







 一、序列编码目前主流的处理序列问题像机器翻译,文档摘要,对话系统,QA等都是encoder和decoder框架,编码器:从单词序列到句子表示解码器:从句子表示转化为单词序列分布1、第一个基本的思路是 RNN 层RNN 的方案很简单,递归式进行:但是,这种方式会有一个问题:对于长句子的翻译会造成一定的困难,而attention机制的引入可以解决这个问题。(为什么引入注...
一、序列编码目前主流的处理序列问题像机器翻译,文档摘要,对话系统,QA等都是encoder和decoder框架,编码器:从单词序列到句子表示解码器:从句子表示转化为单词序列分布1、第一个基本的思路是 RNN 层RNN 的方案很简单,递归式进行:但是,这种方式会有一个问题:对于长句子的翻译会造成一定的困难,而attention机制的引入可以解决这个问题。(为什么引入注...
一、序列编码
目前主流的处理序列问题像机器翻译,文档摘要,对话系统,QA等都是encoder和decoder框架,
编码器:从单词序列到句子表示
解码器:从句子表示转化为单词序列分布
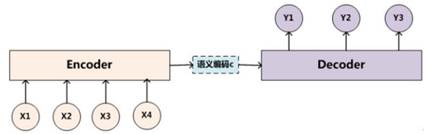
1、第一个基本的思路是 RNN 层
RNN 的方案很简单,递归式进行:
![]()
但是,这种方式会有一个问题:对于长句子的翻译会造成一定的困难,而attention机制的引入可以解决这个问题。(为什么引入注意力模型?因为没有引入注意力的模型在输入句子比较短的时候问题不大,但是如果输入的句子比较长,此时所有语义完全通过一个中间语义向量来表示,单词自身的信息已经消失,可想而知会丢失很多的细节信息,所以要引入注意力机制)如下图所示:
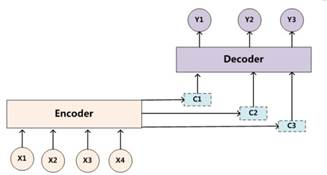
理解Attention模型的关键就是,由固定的中间语义表示C换成了根据当前输出单词来调整成加入注意力模型的变化的Ci.而每个Ci可能对应着不同的源语句子单词的注意力分配概率分布。
RNN+Attention:
这里,我们可以看到,decoder得到的序列中有几个输出值,对应的语义编码c则有相同的数量,即一个语义编码ci对应一个输出yi。而每个ci就是由attention机制得到,具体公式如下:
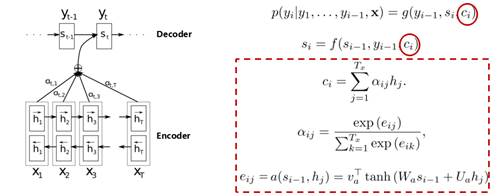
其中:ci:encoder序列加权得到的值; si: ; yt:
Neural machine translation by jointly learning to align and translate
这篇论文首先将注意力机制运用在NLP上,提出了soft Attention Model,并将其应用到了机器翻译上面。其实,所谓Soft,意思是在求注意力分配概率分布的时候,对于输入句子X中任意一个单词都给出个概率,是个概率分布。加入注意力机制的模型表现确实更好,但也存在一定问题,例如:attention mechanism通常和RNN结合使用,我们都知道RNN依赖t-1的历史信息来计算t时刻的信息,因此不能并行实现,计算效率比较低,特别是训练样本量非常大的时候。
不管是已经被广泛使用的 LSTM、GRU 还是最近的 SRU,都并未脱离这个递归框架。RNN 结构本身比较简单,也很适合序列建模,但 RNN 的明显缺点之一就是无法并行,因此速度较慢,这是递归的天然缺陷。
另外我个人觉得 RNN 无法很好地学习到全局的结构信息,因为它本质是一个马尔科夫决策过程。
2、第二个思路是 CNN 层
其实 CNN 的方案也是很自然的,窗口式遍历,比如尺寸为 3 的卷积,就是:
![]()
基于CNN的Seq2Seq模型具有基于RNN的Seq2Seq模型捕捉long distance dependency的能力,此外,最大的优点是可以并行化实现,效率比基于RNN的Seq2Seq模型高。缺点:计算量与观测序列X和输出序列Y的长度成正比。
CNN+Attention:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2661
2661











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









