







#0 提供详细的命令行和记录结果。
Parsec
mesi 两层协议
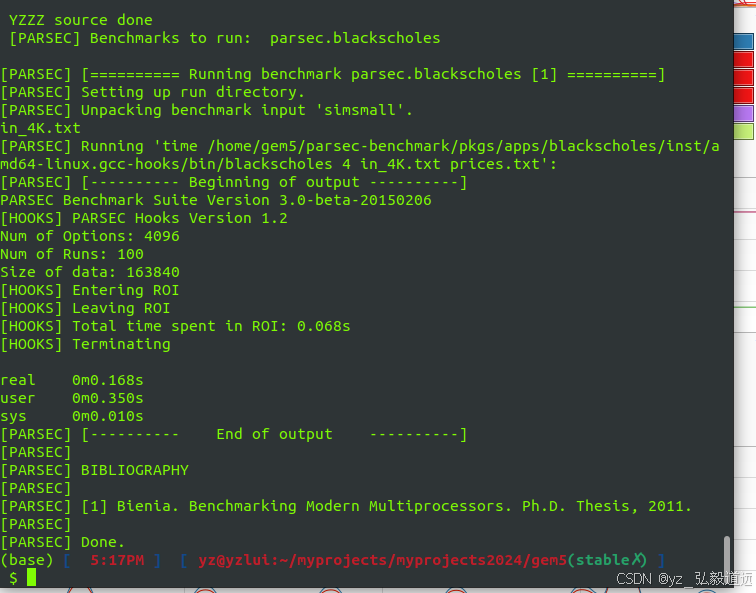
首先是编译运行: 一开始不知道ruby的check point 需要moeshi hammer,用的默认的x86. 下图可以看到默认的是mesihammer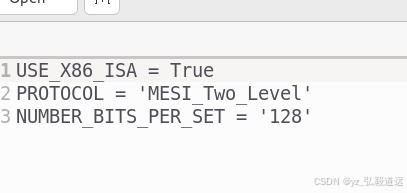
无checkpoint运行结果。
这里包括了系统启动的部分,本来可以跳过的。但是作为起步阶段,跑通大于省时间,跑一晚睡醒也能看到结果了。
#先是要编译 对应的gem5.opt
sudo docker run --volume /home/yz/myprojects/2024GEM5/parsec-tests/yzmodifiedgem5/:/gem5 --rm -it gcr.io/gem5-test/ubuntu-22.04_all-dependencies:v22-1
scons build/X86/gem5.opt -j 16 #注意这个是默认的mesi
# 如果你想我一样,build_opts 内写了新的文件,例如 X86_MOESI_hammeryz1wVCBuffer
scons build/X86_MOESI_hammeryz1wVCBuffer/gem5.opt -j 16
blacksholes + timing simple: buffer 1w & buffer 4
然后是运行这个硬件架构对应的 gem5.opt。 下面是blacksholes
./build/X861wVCBufferDepth/gem5.opt -d m5out/20241001/buffer1w/Blackholes configs/deprecated/example/fs.py --kernel=/home/yz/.cache/gem5/x86-linux-kernel-4.19.83 --disk=/home/yz/.cache/gem5/x86-parsec --cpu-type=TimingSimpleCPU --num-cpus=64 --ruby --network=garnet --topology=Mesh_XY --mesh-rows=8 --num-dirs=64 --num-l2caches=64 --script=configs/yz2023Nov/yzfs_parsecBlackholes.script
如果是buffer 10000:
花了14小时,26g内存。

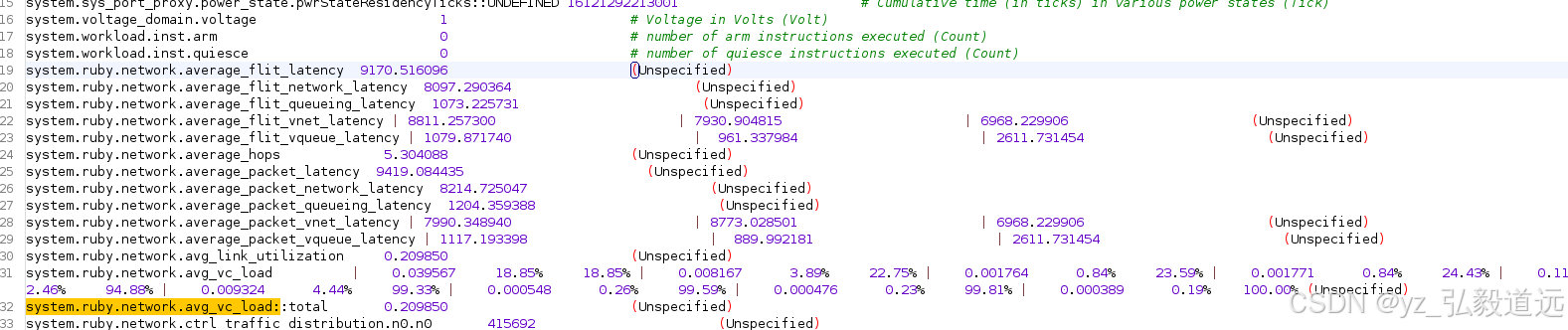
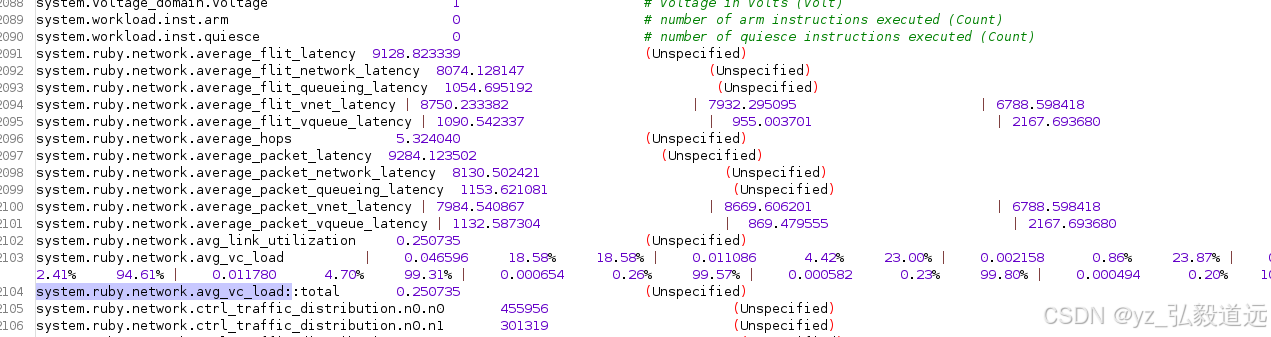
ruby的一些统计数据如下
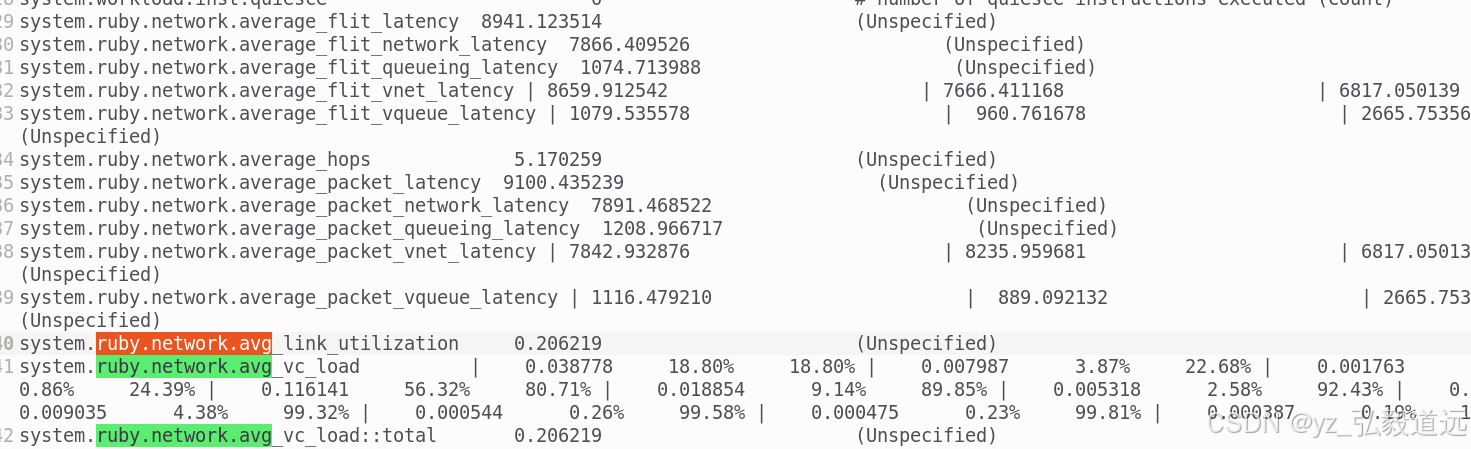
roi只有0.068s,但是我们统计的是15s。我们需要后续看一下这个image里的parsec binary。 应该是没有加m5 op的操作,比如dumpsstats和m5exit之类的,导致统计的是整体的。
如果是buffer4 这里我跑在一个服务器上,cpu比较老频率也只有3.3g,用了20多个小时:

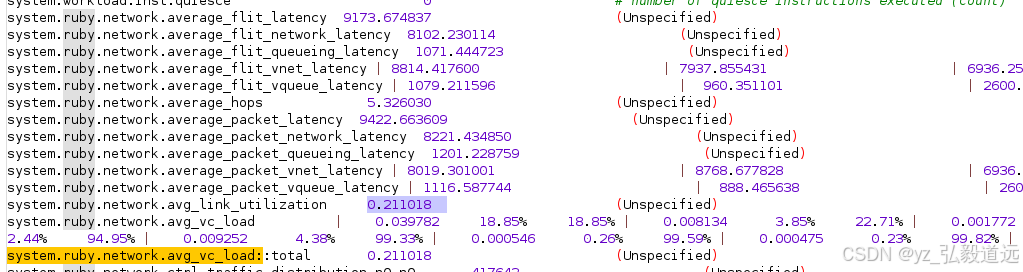
buffer4的情况,总的roi时间是一样的, real 和user的时间不同。
插曲: buffer4 默认配置在两个电脑上的验证:
mesi blacksholes没有checkpoint,我的intel 10700kpc上:
mesi blacksholes没有checkpoint,我的服务器上:

mesi blacksholes没有checkpoint,我的intel 10700kpc上:
mesi blacksholes没有checkpoint,我的服务器上:
两个是一摸一样的,一方面证明我在两个上用的版本是一样,一方面证明没有随机性。
bodytrack + timing simple: buffer 1w & buffer 4
./build/X861wVCBufferDepth/gem5.opt -d m5out/20241001/buffer1w/Bodytrack configs/deprecated/example/fs.py --kernel=/home/yz/.cache/gem5/x86-linux-kernel-4.19.83 --disk=/home/yz/.cache/gem5/x86-parsec --cpu-type=TimingSimpleCPU --num-cpus=64 --ruby --network=garnet --topology=Mesh_XY --mesh-rows=8 --num-dirs=64 --num-l2caches=64 --script=configs/yz2023Nov/yzfs_parsecBodytrack.script
buffer10k在我常用pc上内存不足没跑完
buffer4 的server:

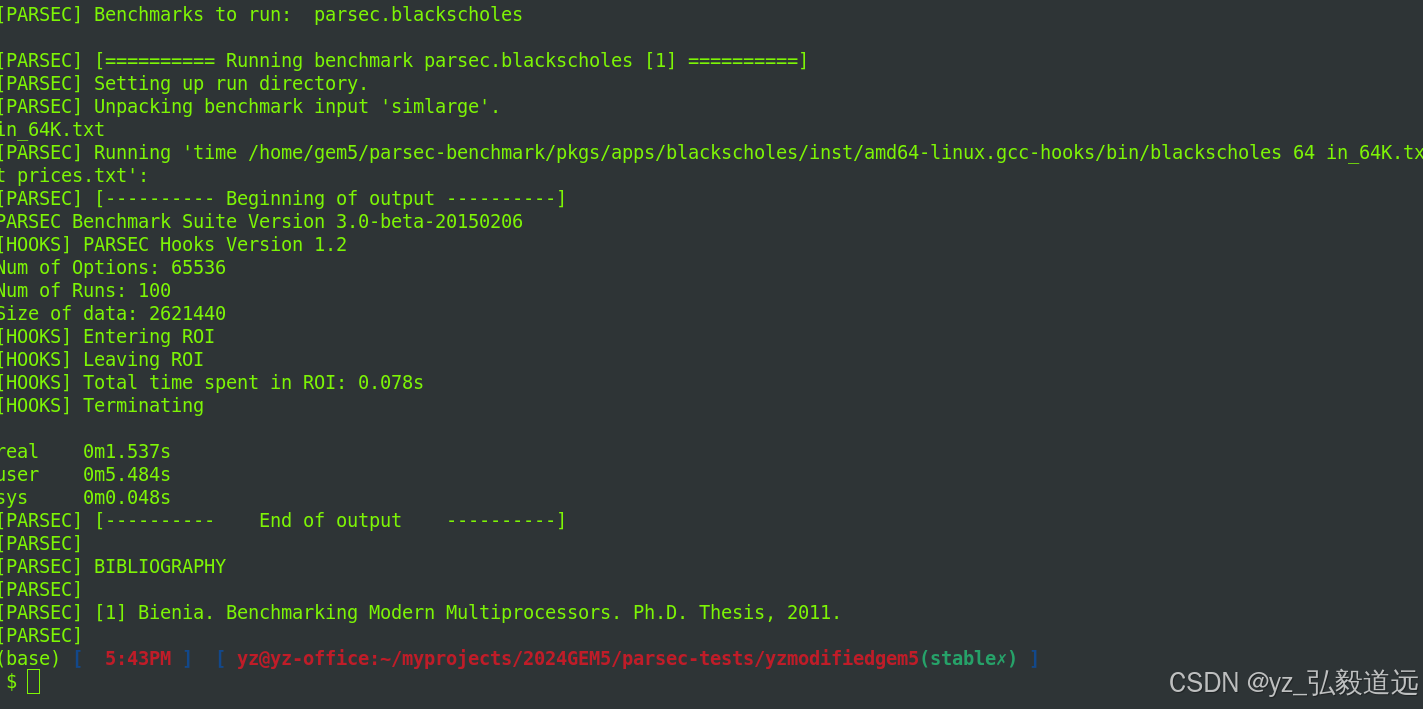
canneal + timing simple: buffer 1w & buffer 4
buffer10k在我常用pc上内存不足没跑完
buffer4 的server:

parsec moesi hammer
为了提速,我们用checkpoint . 然后我们需要用moesi hammer给ruby做check point。
创建check point
./build/X861wVCBufferDepth/gem5.opt -d m5out/20241003VCBuffer1whammerCHKPTAtomic configs/deprecated/example/fs.py --kernel=/home/yz/.cache/gem5/x86-linux-kernel-4.19.83 --disk=/home/yz/.cache/gem5/x86-parsec --cpu-type=X86AtomicSimpleCPU --num-cpus=64 --ruby --network=garnet --topology=Mesh_XY --mesh-rows=8 --num-dirs=64 --num-l2caches=64 --script=configs/boot/yzhack_back_ckpt.rcS
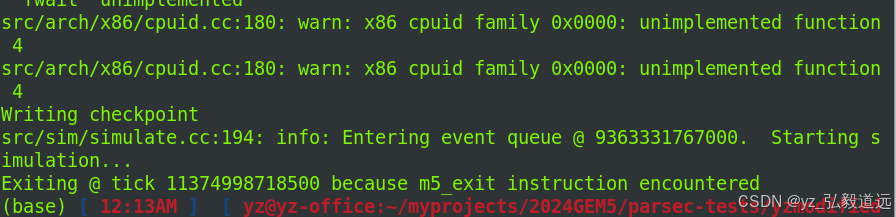
可以看到在9363331767000 ticks创建了checkpoint
文件夹子u也对应的上。

buffer 1w blacksholes moeshi hammer
然后我们用moesi hammer,生成默认的VC buffer depth 4, 然后改成buffer1,buffer10000一共三个gem5.opt,对应模拟的三种硬件架构。
buffer 1w blacksholes moeshi hammer
无checkpoint
我们先直接运行 parsecblacksholes,不考虑check point
./build/X86_MOESI_hammeryz1wVCBuffer/gem5.opt -d m5out/X86_MOESI_hammeryz1wVCBuffer_noCHKPT/blacksholes configs/deprecated/example/fs.py --kernel=/home/yz/.cache/gem5/x86-linux-kernel-4.19.83 --disk=/home/yz/.cache/gem5/x86-parsec --cpu-type=TimingSimpleCPU --num-cpus=64 --ruby --network=garnet --topology=Mesh_XY --mesh-rows=8 --num-dirs=64 --num-l2caches=64 --script=configs/yz2023Nov/large/yzfs_largeparsecblacksholes.script
/yzfs_largeparsecblacksholes.script 内容如下:
cd /home/gem5/parsec-benchmark; source env.sh; parsecmgmt -a run -p blackscholes -c gcc-hooks -i simlarge -n 64; sleep 1; m5 exit;
生产checkpoint 并用上
在另一边完整运行的时候,我们也创建checkpoint并存储,以供下一步加速
./build/X86_MOESI_hammeryz1wVCBuffer/gem5.opt -d m5out/20241030X86_MOESI_hammeryz1wVCBufferTimisimpleSaveCHKPT/ configs/deprecated/example/fs.py --kernel=/home/yz/.cache/gem5/x86-linux-kernel-4.19.83 --disk=/home/yz/.cache/gem5/x86-parsec --cpu-type=TimingSimpleCPU --num-cpus=64 --ruby --network=garnet --topology=Mesh_XY --mesh-rows=8 --num-dirs=64 --num-l2caches=64 --script=configs/boot/yzhack_back_ckpt.rcS
还在运行,运行后我们接着这个checkpoint运行
buffer 4 blacksholes moeshi hammer
buffer 1blacksholes moeshi hammer
报错部分:./build/X86_MOESI_hammeryz1wVCBuffer/gem5.opt -d m5out/20241030X86_MOESI_hammeryz1wVCBufferTimisimpleSaveCHKPT/ configs/deprecated/example/fs.py --kernel=/home/yz/.cache/gem5/x86-linux-kernel-4.19.83 --disk=/home/yz/.cache/gem5/x86-parsec --cpu-type=TimingSimpleCPU --num-cpus=64 --ruby --network=garnet --topology=Mesh_XY --mesh-rows=8 --num-dirs=64 --num-l2caches=64 --script=configs/boot/yzhack_back_ckpt.rcS

eventq->empty()

但是这个设置可以跑通blacksholes。 我准备试试atomic而不是这里的timingsimple 。
./build/X86_MOESI_hammeryz1wVCBuffer/gem5.opt -d m5out/20241030X86_MOESI_hammeryz1wVCBuffer_X86AtomicSimpleCPUCHKPT/ configs/deprecated/example/fs.py --kernel=/home/yz/.cache/gem5/x86-linux-kernel-4.19.83 --disk=/home/yz/.cache/gem5/x86-parsec --cpu-type=X86AtomicSimpleCPU --num-cpus=64 --ruby --network=garnet --topology=Mesh_XY --mesh-rows=8 --num-dirs=64 --num-l2caches=64 --script=configs/boot/yzhack_back_ckpt.rcS
vc channer
同时我们改变vc channel ,从默认的4到1 到10k,三个配置。
结果
./build/X86_MOESI_hammeryz1wVCBuffer/gem5.opt -d m5out/X86_MOESI_hammeryz1wVCBuffer_noCHKPT/blacksholes configs/deprecated/example/fs.py --kernel=/home/yz/.cache/gem5/x86-linux-kernel-4.19.83 --disk=/home/yz/.cache/gem5/x86-parsec --cpu-type=TimingSimpleCPU --num-cpus=64 --ruby --network=garnet --topology=Mesh_XY --mesh-rows=8 --num-dirs=64 --num-l2caches=64 --script= configs/yz2023Nov/large/yzfs_largeparsecblacksholes.script
Caneeal 结果
canneal是memory bound
vc channel 4, buffer depth 10k
首先这个直接运行会有deadlock
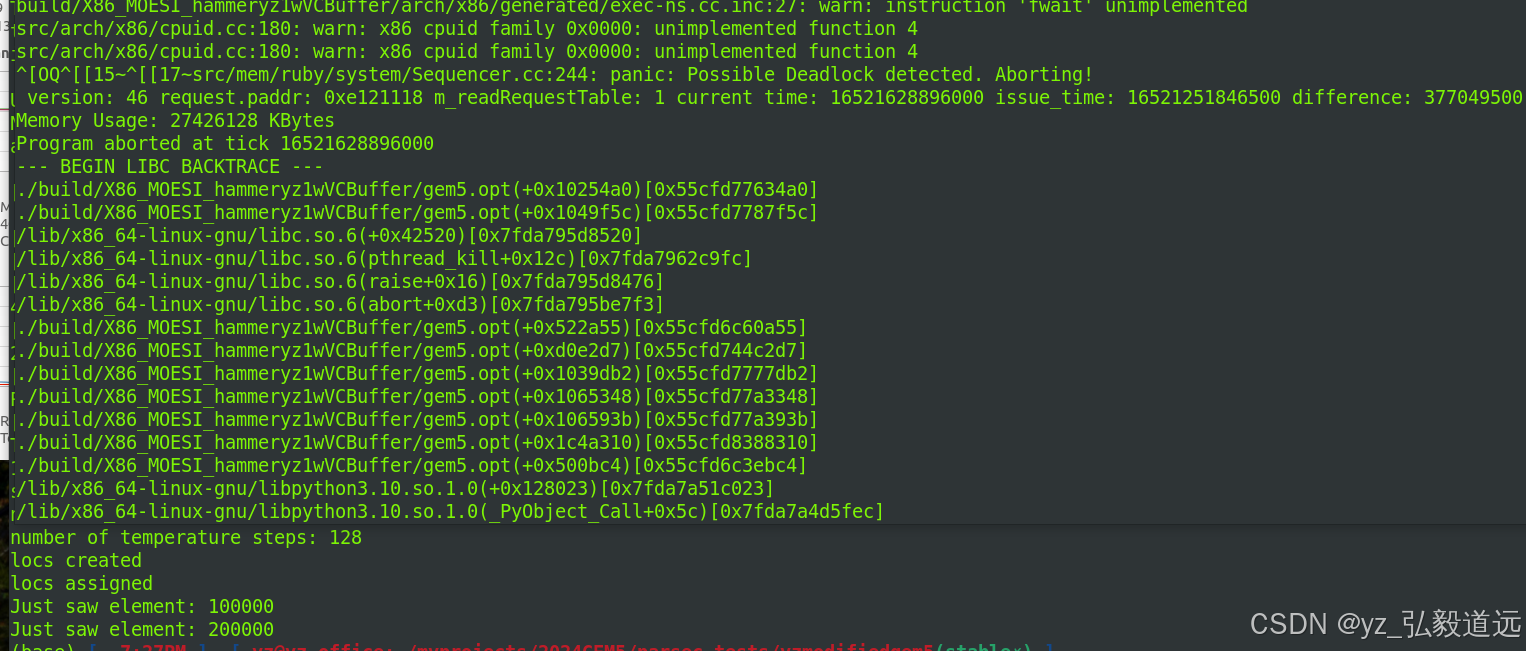
翻看命令行:
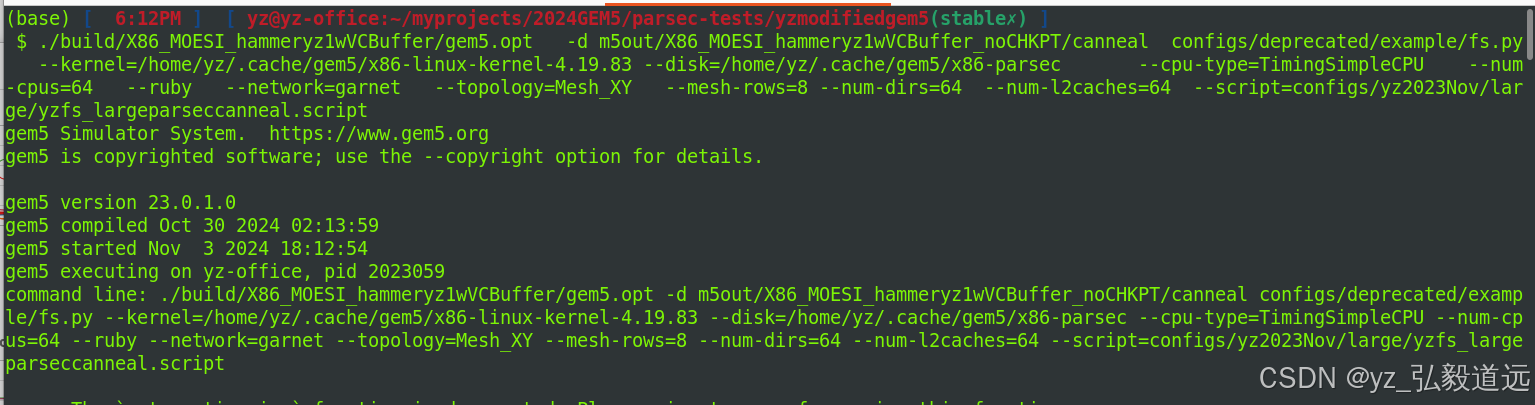
再看util m5term 。 200,000 elements就突然结束了。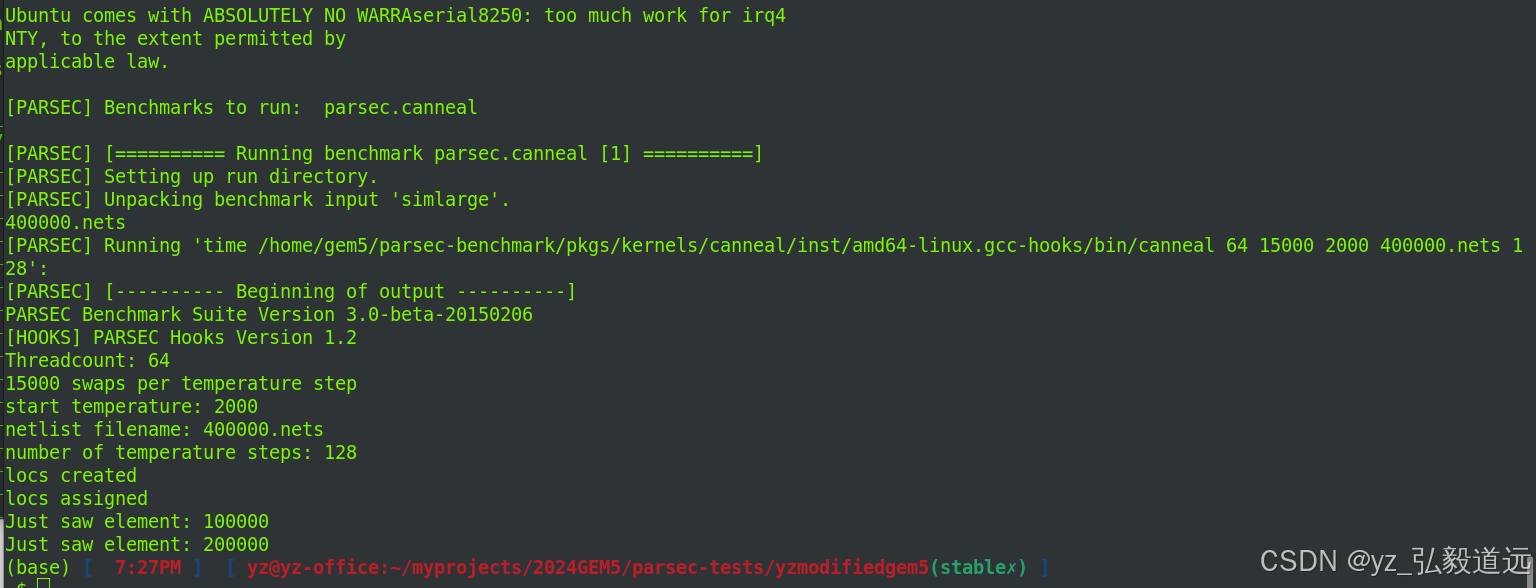
同时 ./util/term/m5term 3458 在6.23pm也结束了一个:
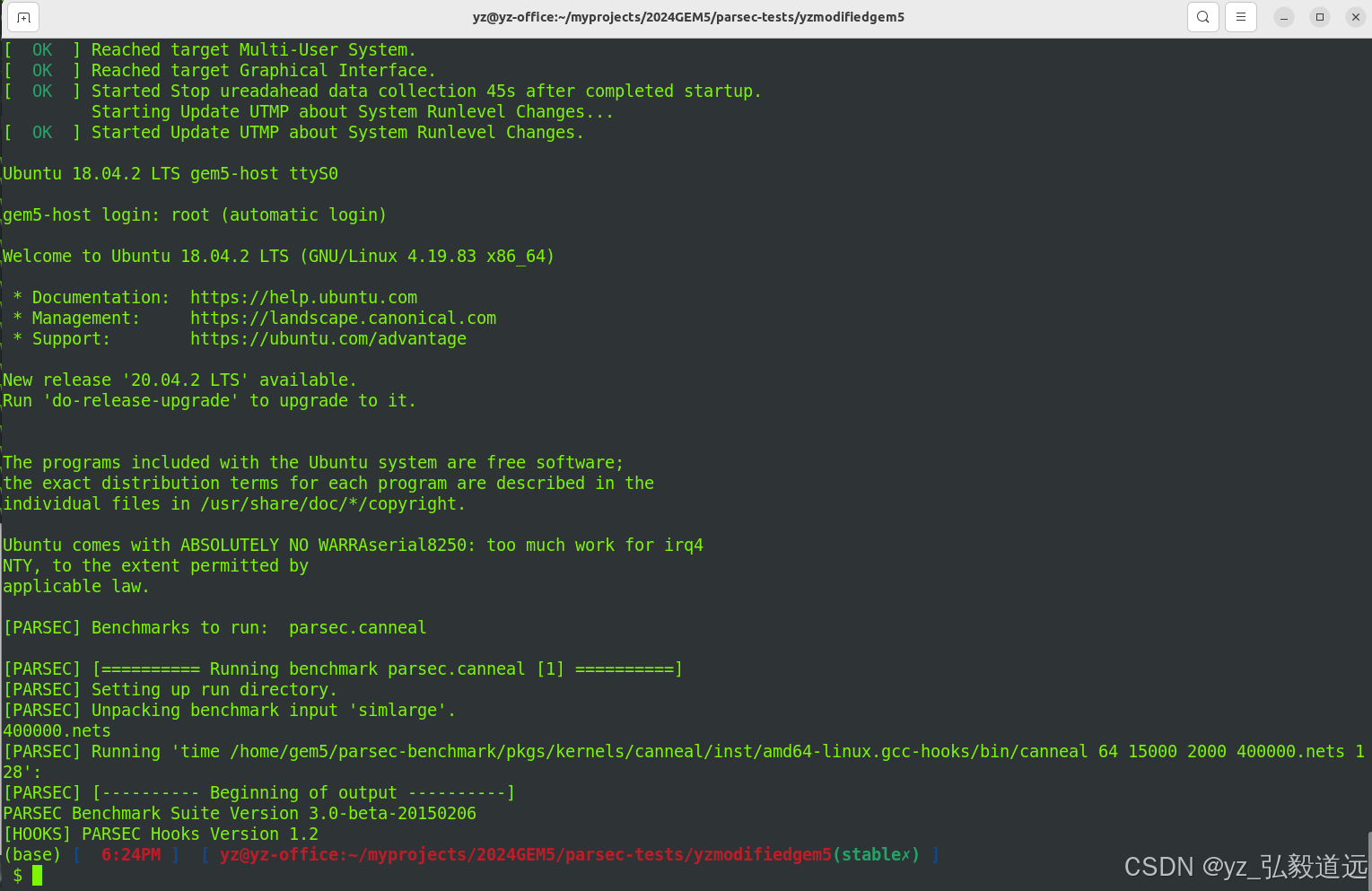
小结,在办公室电脑上有两个caneal中止了。caneal文件夹内的stat.txt 没有运行。此外,bodytrack成功,vips在运行。
7号的下一步:
等其他设置的结果。 以及试试checkpoint。
bodytrack 结果
VC 4 + buffer depth 4 default
VC 4 + buffer depth 10k
办公室电脑上的结果。 这个bash特别离谱,调整窗口大小会吞最后的打印结果。
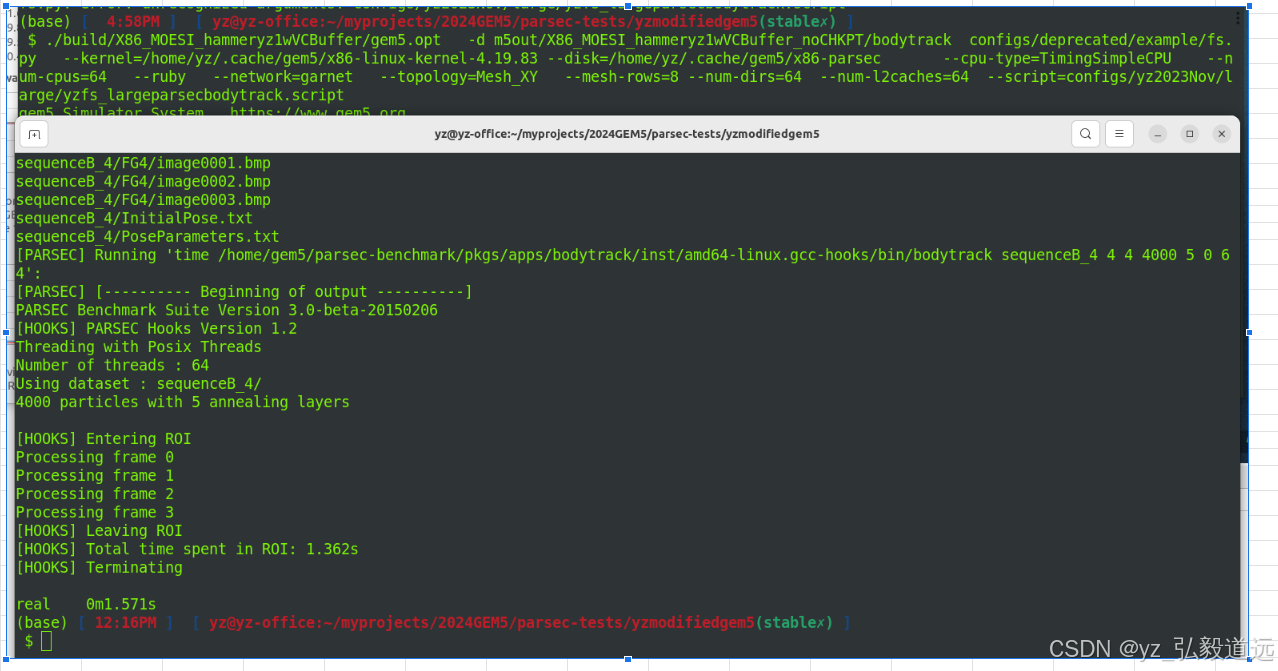
VC 1 + buffer depth 4 服务器上的结果
roi 1.367s
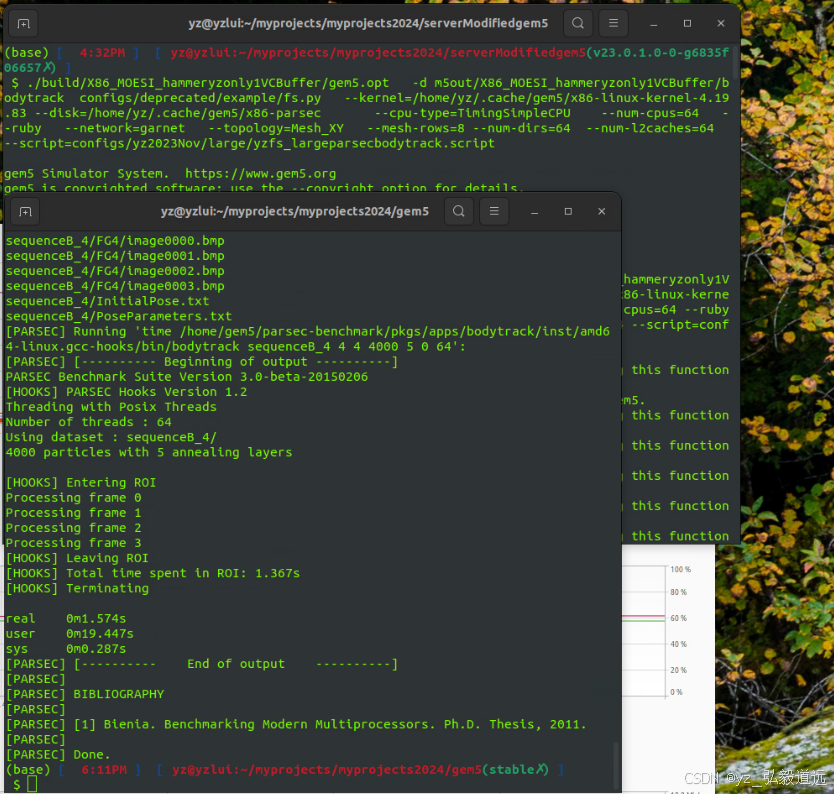

















 2119
2119

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









