东',
'电信宿舍六层板楼带电梯 前后阳台 无遮挡',
'满五唯一商品房 四环内 正规三居室',
'金隅悦和园 正对小区花园 南向两居室采光充足',
'满五年唯一,房屋状况保持好,看房提前约。',
'郁花园一里 满五年唯一 中间楼层两居 看房随时',
'清河后屯路32号院南北通透三居室',
'八角北里中间层 南北通透 看房随时',
'杨庄北区 3室1厅 南 北',
'冬季星空 南北通透三居室 满五唯一',
'东三环 朝阳区 伯宁花园西北向三居室',
'全明格局,南北双通透,宜居H户型,室内2.8米层高',
'富东嘉园 2室1厅 南 北',
'安苑北里精装修两室两厅,视野好,采光好']
# 多个信息抓取,可以使用dict字典来存要抓取的信息
from autoscraper import AutoScraper
url = 'https://bj.lianjia.com/ershoufang/pg2/'
# 输入你想抓取的信息(我们先写几个)
wanted_dict = {'title': ["江南山水 2室1厅 南 北"],
'intro': ['2室1厅 | 100.8平米 | 南 北 | 精装 | 6层 | 2012年建 | 板楼'],
'total_price': ['585万']}
scraper = None
scraper = AutoScraper()
scraper.build(url=url, wanted_dict=wanted_dict)
result = scraper.get_result_similar(url=url, grouped=True)
result
{'rule_nf8n': ['江南山水 2室1厅 南 北',
'佳和园南北通透大三居,四个阳台全明格局,满五唯一',
'满5年眼镜户型,南北双通透,两梯两户,无遮挡',
'公元九里四居室洋房,次顶层,一天未住。',
'前半壁街 南北两居室 诚意出售',
'御景园小区 东北向三居室 房子看房方便 看国贸',
'石景山五芳园 精装两居室 低楼层',
'名都园 别墅区带电梯南北三居室 有钥匙看房随时',
'牡丹园马甸月季园小区优质三居室',
'清河后屯路32号院南北通透三居室',
'满五年唯一,房屋状况保持好,看房提前约。',
'郁花园一里 满五年唯一 中间楼层两居 看房随时',
'柏林爱乐四期 2室1厅 南 北',
'满五唯一商品房 四环内 正规三居室',
'华纺易城 满五年 东区中间位置 观景房 安静 南北通透',
'二环里 东城区 两居室 采光好 无遮挡 满五年唯一',
'电信宿舍六层板楼带电梯 前后阳台 无遮挡',
'大屯里 东西三居 看房随时 诚意出售',
'阜光里小区 有电梯 满五年 户型方正',
'正阳小区 2室1厅 东',
'金隅悦和园 正对小区花园 南向两居室采光充足',
'八角北里中间层 南北通透 看房随时',
'满五年唯一,有产权车位单独出售,中间单元,不临街',
'此房满五年唯一,格局好,明厨明卫,近地铁,近公园',
'安苑北里精装修两室两厅,视野好,采光好',
'六合园新华社院 中间楼层 满五年 随时看房',
'富东嘉园 2室1厅 南 北',
'北洼西里正规三居业主诚心出售可随时看房',
'怡海花园@南北通透@双卫,全明格局@配套齐全',
'海淀区田村路48号院精致全南两居'],
'rule_9yc0': ['江南山水 2室1厅 南 北',
'佳和园南北通透大三居,四个阳台全明格局,满五唯一',
'满5年眼镜户型,南北双通透,两梯两户,无遮挡',
'公元九里四居室洋房,次顶层,一天未住。',
'前半壁街 南北两居室 诚意出售',
'御景园小区 东北向三居室 房子看房方便 看国贸',
'石景山五芳园 精装两居室 低楼层',
'名都园 别墅区带电梯南北三居室 有钥匙看房随时',
'牡丹园马甸月季园小区优质三居室',
'清河后屯路32号院南北通透三居室',
'满五年唯一,房屋状况保持好,看房提前约。',
'郁花园一里 满五年唯一 中间楼层两居 看房随时',
'柏林爱乐四期 2室1厅 南 北',
'满五唯一商品房 四环内 正规三居室',
'华纺易城 满五年 东区中间位置 观景房 安静 南北通透',
'二环里 东城区 两居室 采光好 无遮挡 满五年唯一',
'电信宿舍六层板楼带电梯 前后阳台 无遮挡',
'大屯里 东西三居 看房随时 诚意出售',
'阜光里小区 有电梯 满五年 户型方正',
'正阳小区 2室1厅 东',
'金隅悦和园 正对小区花园 南向两居室采光充足',
'八角北里中间层 南北通透 看房随时',
'满五年唯一,有产权车位单独出售,中间单元,不临街',
'此房满五年唯一,格局好,明厨明卫,近地铁,近公园',
'安苑北里精装修两室两厅,视野好,采光好',
'六合园新华社院 中间楼层 满五年 随时看房',
'富东嘉园 2室1厅 南 北',
'北洼西里正规三居业主诚心出售可随时看房',
'怡海花园@南北通透@双卫,全明格局@配套齐全',
'海淀区田村路48号院精致全南两居'],
'rule_wjo7': ['2室1厅 | 100.8平米 | 南 北 | 精装 | 6层 | 2012年建 | 板楼',
'3室2厅 | 149.67平米 | 南 北 | 简装 | 中楼层(共6层) | 2001年建 | 板楼',
'3室1厅 | 151.39平米 | 南 北 | 精装 | 低楼层(共20层) | 2008年建 | 板楼',
'4室2厅 | 180.57平米 | 南 北 | 精装 | 中楼层(共7层) | 2012年建 | 板楼',
'2室1厅 | 56.7平米 | 南 北 | 其他 | 顶层(共6层) | 1989年建 | 板楼',
'3室2厅 | 206.94平米 | 东北 | 精装 | 中楼层(共33层) | 2001年建 | 塔楼',
'2室1厅 | 64.67平米 | 南 | 精装 | 底层(共6层) | 1994年建 | 板楼',
'3室2厅 | 145.32平米 | 南 北 | 精装 | 中楼层(共6层) | 2000年建 | 板楼',
'3室1厅 | 79.7平米 | 东南 西北 | 精装 | 中楼层(共20层) | 1995年建 | 塔楼',
'3室1厅 | 67.9平米 | 南 北 | 简装 | 底层(共6层) | 1993年建 | 板楼',
'3室1厅 | 103.8平米 | 南 北 | 简装 | 底层(共6层) | 2004年建 | 板楼',
'2室2厅 | 83.39平米 | 南 北 | 简装 | 中楼层(共7层) | 1996年建 | 板楼',
'2室1厅 | 102.03平米 | 南 北 | 精装 | 低楼层(共8层) | 2008年建 | 板楼',
'3室1厅 | 76.42平米 | 东 西 | 精装 | 高楼层(共6层) | 1992年建 | 板楼',
'3室2厅 | 128.06平米 | 南 北 | 简装 | 中楼层(共12层) | 2005年建 | 板楼',
'2室1厅 | 54.72平米 | 西北 | 简装 | 高楼层(共6层) | 1970年建 | 板楼',
'3室2厅 | 153.6平米 | 南 北 | 精装 | 低楼层(共6层) | 1999年建 | 板楼',
'3室1厅 | 115.13平米 | 东 西 | 简装 | 低楼层(共24层) | 2003年建 | 塔楼',
'2室2厅 | 82.33平米 | 南 北 | 简装 | 低楼层(共14层) | 1996年建 | 板楼',
'2室1厅 | 82.78平米 | 东 | 简装 | 中楼层(共14层) | 2000年建 | 板塔结合',
'2室2厅 | 78.38平米 | 南 | 精装 | 低楼层(共28层) | 板塔结合',
'3室1厅 | 68.43平米 | 南 北 | 简装 | 中楼层(共6层) | 1986年建 | 板楼',
'3室1厅 | 112.03平米 | 南 北 | 精装 | 低楼层(共27层) | 2014年建 | 板楼',
'2室1厅 | 69.59平米 | 东北 | 简装 | 底层(共17层) | 1988年建 | 塔楼',
'2室2厅 | 70.37平米 | 西南 | 精装 | 低楼层(共25层) | 1989年建 | 塔楼',
'2室1厅 | 64.38平米 | 东 北 | 简装 | 低楼层(共22层) | 1996年建 | 塔楼',
'2室1厅 | 80.83平米 | 南 北 | 简装 | 中楼层(共10层) | 2007年建 | 板楼',
'3室1厅 | 81.2平米 | 西南 | 精装 | 中楼层(共18层) | 1990年建 | 塔楼',
'3室1厅 | 121.16平米 | 南 北 | 精装 | 低楼层(共6层) | 1998年建 | 板楼',
'2室1厅 | 53.3平米 | 南 | 简装 | 中楼层(共6层) | 1982年建 | 板楼'],
'rule_euvr': ['585万',
'536万',
'1340万',
'1170万',
'779万',
'928万',
'289万',
'690万',
'838万',
'530万',
'479万',
'380万',
'650万',
'369万',
'1150万',
'495万',
'2611万',
'668万',
'880万',
'538万',
'395万',
'385万',
'555万',
'459万',
'565万',
'360万',
'470万',
'830万',
'695万',
'415万'],
'rule_da1p': ['585万',
'536万',
'1340万',
'1170万',
'779万',
'928万',
'289万',
'690万',
'838万',
'530万',
'479万',
'380万',
'650万',
'369万',
'1150万',
'495万',
'2611万',
'668万',
'880万',
'538万',
'395万',
'385万',
'555万',
'459万',
'565万',
'360万',
'470万',
'830万',
'695万',
'415万']}
批量抓取
上面只是抓了一个网页,对于需要抓取很多网页,那我们就需要保存上面设计的规则,然后应用在其他网页上。
# 看下结果里面的keys
result.keys()
# dict_keys(['rule_nf8n', 'rule_9yc0', 'rule_wjo7', 'rule_euvr', 'rule_da1p'])
# 保存其中需要的几个keys(因为上面数据里面有重复,所以我们这里选择需要的几个)
# 这写规则名字可能不太一样,随机的,需要根据你的结果来调整
scraper.keep_rules(['rule_nf8n', 'rule_wjo7', 'rule_da1p'])
scraper.save('lianjia-search2')
# 加载上面保存的规则
lianjia_scraper = None
lianjia_scraper = AutoScraper()
lianjia_scraper.load('lianjia-search2')
import pandas as pd
df = pd.DataFrame()
# 批量抓取二手房信息
for n in range(1, 10):
url = f'https://bj.lianjia.com/ershoufang/pg{n}'
print(url)
result = lianjia_scraper.get_result_similar(url=url, group_by_alias=True)
df = pd.concat([df, pd.DataFrame(result)])
# print(result)
# https://bj.lianjia.com/ershoufang/pg1
# https://bj.lianjia.com/ershoufang/pg2
# https://bj.lianjia.com/ershoufang/pg3
# https://bj.lianjia.com/ershoufang/pg4
# https://bj.lianjia.com/ershoufang/pg5
# https://bj.lianjia.com/ershoufang/pg6
# https://bj.lianjia.com/ershoufang/pg7
# https://bj.lianjia.com/ershoufang/pg8
# https://bj.lianjia.com/ershoufang/pg9
查看结果
df.shape
# (270, 3)
df.reset_index(drop=True).head(10)
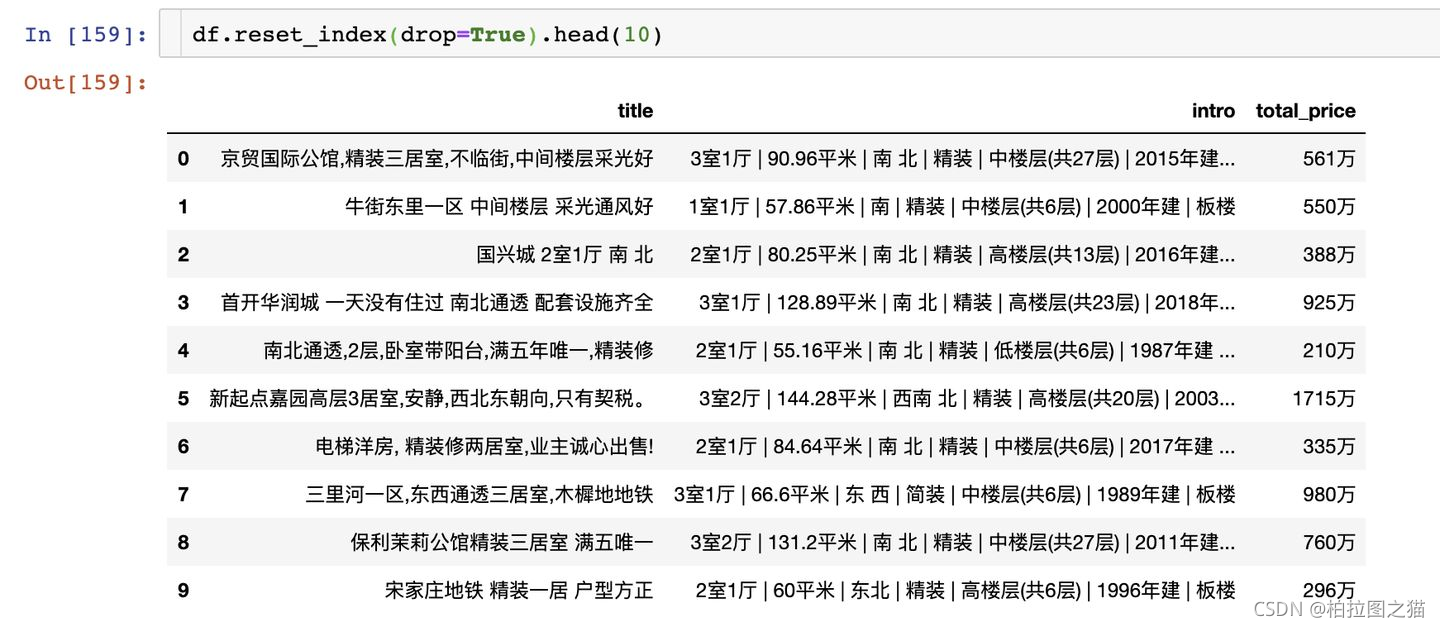
这样就可以批量抓取网页数据了!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











