







Spark on yarn的 两种运行模式和运行原理
一 回顾—spark和mapreduce区别
在MapReduce中,计算的最上层单元是是job,系统加载数据,执行一个map函数,shuffle数据,执行一个reduce函数,然后将数据写回到持久化存储器,Spark有一个类似job的概念(虽然一个job可以由多个stage组成,而不是仅仅只包含map和reduce),不过Spark还有一个更高层级的概念叫做应用程序(application),应用程序可以以并行或者串行的方式跑多个job。

熟悉Spark API的人都知道,一个应用程序对应着一个SparkContext类的实例。不同于MapReduce,一个应用程序拥有一系列进程,叫做executors,他们在集群上运行,即使没有job在运行,这些executor仍然被这个应用程序占有。这种方式让数据存储在内存中,以支持快速访问,同时让task快速启动成为现实。
Executors
MapReduce的每个task是在其自己的进程中运行的,当一个task结束,进程随之终结。在Spark中,多个task可以在同一个进程中并行的执行,并且这些进程常驻在Spark应用程序的整个生命周期中,即使是没有job在运行的时候。上述Spark模型的优势在于速度:task可以快速的启动,处理内存中的数据。不过他的缺点是粗粒度的资源管理。因为一个应用程序的executor数量是固定的,并且每个executor有固定的资源分配,一个应用程序在其整个运行周期中始终占有相同数量的资源。
活跃的Driver
Spark需要依赖一个活跃的driver(active driver)进程来管理job和调度task【拥有Application Master线程对象,对象中包含SparkContext对象,该对象中拥有DAG Scheduler,YarnClusterScheduler等实现管理job和调度task】。一般的,这个driver进程跟启动应用程序的客户端进程是同一个,不过在YARN模式中(后面会讲到),driver进程可以在集群中运行。相反的,在MapReduce中,客户端进程在job启动之后可以退出,而job还会继续运行。
可插拔的资源管理
Spark支持可插拔的集群管理。集群资源管理系统负责启动executor进程。Spark应用开发人员不必担心spark到底使用哪一种集群管理系统。Spark支持yarn,Mesos以及自带的standalone集群资源管理系统。这三个系统都包含了两个组件【master服务组件;slave服务组件(具体可能叫nodemanager,or worker等)】。Master服务(yarn :ResourceManager、Mesos:master或者Spark自带的standalone:master),master服务主要负责决定哪个应用程序运行(或者使用)Executor进程,同时也决定在哪儿、什么时候运行。每个节点上运行一个slave服务,启动Executor进程。资源管理系统同时还监控服务的可用性和资源消耗。
为什么使用YARN
使用YARN来管理集群资源较使用Spark standalone和Mesos有一些优势:yarn集中配置一个资源池,允许运行在yarn上的不同架构动态共享这个资源池。你可以用整个集群跑一个MapReduce任务,然后使用其中一部分做一次Impala查询,另一部分运行一个Spark应用程序,并且完全不用修改任何配置。
你可以利用YARN的所有调度特性来做分类、隔离以及任务优先。
还有一点,yarn是唯一支持spark安全特性的集群资源管理系统。使用yarn、spark可以在Kerberized Hadoop之上运行,在它的进程之间使用安全认证
Yarn在spark上运行
当代yarn·上运行spark时,每一个spark executor作为一个yarn container运行。MapReduce为每一个task生车一个container并启动一个JVM,二spark在同一个container中执行多个task。Spark这种方式让spark的运行速度快了几个量级。
理解理解YARN应用程序的master概念:在yarn中,每一个应用程序都有一个master进程,它是为应用程序启动的第一个container(AppalicationMaster)。负责为应用程序从ResourceManager申请资源,同时分配这些资源,告诉NodeManagers为该应用程序启动container。Master的存在,就可以避免一个活跃的客户端-启动程序的进程(启动程序后可以退出,交给yarn负责)可以进退,而由yarn管理这些进程,他们继续在集群中运行。
Yarn-cluster模式中,Driver在master上运行,这意味着这个进程(ApplicationMaster进程)同时负责驱动应用程序和向yarn申请资源,并且这个进程在yarn container中运行。启动应用程序的客户端不用常驻在应用程序的运行周期中。
Yarn-cluster模式:
两个图都挺好的:
 -
-

-
注意ApplicationMaster进程中包含的哪些
(1)ResourceManager接到请求后在集群中选择一个NodeManager分配Container,并在Container中启动ApplicationMaster进程;
(2)在ApplicationMaster进程中初始化sparkContext;
(3)ApplicationMaster向ResourceManager申请到Container后,通知NodeManager在获得的Container中启动excutor进程;
(4)sparkContext分配Task给excutor,excutor发送运行状态给ApplicationMaster。
YARN-client模式:
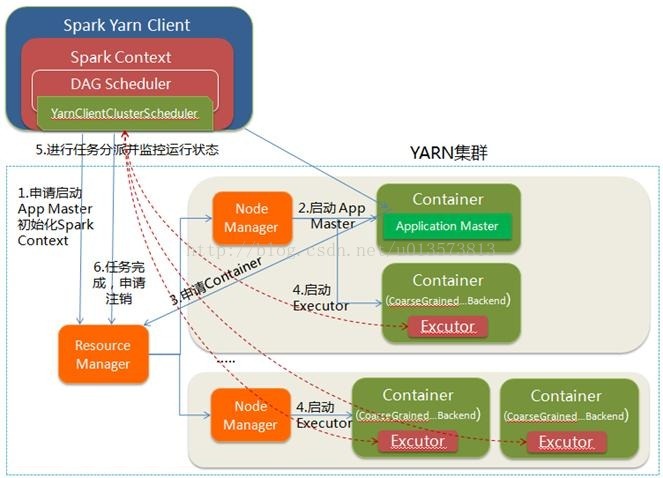
(1)ResourceManager接到请求后在集群中选择一个NodeManager分配Container,并在Container中启动ApplicationMaster进程;
(2)driver进程运行在client中,并初始化sparkContext;
(3)sparkContext初始化完后与ApplicationMaster通讯,通过ApplicationMaster向ResourceManager申请Container,ApplicationMaster通知NodeManager在获得的Container中启动excutor进程;
(4)sparkContext分配Task给excutor,excutor发送运行状态给driver
Yarn-client模式中,master仅仅出现在向yarn申请executor container的过程中。yarn-cluster中ApplicationMaster不仅负责申请资源,并负责监控Task的运行状况,因此可以关掉client;
而yarn-client中ApplicationMaster仅负责申请资源,由client中的driver来监控调度Task的运行,因此不能关掉client。
一些重要的概念:
应用程序(Application):应用程序可以是一个单独的job,也可以是一系列的job,或者是一个持续的可以进行交互的会话服务。
Spark Driver:Spark Driver是spark上下文(SparkContext—代表一个应用程序会话)中运行的一个进程。Driver负责将应用程序转化成可以在集群上运行的独立的步骤(我认为是按照action算子来的)。每个应用程序有一个driver。--drver还和clusterManager通讯,进行资源申请,任务分配并监督运行状况等。
ClusterManager:这里指yarn
DAGScheduler:把spark作业转换成stage的DAG图。
TaskScheduler:把task分配给具体的executor。
Spark ApplicationMaster:master负责接收driver的资源请求,然后向yarn申请资源—当然是想resourcemanager申请,并选择一组合适的hosts/containers来运行spark程序—获取nodemanager为其分配启动container。每个应用程序有一个master。
Container:yarn中的抽象资源。
Spark Executor:在计算节点上的JVM实例,服务于一个单独的spark应用程序。一个executor在她的生命周期中可以运行多个task,这些task可以是并行运行的。一个节点可能有多个executor,一个应用程序又会有多个结点在运行executor。
Spark task:一个spark task表示一个任务单元,它在一个分区上运行,处理数据的一个子集。
ResourceManager:负责整个yarn集群的资源管理和分配。
参考:http://www.xiutx.cn/archives/116















 1187
1187

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









