






一、安装包、配置文件下载
1.hadoop官网下载
https://hadoop.apache.org/release/3.1.3.html
2.下载winutils(hadoop在window运行的工具)
可以去GitHub上下载,最好下载对应版本的
3.直接百度网盘下载hadoop、winutils
https://pan.baidu.com/s/1a56R1YwOiyiB73RxSrg6_g
提取码:u1dz
二、安装hadoop
1.解压hadoop
把下载的hadoop-3.1.3.tar.gz压缩包解压到自己要安装的位置

2.配置环境变量
(1)在系统的变量中创建变量HADOOP_HOME,变量值为自己hadoop安装的位置,可以浏览目录找到刚刚解压的hadoop-3.1.3

(2)在path变量中添加hadoop的bin路径:%HADOOP_HOME%\bin;

3.验证是否安装成功
进入cmd,输入命令hadoop version查看hadoop是否安装成功

4.进入hadoop-3.1.3目录,创建data和temp文件夹

5.进入data目录,创建datanode和namenode文件夹

6.进入hadoop-3.1.3\etc\hadoop目录,用记事本或者其他编辑器打开如下文件并配置

(1)配置文件core-site.xml,添加
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration> 
(2)编辑文件hdfs-site.xml,添加
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/D:/hadoop/hadoop-3.1.3/data/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/D:/hadoop/hadoop-3.1.3/data/datanode</value>
</property>
</configuration>这里要把两个“<value>”改成自己hadoop安装的地址。

(3)编辑文件mapred-site.xml,添加
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
(4)编辑文件yarn-site,xml,添加
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>1024</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>1</value>
</property>
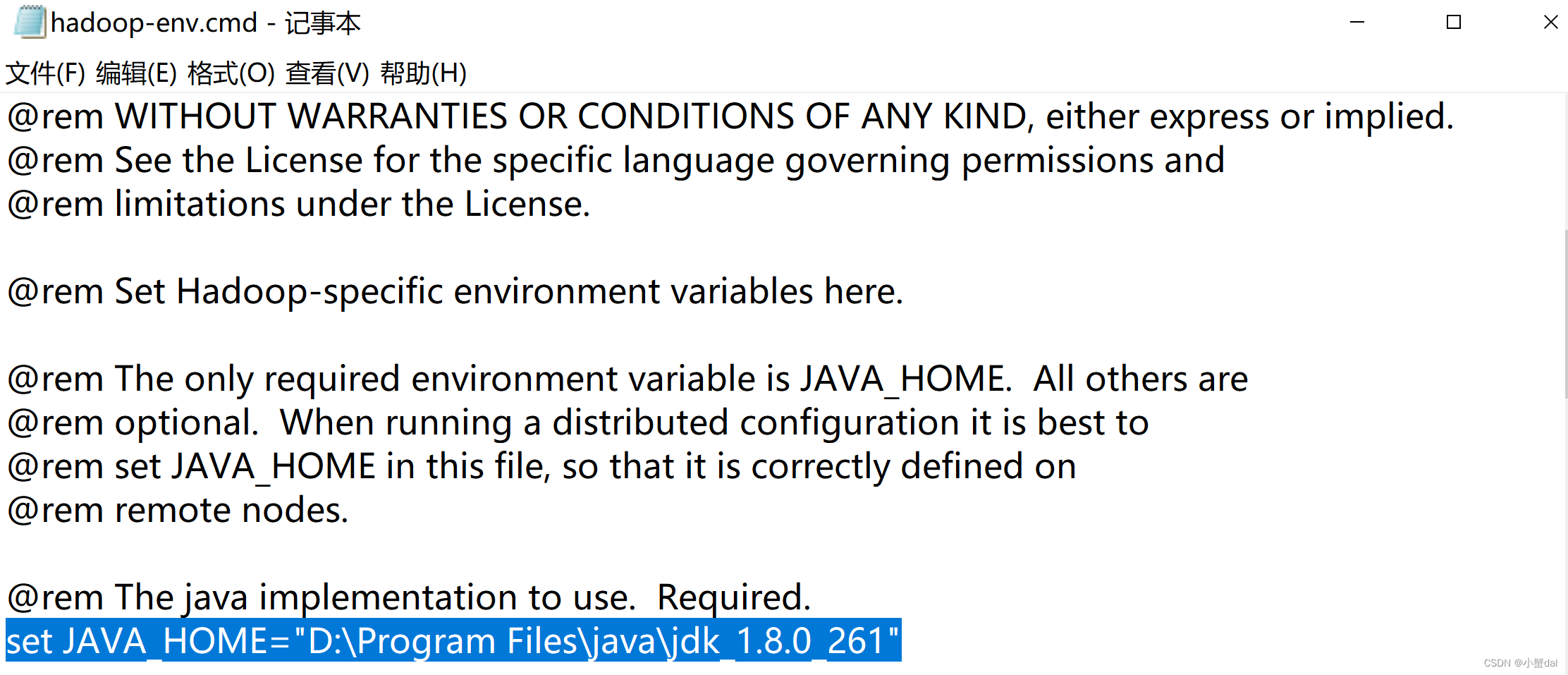
</configuration>(5)如果之前安装的jdk不是默认安装到C盘的路径,要修改hadoop-env.cmd文件中的“set JAVA_HOME=”后面的路径,并且最好把jdk的安装路径用双引号引起来,以免出错
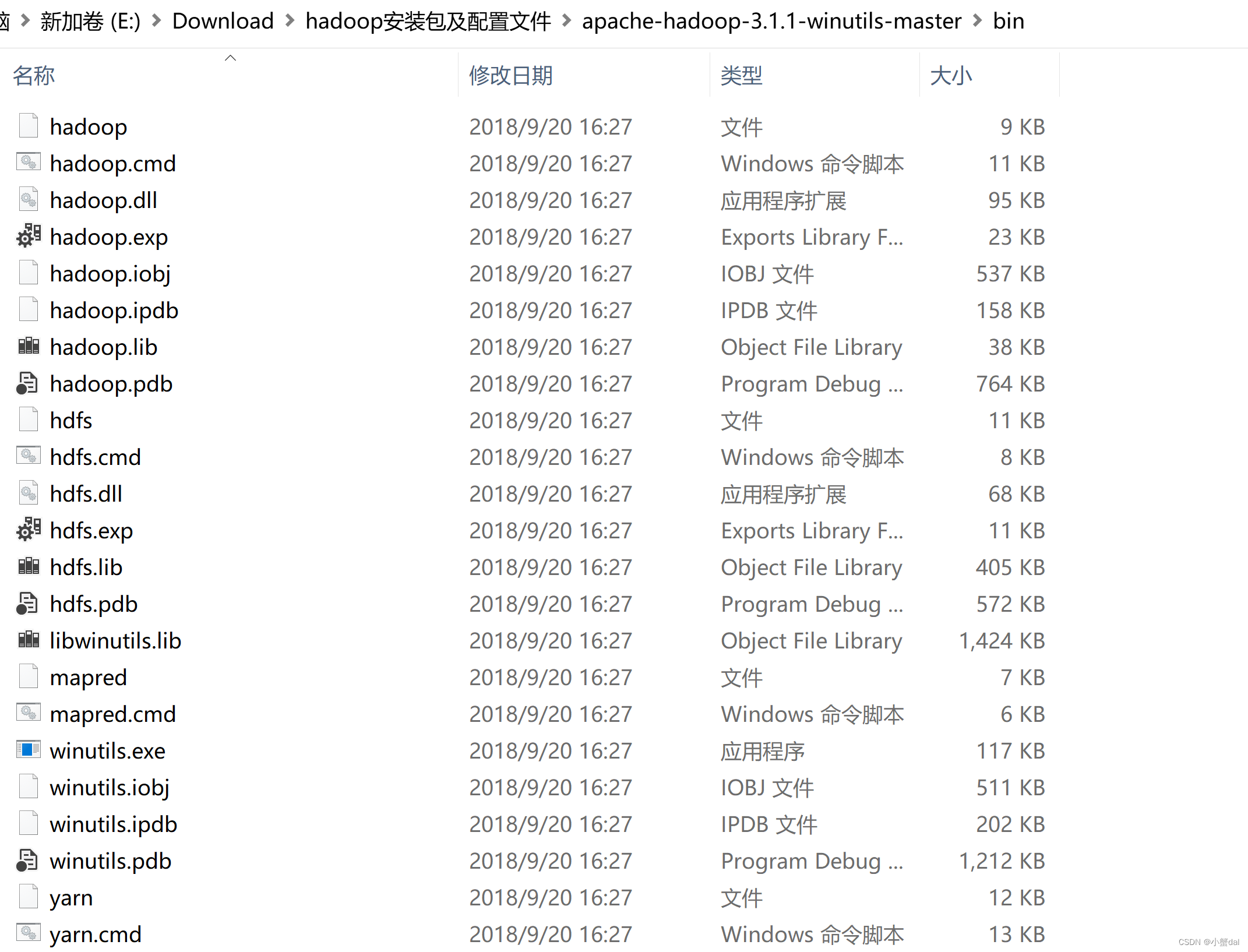
7.把之前下载的winutils里面的bin复制
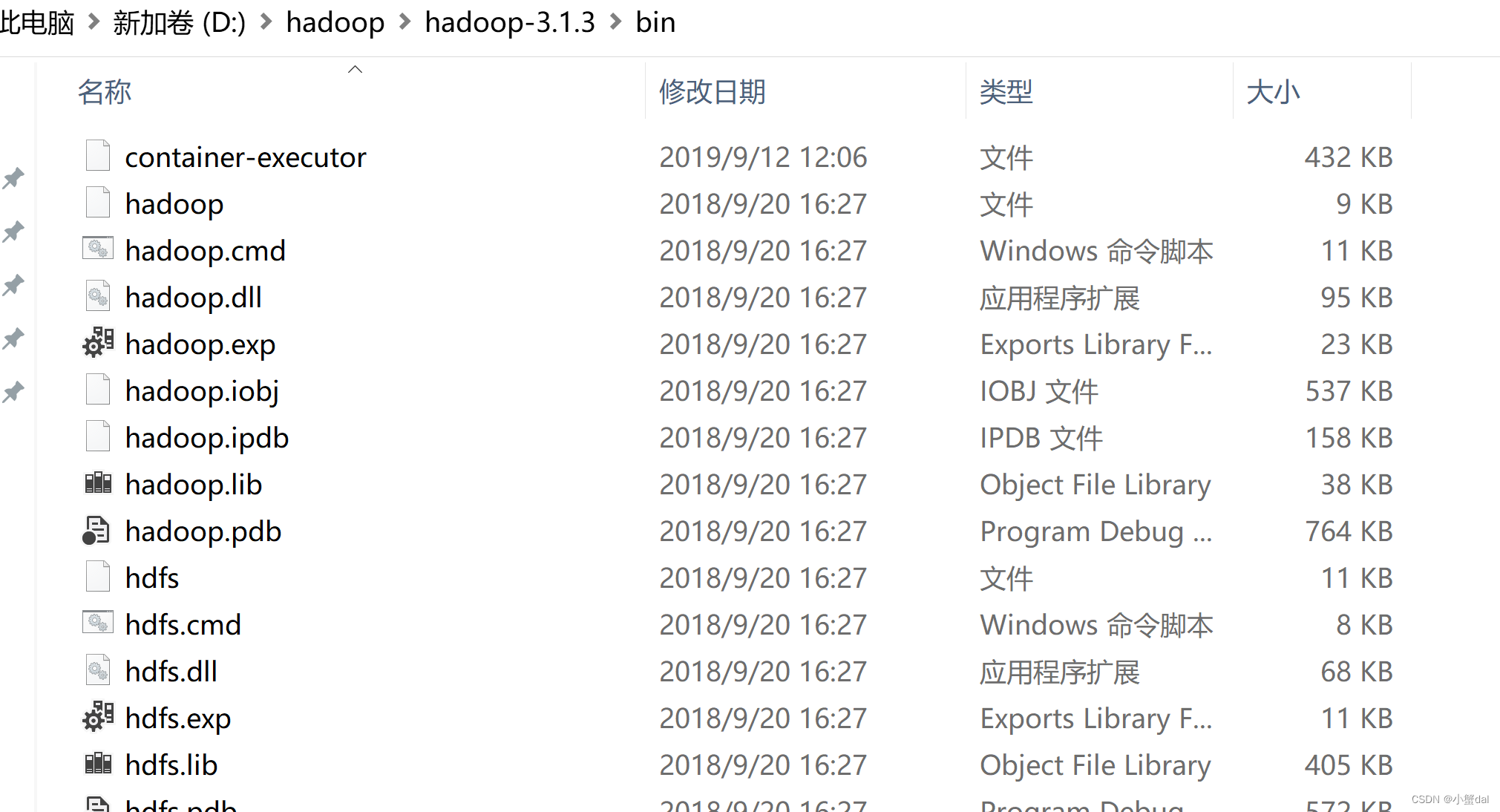
覆盖到hadoop-3.1.3\bin中
8.在cmd命令控制台输入hdfs namenode -format格式化节点

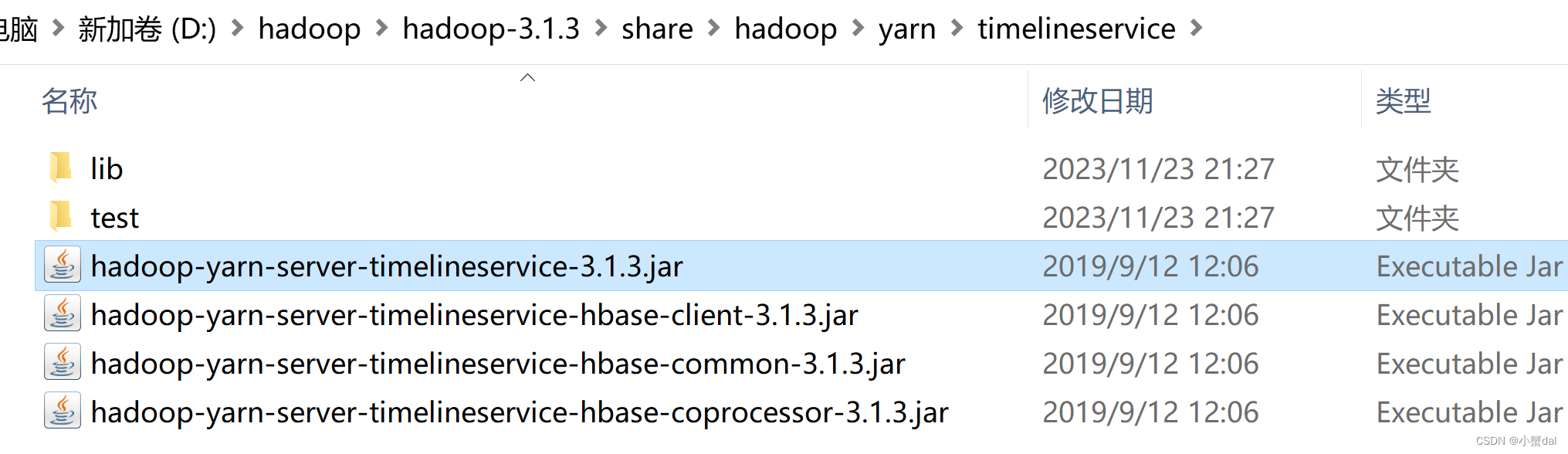
9.进入hadoop-3.1.3\share\hadoop\yarn\timelineservice,复制一份到hadoop-3.1.3\share\hadoop\yarn
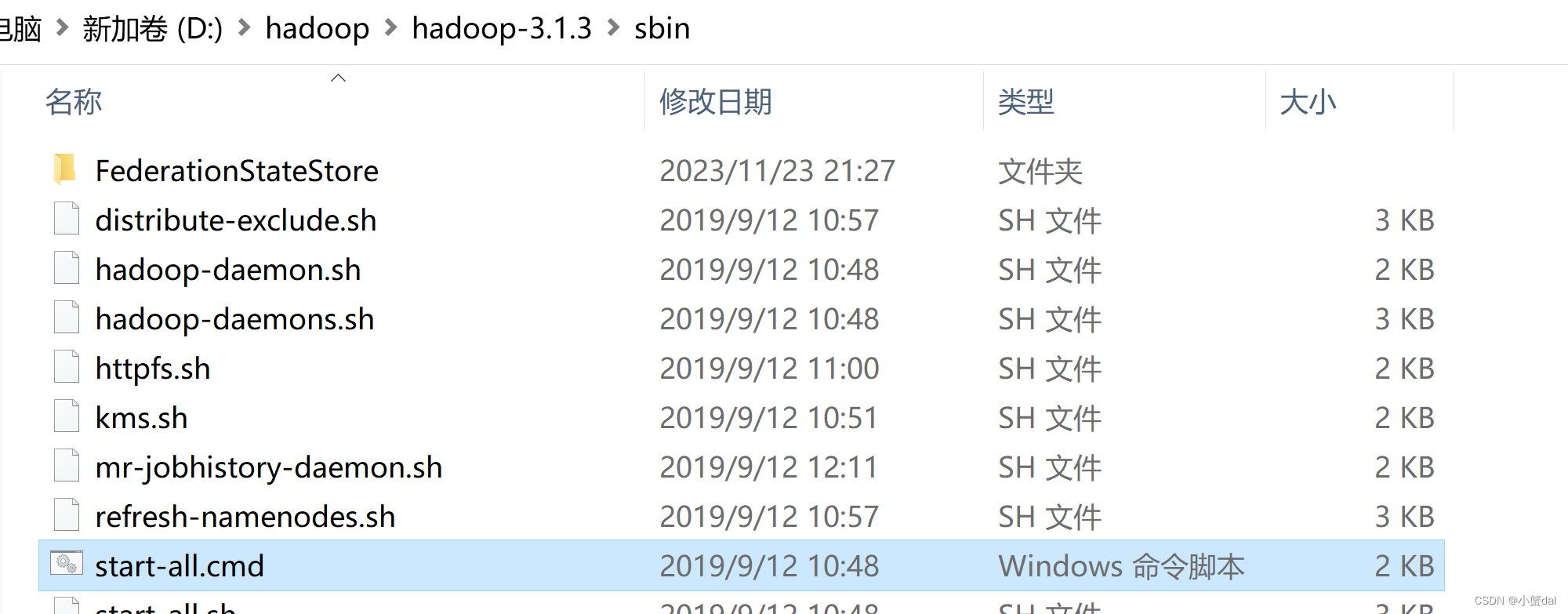
10.进入D:\hadoop\hadoop-3.1.3\sbin,运行start-all.cmd,启动
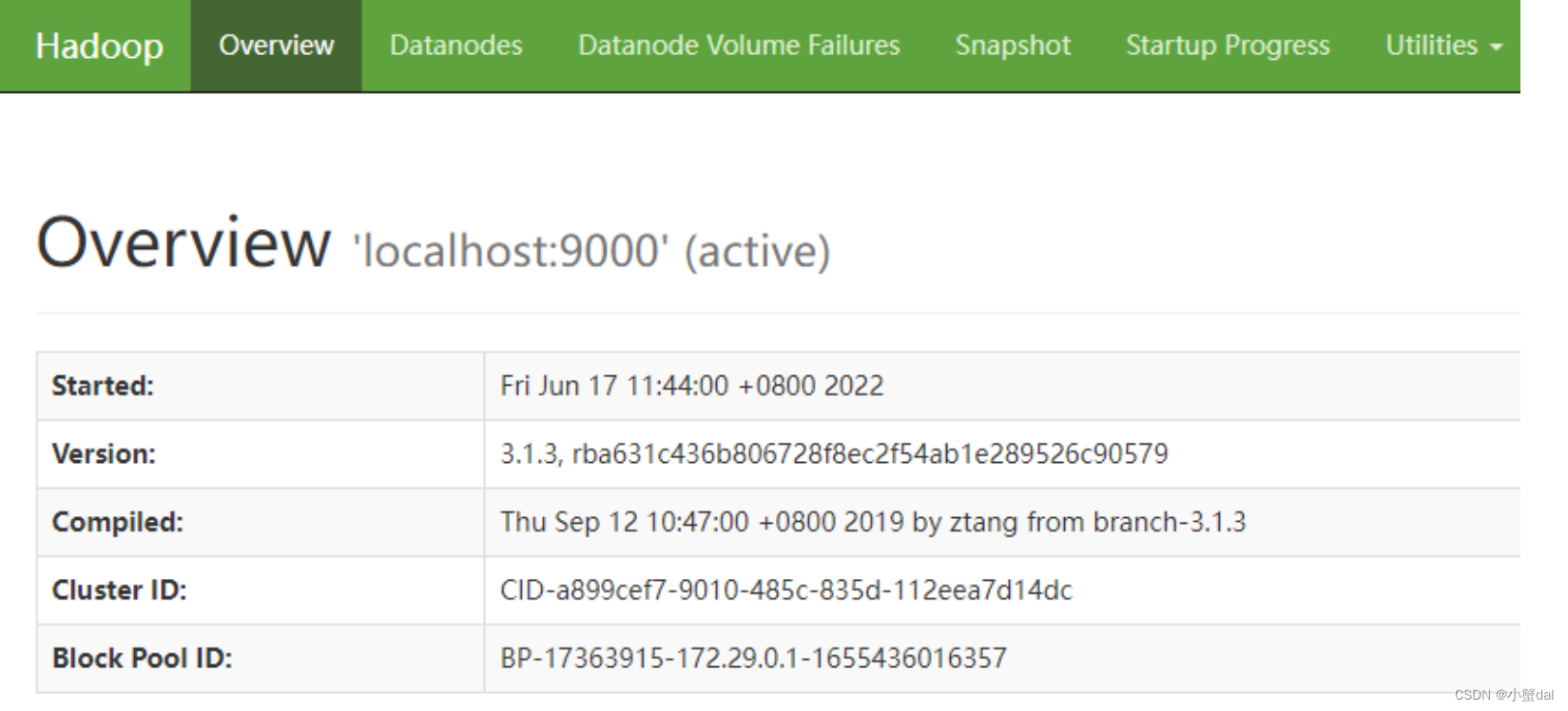
11.可以访问
(1)浏览器访问http://localhost:9870/
(2)浏览器访问http://localhost:8088/
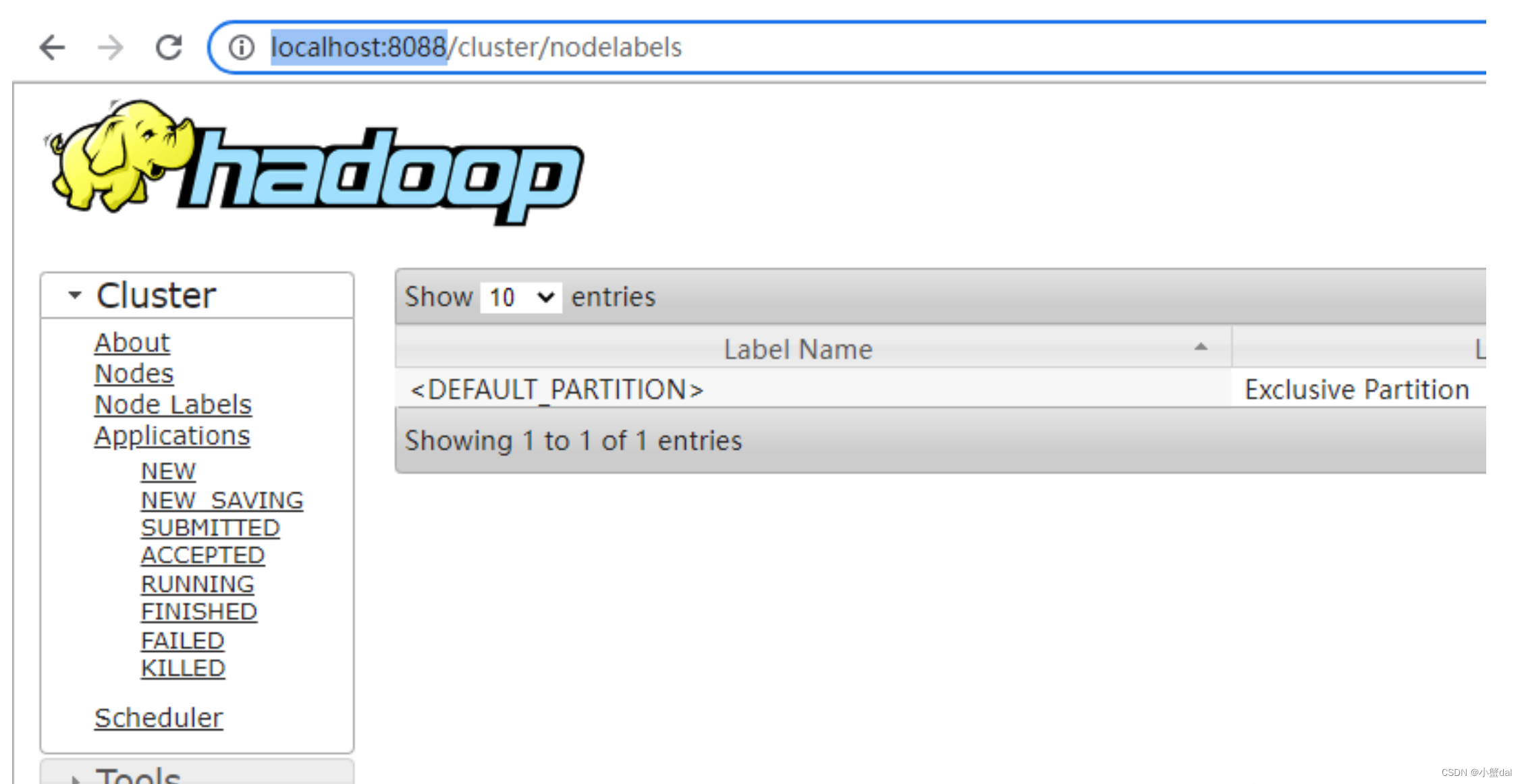
到此安装成功。

















 446
446

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









