







1.1.1、Dynamic Allocation
1.1.1.1 参数说明
- 1.2 版本
| 参数名及默认值 | 含义 |
|---|---|
| spark.dynamicAllocation.enabled = false | 是否开启动态资源分配,主要是基于集群负载分配executor |
| spark.dynamicAllocation.executorIdleTimeout=60s | executor空闲时间达到规定值,则将该executor移除。 |
| spark.dynamicAllocation.maxExecutors=infinity | 最多使用的executor数,默认为你申请的最大executor数 |
| spark.dynamicAllocation.minExecutors=0 | 最少保留的executor数 |
| spark.dynamicAllocation.schedulerBacklogTimeout=1s | 有task等待运行时间超过该值后开始启动executor |
| spark.dynamicAllocation.sustainedSchedulerBacklogTimeout=schedulerBacklogTimeout | 动态启动executor的间隔 |
- 1.3 版本
| 参数名及默认值 | 含义 |
|---|---|
| spark.dynamicAllocation.initialExecutors=spark.dynamicAllocation.minExecutors | 启动的初始executor数 |
- 1.4版本
| 参数名及默认值 | 含义 |
|---|---|
| spark.dynamicAllocation.cachedExecutorIdleTimeout=infinity | 缓存了数据的executor如果超过该值仍然空闲 会被移除 |
- 2.4版本
| 参数名及默认值 | 含义 |
|---|---|
| spark.dynamicAllocation.executorAllocationRatio=1 | 默认动态分配会请求很多executor以实现最大并行度,但对于小任务而言,该策略反而会造成资源浪费。该值会受最大最小executor数的影响 |
- 3.0版本
| 参数名及默认值 | 含义 |
|---|---|
| spark.dynamicAllocation.shuffleTracking.enabled=false | 为executor开启shuffle文件跟踪(即存储shuffle数据),避免动态分配依赖外部shuffle服务。 |
| spark.dynamicAllocation.shuffleTracking.timeout=infinity | 当shuffle跟踪开启后,控制executor存储shuffle数据的超时时间, |
1.1.1.2 源码分析
最开始生效位置 : org.apache.spark.SparkContext#_executorAllocationManager
// 动态分配参数必须 在非local环境下才能生效,
val dynamicAllocationEnabled = Utils.isDynamicAllocationEnabled(_conf)
_executorAllocationManager =
if (dynamicAllocationEnabled) {
schedulerBackend match {
case b: ExecutorAllocationClient =>
// 动态分配资源交给 动态分配管理器对象来 实现
Some(new ExecutorAllocationManager(
schedulerBackend.asInstanceOf[ExecutorAllocationClient], listenerBus, _conf,
cleaner = cleaner, resourceProfileManager = resourceProfileManager))
case _ =>
None
}
} else {
None
}
// 调用 ExecutorAllocationManager 的start方法
_executorAllocationManager.foreach(_.start())
def isDynamicAllocationEnabled(conf: SparkConf): Boolean = {
// DYN_ALLOCATION_ENABLED 对应 spark.dynamicAllocation.enabled参数
val dynamicAllocationEnabled = conf.get(DYN_ALLOCATION_ENABLED)
dynamicAllocationEnabled &&
(!isLocalMaster(conf) || conf.get(DYN_ALLOCATION_TESTING))
}
// 运行模式必须非本地,才能使用动态资源分配
def isLocalMaster(conf: SparkConf): Boolean = {
val master = conf.get("spark.master", "")
master == "local" || master.startsWith("local[")
}
1.1.1.2.1 ExecutorAllocationManager
动态资源分配的工作,全部交由ExecutorAllocationManager类来管理,可以根据集群负载 实现最大并行化运行程序。
1.1.1.2.1.1 start方法
在sparkcontext初始化时,被调用。
注意看,这里用到了
spark.dynamicAllocation.minExecutors(默认为0),spark.dynamicAllocation.initialExecutors(默认等于minexecutor),spark.executor.instances(默认为0) 3个参数,取其中最大值作为初始化 分配的 executor数。
org.apache.spark.ExecutorAllocationManager#start
/**
* Register for scheduler callbacks to decide when to add and remove executors, and start
* the scheduling task.
*/
def start(): Unit = {
listenerBus.addToManagementQueue(listener)
listenerBus.addToManagementQueue(executorMonitor)
cleaner.foreach(_.attachListener(executorMonitor))
val scheduleTask = new Runnable() {
override def run(): Unit = {
try {
schedule()
} catch {
case ct: ControlThrowable =>
throw ct
case t: Throwable =>
logWarning(s"Uncaught exception in thread ${Thread.currentThread().getName}", t)
}
}
}
// 定时任务, 请求executor 或者 回收过期executor
// intervalMillis 默认100,单位ms
executor.scheduleWithFixedDelay(scheduleTask, 0, intervalMillis, TimeUnit.MILLISECONDS)
// 请求初始数量executor,numExecutorsTarget一开始被初始化这3个参数的最大值 max(spark.dynamicAllocation.minExecutors,spark.dynamicAllocation.initialExecutors,spark.executor.instances)
client.requestTotalExecutors(numExecutorsTarget, localityAwareTasks, hostToLocalTaskCount)
}
org.apache.spark.ExecutorAllocationManager#schedule
/**
* This is called at a fixed interval to regulate the number of pending executor requests
* and number of executors running.
*
* First, adjust our requested executors based on the add time and our current needs.
* Then, if the remove time for an existing executor has expired, kill the executor.
*
* This is factored out into its own method for testing.
*/
private def schedule(): Unit = synchronized {
val executorIdsToBeRemoved = executorMonitor.timedOutExecutors()
if (executorIdsToBeRemoved.nonEmpty) {
initializing = false
}
// 请求的当前实际所需executor
updateAndSyncNumExecutorsTarget(clock.nanoTime())
// 移除过期的executor
if (executorIdsToBeRemoved.nonEmpty) {
removeExecutors(executorIdsToBeRemoved)
}
}
总体调用示意图如下:
schedule是一个定时任务,每隔100ms运行一次

1.1.1.2.1.2 updateAndSyncNumExecutorsTarget方法
这里我们先看 updateAndSyncNumExecutorsTarget 和removeExecutors方法,因为其内部 最终也会调用 requestTotalExecutors
注意看,这里用到了一个新参数 spark.dynamicAllocation.sustainedSchedulerBacklogTimeout 默认为 spark.dynamicAllocation.schedulerBacklogTimeout 参数,默认为1s
org.apache.spark.ExecutorAllocationManager#updateAndSyncNumExecutorsTarget
private def updateAndSyncNumExecutorsTarget(now: Long): Int = synchronized {
// 我们需要的最大executor
val maxNeeded = maxNumExecutorsNeeded
if (initializing) {
// 当前仍在初始化
0
} else if (maxNeeded < numExecutorsTarget) {
// numExecutorsTarget表示已经分配的,超过了最大所需要maxNeeded,因此需要回收executor
val oldNumExecutorsTarget = numExecutorsTarget
// minNumExecutors对应spark.dynamicAllocation.minExecutors参数,默认为0
numExecutorsTarget = math.max(maxNeeded, minNumExecutors)
numExecutorsToAdd = 1
// 实际需要的executor数 小于 当前的executor数
if (numExecutorsTarget < oldNumExecutorsTarget) {
// 异步请求去释放空闲executor资源
client.requestTotalExecutors(numExecutorsTarget, localityAwareTasks, hostToLocalTaskCount)
logDebug(s"Lowering target number of executors to $numExecutorsTarget (previously " +
s"$oldNumExecutorsTarget) because not all requested executors are actually needed")
}
// 返回释放executor数量,负数表示移除executor
numExecutorsTarget - oldNumExecutorsTarget
} else if (addTime != NOT_SET && now >= addTime) {
// 如果 最大请求executor数超过了当前已分配的executor数,且超过了间隔时间 spark.dynamicAllocation.sustainedSchedulerBacklogTimeout 默认为 spark.dynamicAllocation.schedulerBacklogTimeout 参数,默认为1s
val delta = addExecutors(maxNeeded)
logDebug(s"Starting timer to add more executors (to " +
s"expire in $sustainedSchedulerBacklogTimeoutS seconds)")
addTime = now + TimeUnit.SECONDS.toNanos(sustainedSchedulerBacklogTimeoutS)
delta
} else {
0
}
}
org.apache.spark.ExecutorAllocationManager#maxNumExecutorsNeeded
注意看,这里又出现了1个新参数,spark.dynamicAllocation.executorAllocationRatio参数,默认1.0
private def maxNumExecutorsNeeded(): Int = {
// totalPendingTasks包括等待的任务+ 等待的推测执行任务
val numRunningOrPendingTasks= listener.totalPendingTasks + listener.totalRunningTasks
// executorAllocationRatio 即 spark.dynamicAllocation.executorAllocationRatio参数,默认1.0
// tasksPerExecutorForFullParallelism参数计算如下
// 向上取整结果
val maxNeeded = math.ceil(numRunningOrPendingTasks * executorAllocationRatio /
tasksPerExecutorForFullParallelism).toInt
if (tasksPerExecutorForFullParallelism > 1 && maxNeeded == 1 &&
listener.pendingSpeculativeTasks > 0) {
// 如果最大需要executor为1个,且推测执行还有等待任务,则多分配1个
maxNeeded + 1
} else {
maxNeeded
}
}
// EXECUTOR_CORES 对应 spark.executor.cores,表示每个executor的cpu数,默认为1
//CPUS_PER_TASK对应spark.task.cpus,表示每个task所消耗cpu数,默认为1;
private val tasksPerExecutorForFullParallelism =
conf.get(EXECUTOR_CORES) / conf.get(CPUS_PER_TASK)
// 向资源管理器请求一定数量的executor
// 如果请求的executor数量到达最大executor数,那就放弃请求,重置为0;否则翻倍去请求资源
private def addExecutors(maxNumExecutorsNeeded: Int): Int = {
// maxNumExecutors 对应 spark.dynamicAllocation.maxExecutors
if (numExecutorsTarget >= maxNumExecutors) {
logDebug(s"Not adding executors because our current target total " +
s"is already $numExecutorsTarget (limit $maxNumExecutors)")
numExecutorsToAdd = 1
return 0
}
val oldNumExecutorsTarget = numExecutorsTarget
// There's no point in wasting time ramping up to the number of executors we already have, so
// make sure our target is at least as much as our current allocation:
numExecutorsTarget = math.max(numExecutorsTarget, executorMonitor.executorCount)
// Boost our target with the number to add for this round:
numExecutorsTarget += numExecutorsToAdd
// Ensure that our target doesn't exceed what we need at the present moment:
numExecutorsTarget = math.min(numExecutorsTarget, maxNumExecutorsNeeded)
// Ensure that our target fits within configured bounds:
numExecutorsTarget = math.max(math.min(numExecutorsTarget, maxNumExecutors), minNumExecutors)
// 重新计算得出当前要请求的executor数
val delta = numExecutorsTarget - oldNumExecutorsTarget
// If our target has not changed, do not send a message
// to the cluster manager and reset our exponential growth
if (delta == 0) {
numExecutorsToAdd = 1
return 0
}
val addRequestAcknowledged = try {
testing ||
// 和回收executor资源一样,请求executor资源 也是这个api
client.requestTotalExecutors(numExecutorsTarget, localityAwareTasks, hostToLocalTaskCount)
} catch {
case NonFatal(e) =>
// Use INFO level so the error it doesn't show up by default in shells. Errors here are more
// commonly caused by YARN AM restarts, which is a recoverable issue, and generate a lot of
// noisy output.
logInfo("Error reaching cluster manager.", e)
false
}
if (addRequestAcknowledged) {
val executorsString = "executor" + { if (delta > 1) "s" else "" }
logInfo(s"Requesting $delta new $executorsString because tasks are backlogged" +
s" (new desired total will be $numExecutorsTarget)")
numExecutorsToAdd = if (delta == numExecutorsToAdd) {
numExecutorsToAdd * 2
} else {
1
}
delta
} else {
logWarning(
s"Unable to reach the cluster manager to request $numExecutorsTarget total executors!")
numExecutorsTarget = oldNumExecutorsTarget
0
}
}
计算当前最大需要的executor:
pendingTasks方法 + pendingSpeculativeTasks方法 + totalRunningTasks方法
变量stageAttemptToNumTasks–》pendingTasks (基于stageAttemptToTaskIndices(表示已分配)相减,得出剩余待运行任务)
变量stageAttemptToNumRunningTask(已运行任务:包括推测任务)–》totalRunningTasks
变量stageAttemptToNumSpeculativeTasks(推测任务:包括等待和已运行的)–》pendingSpeculativeTasks (基于stageAttemptToSpeculativeTaskIndices(表示已运行的推测任务),相减得出剩余待运行的推测任务)
updateAndSyncNumExecutorsTarget 逻辑流程示意图如下:
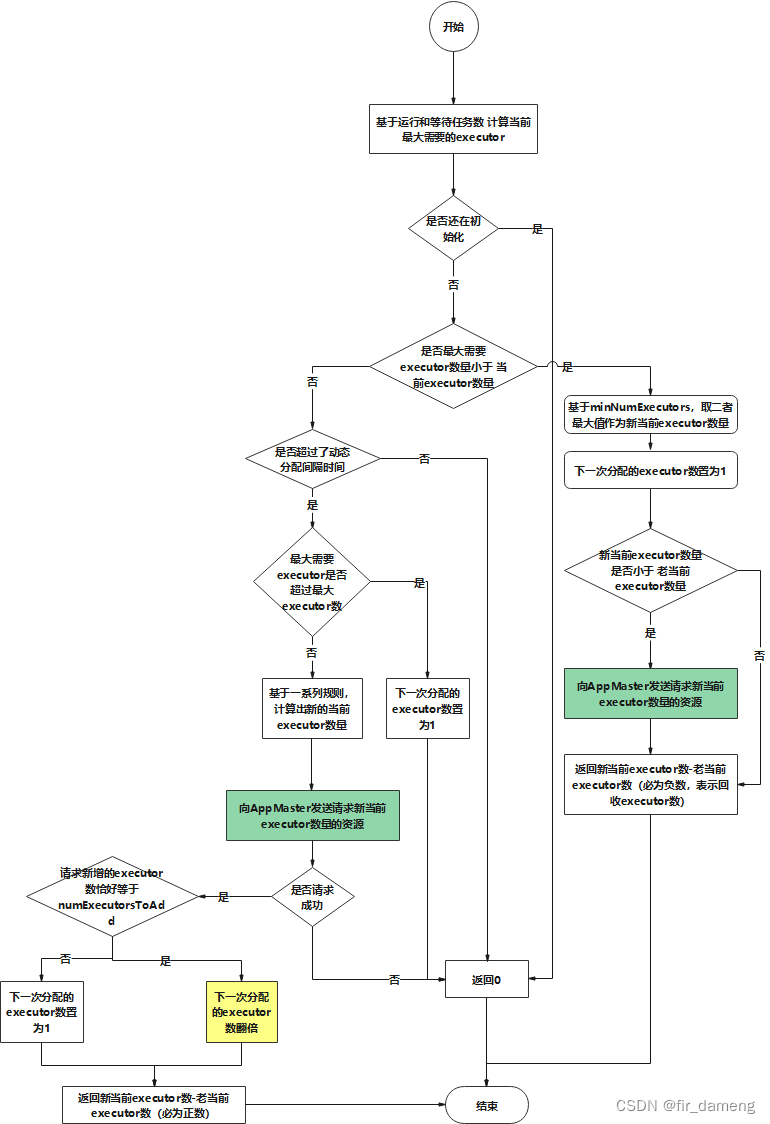
todo: 为什么 新增的executor 等于 numExecutorsToAdd,下次分配的executor即 numExecutorsToAdd 翻倍?
1.1.1.2.1.3 requestTotalExecutors接口方法
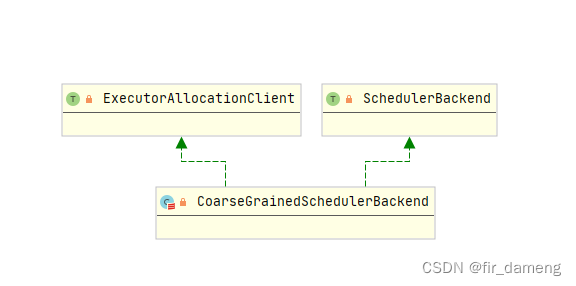
CoarseGrainedSchedulerBackend 实现了ExecutorAllocationClient接口的requestTotalExecutors方法。
经过断点调试,追踪 yarn client 模式下,requestTotalExecutors方法调用路径如下:
org.apache.spark.ExecutorAllocationClient#requestTotalExecutors
org.apache.spark.scheduler.cluster.CoarseGrainedSchedulerBackend#requestTotalExecutors
org.apache.spark.scheduler.cluster.CoarseGrainedSchedulerBackend#doRequestTotalExecutors
org.apache.spark.scheduler.cluster.YarnSchedulerBackend#doRequestTotalExecutors
org.apache.spark.scheduler.cluster.YarnSchedulerBackend#prepareRequestExecutors
private[cluster] def prepareRequestExecutors(requestedTotal: Int): RequestExecutors = {
val nodeBlacklist: Set[String] = scheduler.nodeBlacklist()
// For locality preferences, ignore preferences for nodes that are blacklisted
val filteredHostToLocalTaskCount =
hostToLocalTaskCount.filter { case (k, v) => !nodeBlacklist.contains(k) }
// driver端 发送 RequestExecutors 消息
RequestExecutors(requestedTotal, localityAwareTasks, filteredHostToLocalTaskCount,
nodeBlacklist)
}
org.apache.spark.scheduler.cluster.CoarseGrainedClusterMessages.RequestExecutors
// Request executors by specifying the new total number of executors desired
// This includes executors already pending or running
case class RequestExecutors(
requestedTotal: Int,
localityAwareTasks: Int,
hostToLocalTaskCount: Map[String, Int],
nodeBlacklist: Set[String])
extends CoarseGrainedClusterMessage
todo: 动态资源分配和 普通分配(静态分配)的区别在哪??
动态分配可以基于当前集群负载最大化并行运行任务,避免静态分配资源分配不合理,造成资源浪费。
1.1.1.2.2 ApplicationMaster
1.1.1.2.2.1 ApplicationMaster端接收到消息并更新 targetNumExecutors
org.apache.spark.deploy.yarn.ApplicationMaster.AMEndpoint#receiveAndReply
override def receiveAndReply(context: RpcCallContext): PartialFunction[Any, Unit] = {
case r: RequestExecutors =>
Option(allocator) match {
case Some(a) =>
// allocator为YarnAllocator,用于向resourcemanager请求资源,
if (a.requestTotalExecutorsWithPreferredLocalities(r.requestedTotal,
r.localityAwareTasks, r.hostToLocalTaskCount, r.nodeBlacklist)) {
resetAllocatorInterval()
}
context.reply(true)
case None =>
logWarning("Container allocator is not ready to request executors yet.")
context.reply(false)
}
org.apache.spark.deploy.yarn.YarnAllocator#requestTotalExecutorsWithPreferredLocalities
def requestTotalExecutorsWithPreferredLocalities(
requestedTotal: Int,
localityAwareTasks: Int,
hostToLocalTaskCount: Map[String, Int],
nodeBlacklist: Set[String]): Boolean = synchronized {
this.numLocalityAwareTasks = localityAwareTasks
this.hostToLocalTaskCounts = hostToLocalTaskCount
if (requestedTotal != targetNumExecutors) {
logInfo(s"Driver requested a total number of $requestedTotal executor(s).")
// 更新 要请求的executor数,这个非常关键,为什么这里没有同步请求resourmanager分配资源?且看后面解释
targetNumExecutors = requestedTotal
allocatorBlacklistTracker.setSchedulerBlacklistedNodes(nodeBlacklist)
true
} else {
false
}
}
1.1.1.2.2.1 守护线程向resourceManger请求资源
在appmaster创建时,同时也创建1个YarnAllocator,用于向resourcemanager请求资源等操作。
调用链如下:
org.apache.spark.deploy.yarn.ApplicationMaster#runUnmanaged
org.apache.spark.deploy.yarn.ApplicationMaster#createAllocator
createAllocator 逻辑序列图如下:
主要点在于结尾给appmaster 创建并启动1个后台上报线程,用于间隔一定时间,向resourcemanager请求资源
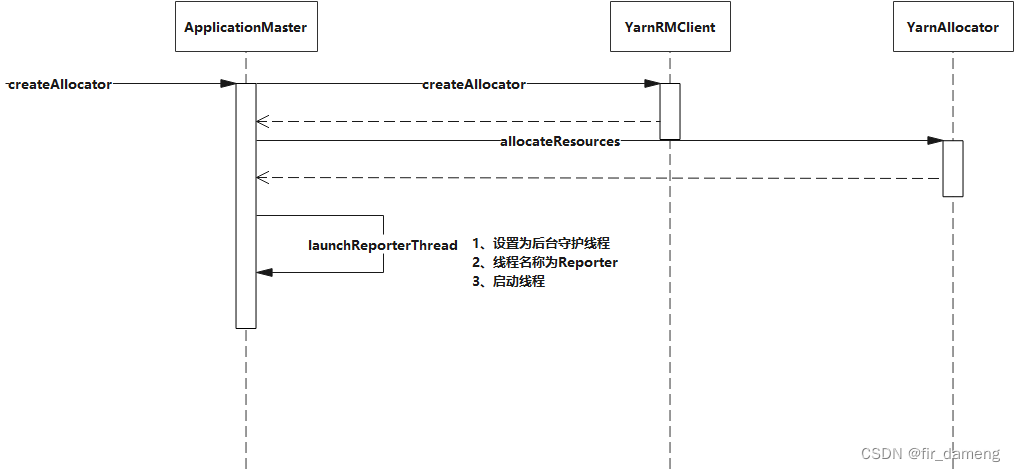
launchReporterThread方法调用如下
org.apache.spark.deploy.yarn.ApplicationMaster#launchReporterThread
org.apache.spark.deploy.yarn.ApplicationMaster#allocationThreadImpl
org.apache.spark.deploy.yarn.YarnAllocator#allocateResources
org.apache.spark.deploy.yarn.YarnAllocator#updateResourceRequests
org.apache.spark.deploy.yarn.YarnAllocator#handleAllocatedContainers
org.apache.spark.deploy.yarn.YarnAllocator#runAllocatedContainers
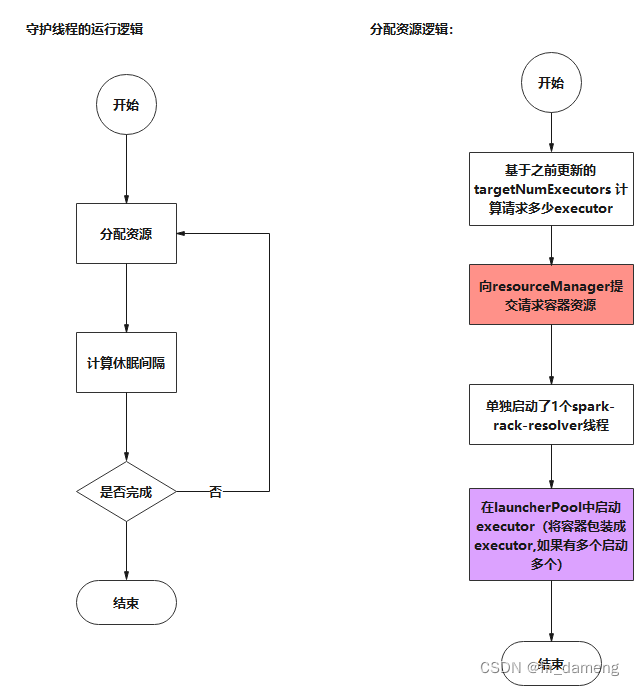
1.1.1.3 示例案例
环境:yanr-client运行模式下,开启了动态资源分配
流程示意图如下:
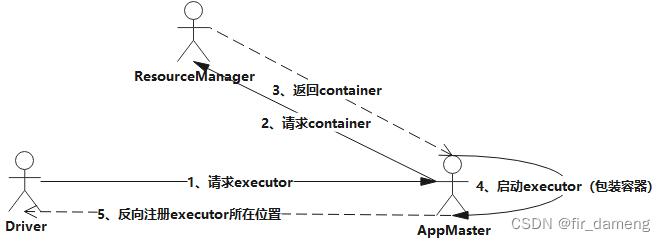
部分日志摘要如下:
------driver端日志-----------
22/12/03 22:58:30 INFO ExecutorAllocationManager: Requesting 1 new executor because tasks are backlogged (new desired total will be 1)
------appMaster端日志-----------
22/12/03 09:58:31 INFO YarnAllocator: Driver requested a total number of 1 executor(s).
22/12/03 09:58:31 INFO YarnAllocator: Will request 1 executor container(s), each with 1 core(s) and 896 MB memory (including 384 MB of overhead)
22/12/03 09:58:31 INFO YarnAllocator: Submitted container request for host hadoop3,hadoop2,hadoop1.
22/12/03 09:58:32 INFO AMRMClientImpl: Received new token for : hadoop2:33222
22/12/03 09:58:32 INFO YarnAllocator: Launching container container_1670078106874_0004_01_000002 on host hadoop2 for executor with ID 1
22/12/03 09:58:32 INFO YarnAllocator: Received 1 containers from YARN, launching executors on 1 of them.
22/12/03 09:58:32 INFO ContainerManagementProtocolProxy: yarn.client.max-cached-nodemanagers-proxies : 0
22/12/03 09:58:32 INFO ContainerManagementProtocolProxy: Opening proxy : hadoop2:33222
------resourceManager端日志-----------
2022-12-03 09:58:32,581 INFO org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.allocator.AbstractContainerAllocator: assignedContainer application attempt=appattempt_1670078106874_0004_000001 container=null queue=org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.allocator.RegularContainerAllocator@24ca8dd clusterResource=<memory:24576, vCores:24> type=NODE_LOCAL requestedPartition=
2022-12-03 09:58:32,581 INFO org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.ParentQueue: assignedContainer queue=root usedCapacity=0.041666668 absoluteUsedCapacity=0.041666668 used=<memory:1024, vCores:1> cluster=<memory:24576, vCores:24>
2022-12-03 09:58:32,582 INFO org.apache.hadoop.yarn.server.resourcemanager.rmcontainer.RMContainerImpl: container_1670078106874_0004_01_000002 Container Transitioned from NEW to ALLOCATED
2022-12-03 09:58:32,582 INFO org.apache.hadoop.yarn.server.resourcemanager.RMAuditLogger: USER=root OPERATION=AM Allocated Container TARGET=SchedulerApp RESULT=SUCCESS APPID=application_1670078106874_0004 CONTAINERID=container_1670078106874_0004_01_000002 RESOURCE=<memory:1024, vCores:1>
2022-12-03 09:58:32,582 INFO org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.ParentQueue: assignedContainer queue=root usedCapacity=0.083333336 absoluteUsedCapacity=0.083333336 used=<memory:2048, vCores:2> cluster=<memory:24576, vCores:24>
2022-12-03 09:58:32,582 INFO org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler: Allocation proposal accepted
2022-12-03 09:58:32,810 INFO org.apache.hadoop.yarn.server.resourcemanager.security.NMTokenSecretManagerInRM: Sending NMToken for nodeId : hadoop2:33222 for container : container_1670078106874_0004_01_000002
2022-12-03 09:58:32,811 INFO org.apache.hadoop.yarn.server.resourcemanager.rmcontainer.RMContainerImpl: container_1670078106874_0004_01_000002 Container Transitioned from ALLOCATED to ACQUIRED
2022-12-03 09:58:33,583 INFO org.apache.hadoop.yarn.server.resourcemanager.rmcontainer.RMContainerImpl: container_1670078106874_0004_01_000002 Container Transitioned from ACQUIRED to RUNNING
------driver端日志-----------
22/12/03 22:58:35 INFO YarnSchedulerBackend$YarnDriverEndpoint: Registered executor NettyRpcEndpointRef(spark-client://Executor) (192.168.150.22:56294) with ID 1
22/12/03 22:58:35 INFO ExecutorMonitor: New executor 1 has registered (new total is 1)
22/12/03 22:58:36 INFO BlockManagerMasterEndpoint: Registering block manager hadoop2:43194 with 93.3 MiB RAM, BlockManagerId(1, hadoop2, 43194, None)
22/12/03 22:58:36 INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, hadoop2, executor 1, partition 0, NODE_LOCAL, 7557 bytes)
1.1.1.4 参考
https://blog.csdn.net/lovetechlovelife/article/details/112723766














 897
897











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









