






Windows10安装Hadoop3.1.3环境
1.安装包下载
1.1.hadoop官网下载
https://hadoop.apache.org/release/3.1.3.html
1.2下载winutils
winutils是hadoop在windows上运行的兼容工具,可以去GitHub上下载对应的hadoop对应的版本即可,由于之前在windows10上安装hadoop2.x的的好几个版本,均安装失败,错误是下面这个:
java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows.
直接是无解,那就只能去网上查下试下其它的hadoop版本了,这个hadoop3.1.3的版本亲测可行。
1.3安装文件
链接:https://pan.baidu.com/s/109956kgaarkHoklcARVYgQ
提取码:udy1
2.配置安装
2.1安装配置JDK环境
略,需要安装JDK>=1.8, jdk64位,不要安装在C盘的默认路径下:C:\Program Files\Java下,否则修改hadoop的修改hadoop-env.cmd文件中的JAVA_HOME路径会不生效,jdk的路径中不要用特殊字符、中文或者是空格,否则配置会无效,如果你的jdk环境默认安装在C:\Program Files\Java下可以将其复制一份到非C盘的盘中,然后去除路径中的空格、中文和特殊字符等符号,然后重新配置下jdk的环境变量即可,我的是之前安装在C:\Program Files\Java下,然后复制到D盘下重新配置jdk环境变量就生效了。
2.2解压hadoop压缩包
把下载的hadoop-3.1.3.tar.gz压缩包解压到自己要安装的路径下
我的解压安装路径是在D:\hadoop-3.1.3
2.3配置hadoop的环境变量
2.3.1配置HADOOP_HOME
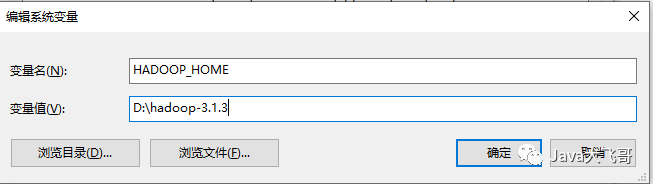
2.3.2配置Path变量
在Path变量中添加hadoop的bin路径:%HADOOP_HOME%\bin;
2.4配置hadoop
2.4.1 创建data和temp文件夹
进入hadoop的安装目录D:\hadoop-3.1.3下新建data和temp文件夹
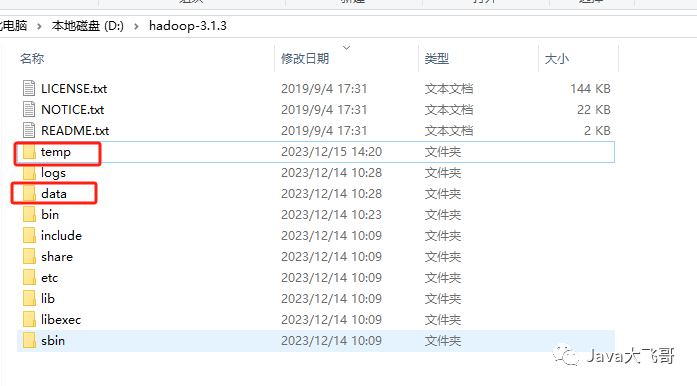
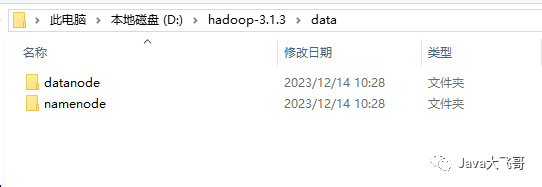
进入data目录,创建datanode和namenode文件夹
2.4.2配置hadoop的文件
进入D:\hadoop-3.1.3\etc\hadoop
2.4.2.1 修改hadoop-env.cmd文件中的JAVA_HOME路径
原来的配置PROGRA~1是 C:\Program Files 目录的dos文件名模式下的缩写
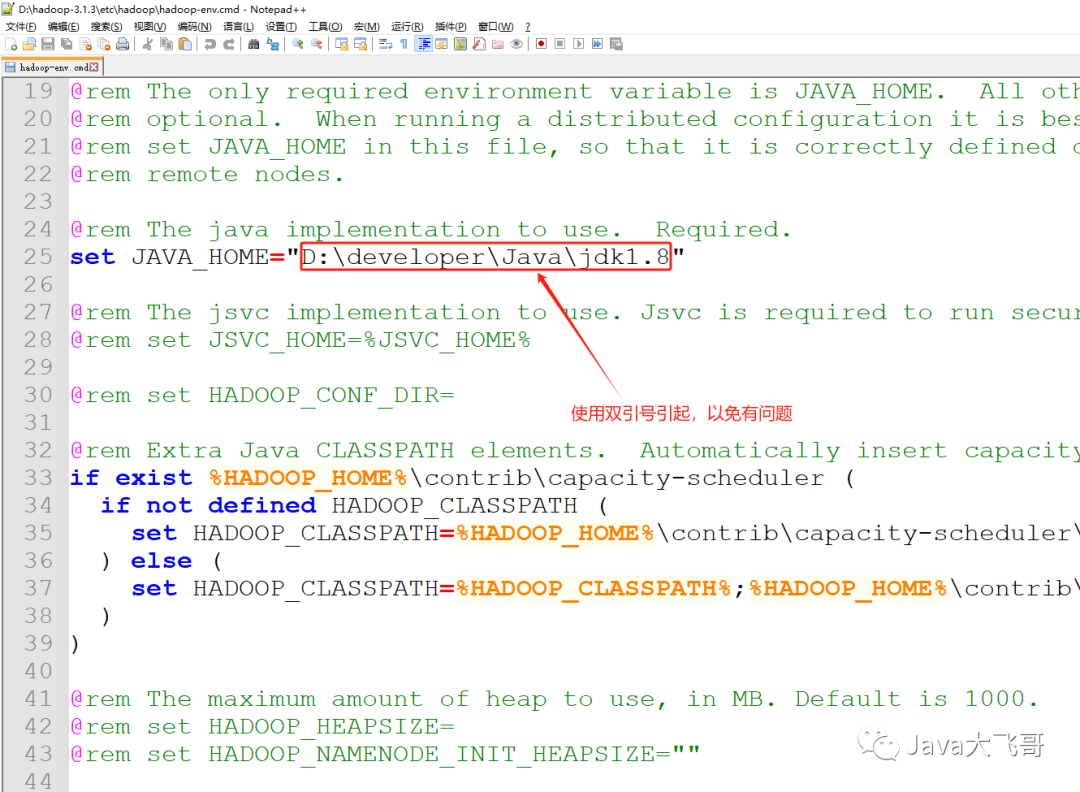
这个是配置的是本地JDK的安装路径,改成自己的JDK的安装路径即可。
2.4.2.2配置文件core-site.xml
添加如下内容:在configuration标签中添加如下的property标签属性内容
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
2.4.2.3配置hdfs-site.xml
添加如下内容:把namenode和datanode的路径改成自己的路径即可
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/D:/hadoop-3.1.3/data/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/D:/hadoop-3.1.3/data/datanode</value>
</property>
</configuration>
2.4.2.4配置mapred-site.xml
添加如下内容:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
2.4.2.5配置yarn-site.xml
添加如下内容:
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>1024</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>1</value>
</property>
</configuration>
2.4.2.6替换bin目录下的文件
加压winutils文件复制其bin目录下的所有文件覆盖到hadoop-3.1.3\bin中
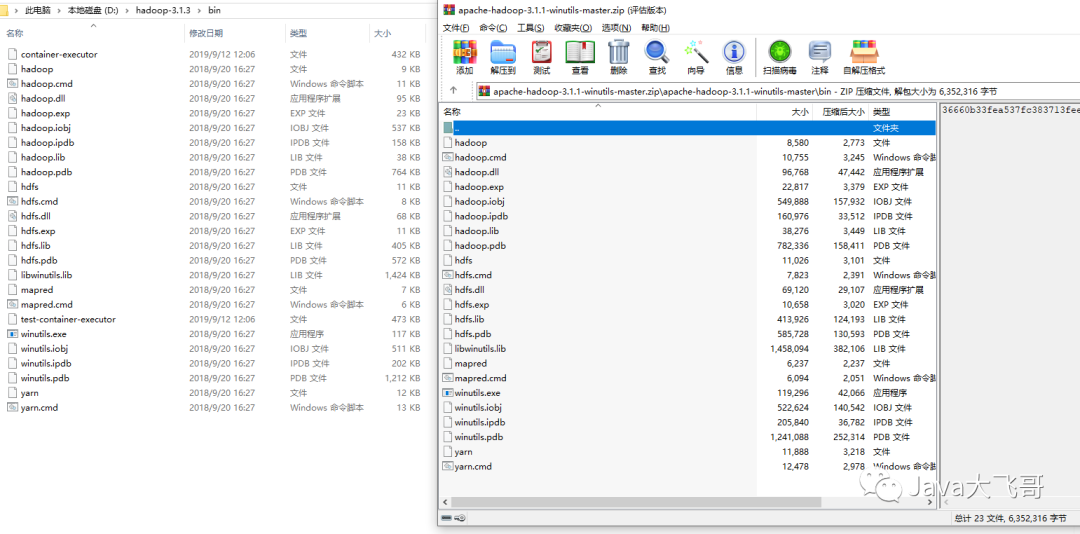
2.4.2.7 格式化节点
搜索命令提示符右键以管理员身份运行:
hdfs namenode -format
2.4.2.8 复制hadoop-yarn-server-timelineservice-3.1.3.jar
复制D:\hadoop-3.1.3\share\hadoop\yarn\timelineservice\hadoop-yarn-server-timelineservice-3.1.3.jar到D:\hadoop-3.1.3\share\hadoop\yarn目录下
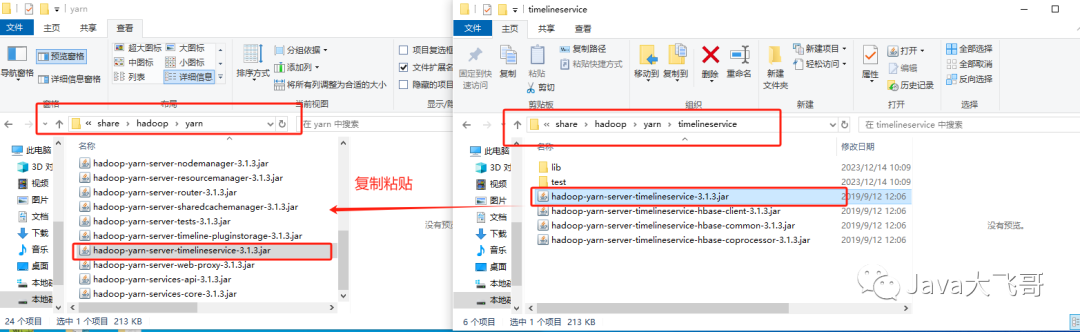
3.验证启动
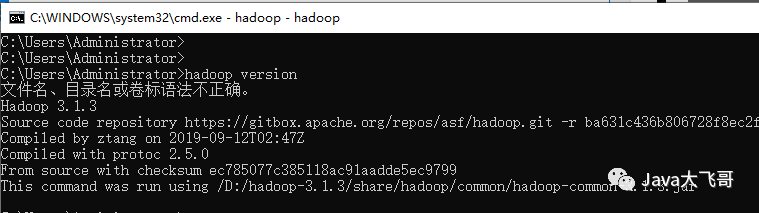
3.1查看hadoop版本
cmd命令提示符中执行以下命令:
hadoop version
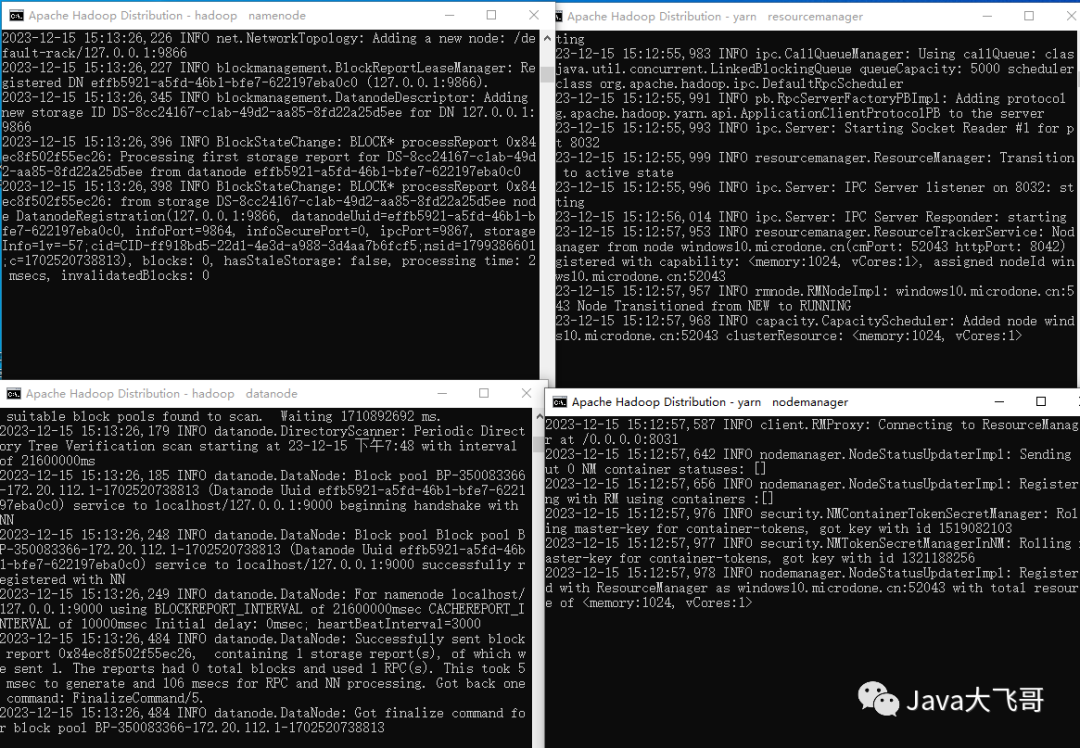
3.2启动
cmd到D:\hadoop-3.1.3\sbin运行start-all.cmd,或者是点击运行start-all.cmd运行,会弹出4个启动窗口,不要关闭
分别是namenode、datanode、nodemanager、resourcemanager这个4个java进程,并且没有任何报错,如果有报错就你就得排错一下了,可以使用jps命令查看到这4个java进程
4.访问
浏览器访问
http://localhost:9870/
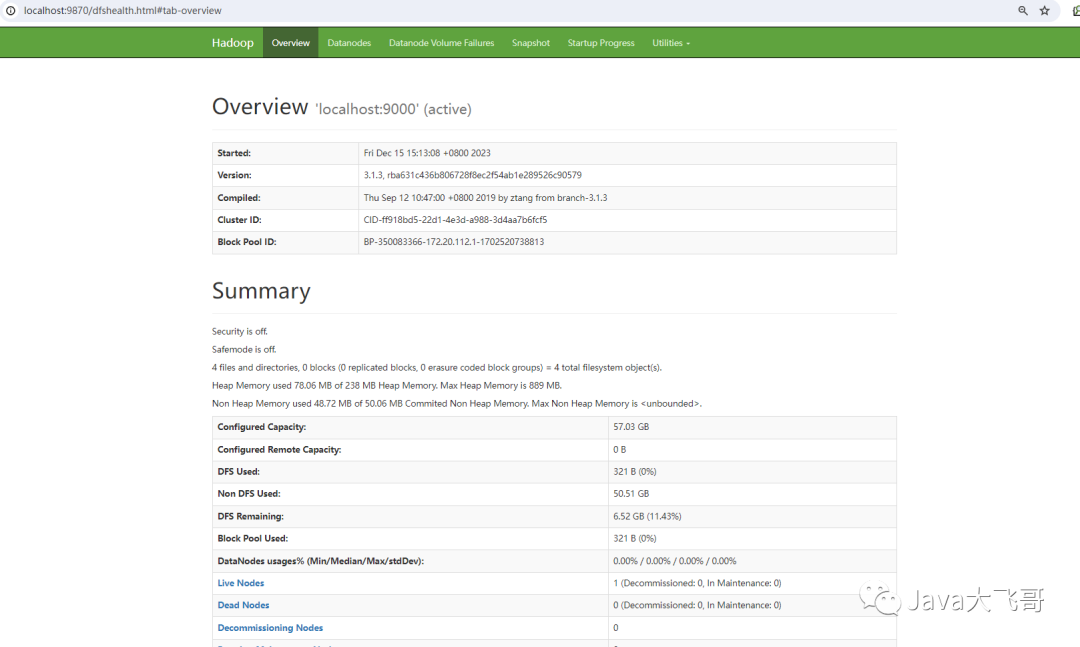
浏览器访问
http://localhost:8088/
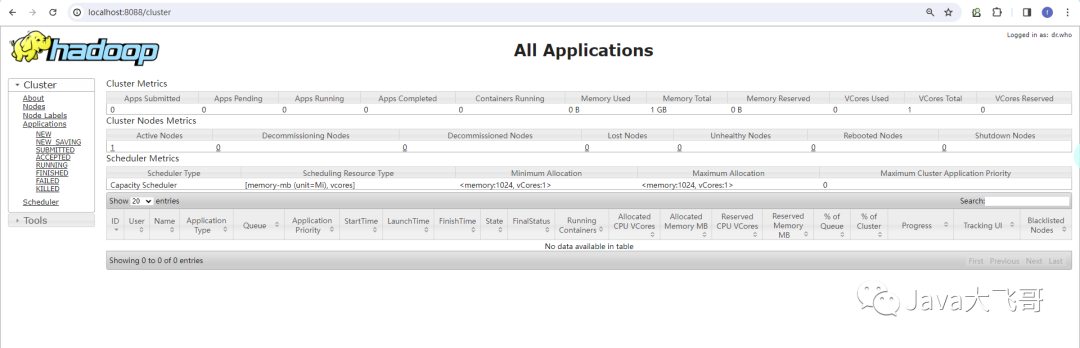
如果访问以上两个地址都可以打开的话,说明已经成功在windows10上安装好了hadoop的环境了
5.总结
安装hadoop为了后面本地其它工具实验(请启动后面的文章分享,跟这个有关系的)或项目使用hadoop环境,总结记录方面在本地更好更快的搭建使用hadoop环境,也可以使用docker/k8s部署hadoop环境,搭建这个hadoop其实也是踩了好多坑,看了好多坑的文章,后面终于安装成功了,就写了这篇文章分享给大家,希望我的分享能给你带来帮助,请一键三连,么么么哒!















 1000
1000











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









