







文章目录
首先来看一个面试题
Object o = new Object()在内存中占了多少个字节
先看一个图,这是普通对象和数组对象在内存中的基本结构
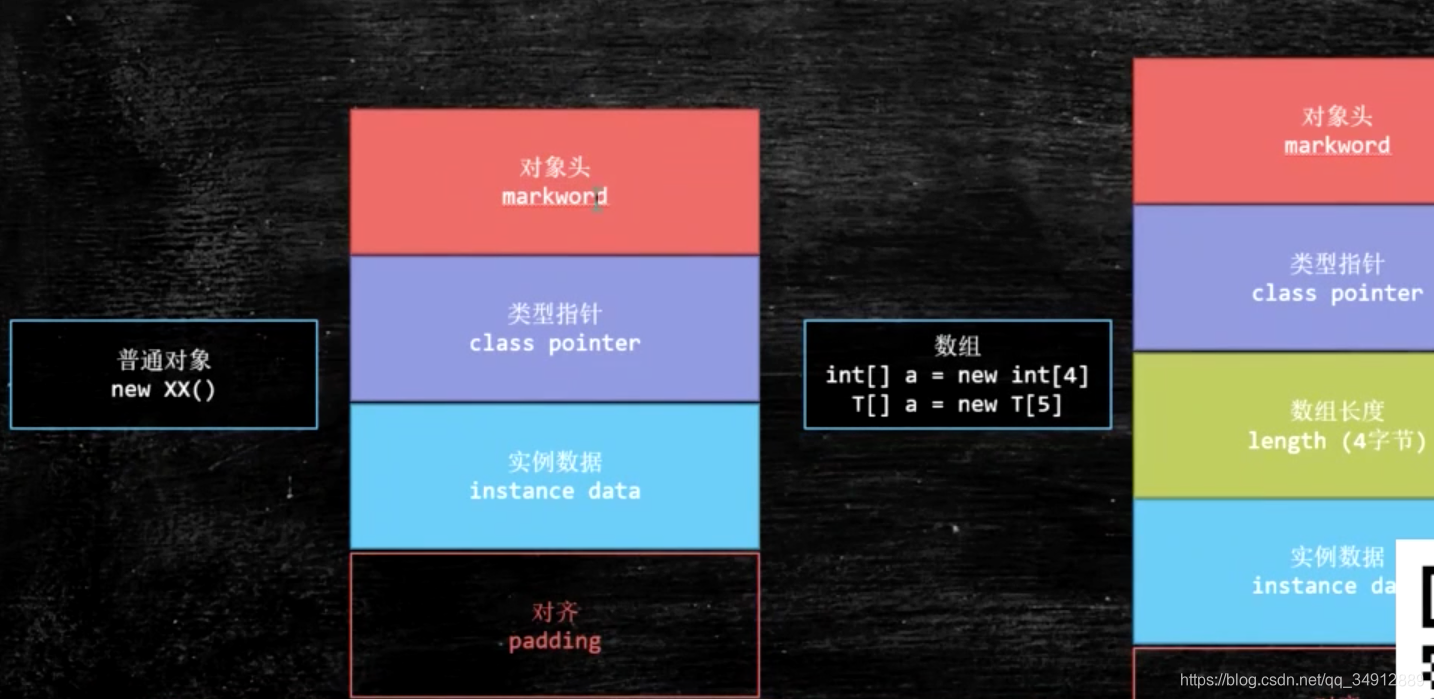
JVM读取堆内存的时候都是读取的8的整数倍内存,读取速度快,所以需要上图中最下面的对齐空间
对象头markword占了8个字节
对象头的ClassPoint指针占用了4个字节
因为Object对象没有属性所以属性占用内存为0
为了补齐内存让JVM读取效率最高,后面占用4个字节
Object对象不算补齐的位置共占用12个字节,为了使内存占用为8的整数倍,补齐内存占上4个字节,所以实际在堆中占用16个字节
如果要连指向这个对象的在栈上的指针也算上那就是20字节
那么如何得来的呢?
正常64位机的指针大小都是64位的,也就是8个字节,但是JVM启动的时候默认开启了两种指针压缩
使用
java -XX:+PrintCommandLineFlags -version,其中-XX:+PrintCommandLineFlags参数可以将java命令行执行一条命令的默认参数全部打印出来
如下图
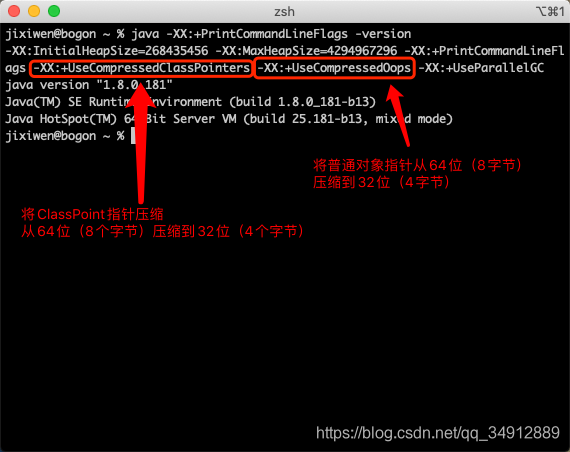
可以看到默认开启的两种指针压缩,将ClassPoint指针和普通对象指针都压缩到了4个字节,所以计算出最上面的结果
那么不开启ClassPointer压缩一个Object对象是占多少内存呢,结果仍然是16个
markword占用8个字节
ClassPoint占用8个字节
没有成员变量0字节
因为上面的加起来正好是8的整数倍了,所以对对齐也不需要了,那么就还是16个字节
使用JOL打印对象信息
JOL:Java Object Layout
中文名:Java对象布局
这是OpenJDK为我们提供的工具,使用该工具我们可以打印Java对象的信息
首先引入Maven依赖
<dependencies>
<dependency>
<groupId>org.openjdk.jol</groupId>
<artifactId>jol-core</artifactId>
<version>0.9</version>
</dependency>
</dependencies>
新建一个类来写下面的代码
public class helloSync {
public static void main(String[] args) {
Object o = new Object();
System.out.println(ClassLayout.parseInstance(o).toPrintable());
synchronized (o){
System.out.println(ClassLayout.parseInstance(o).toPrintable());
}
System.out.println(ClassLayout.parseInstance(o).toPrintable());
}
}
上面的代码就是在上锁前,上锁时,上锁后,打印实例o在内存中布局信息,输出结果如下
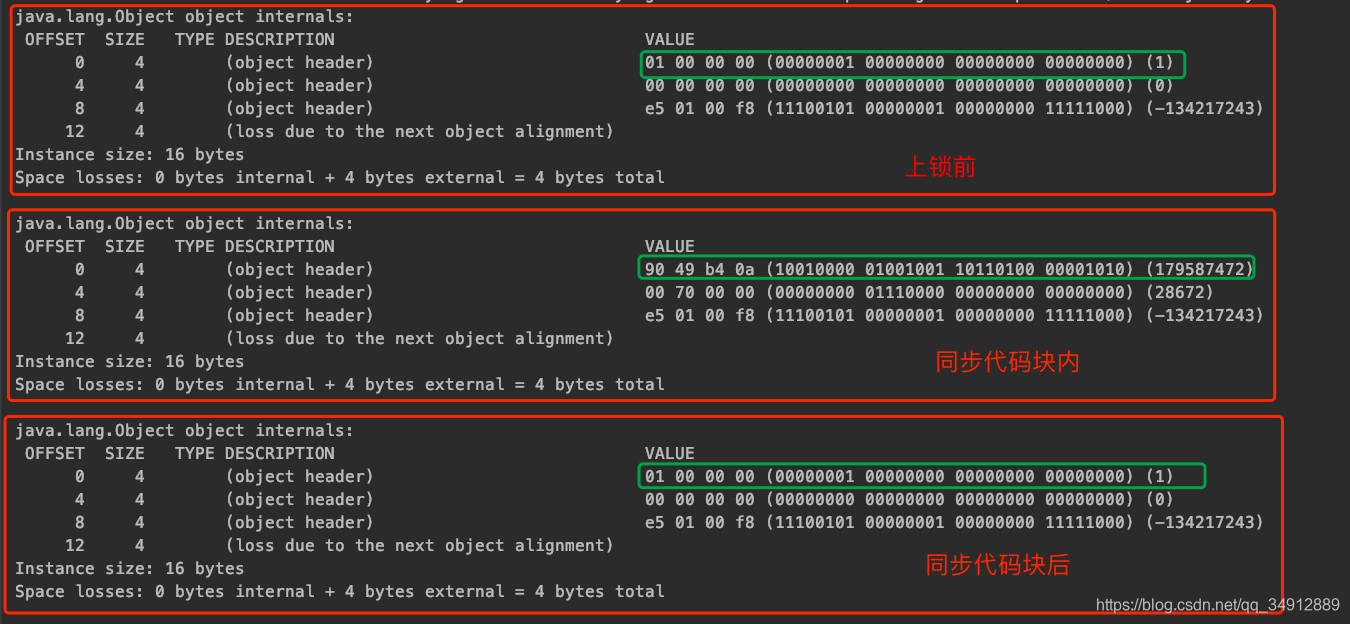
可以看到只有绿色区域的部分有所不同,该区域是对象头中的markword的一部分,那么我们可以得知锁信息是存在markword中的,并且只有执行同步代码块的时候markword中才会存储锁信息,代码块后面就没有了
锁升级
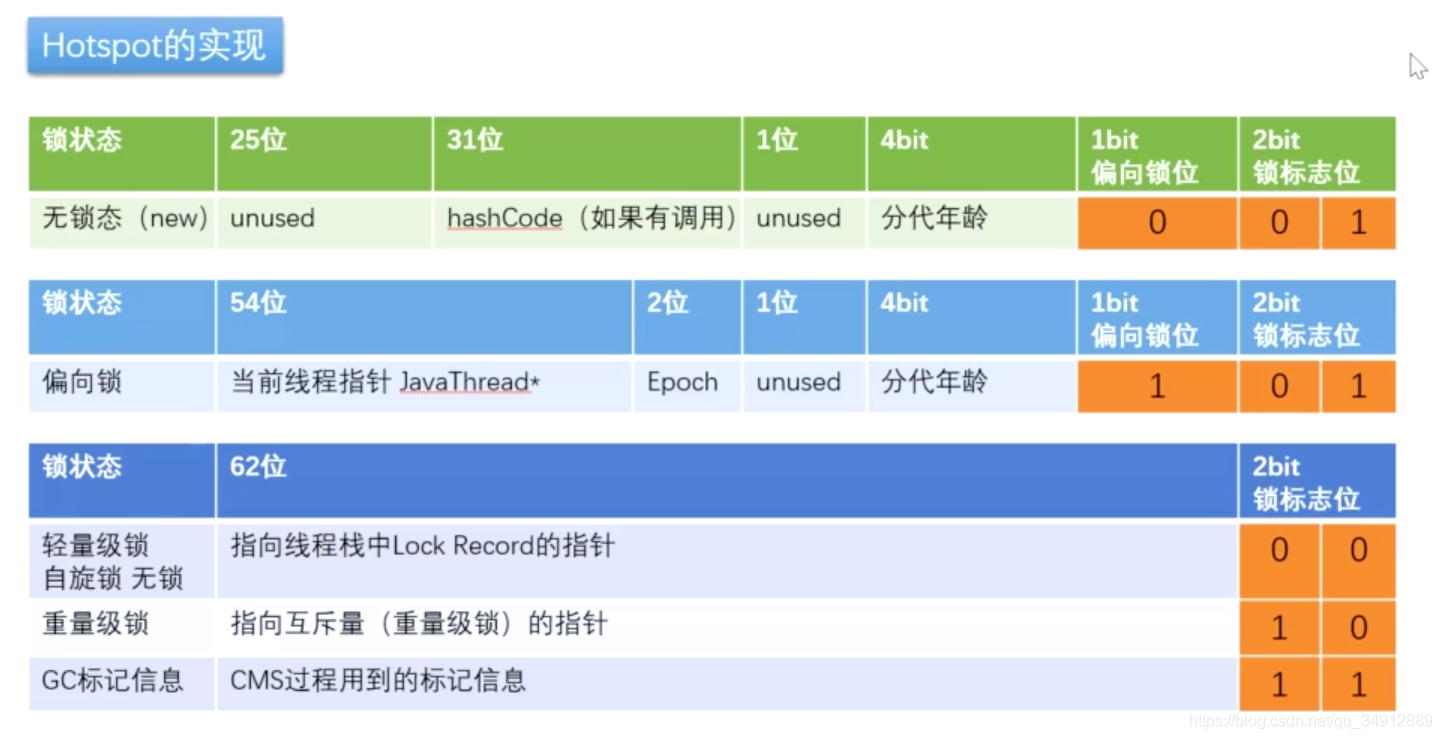
锁升级的顺序
刚刚new对象的时候 - 偏向锁 - 轻量级锁(无锁,自旋锁,自适应自旋) - 重量级锁
所有的锁信息都存储在对象的markword中,markword一共64位(就是8个字节),都用来存储这些锁信息
以下就是锁升级的整个过程中markword中的信息变化
锁降级(不重要 )
在特定的场景下会发生锁降级,比如GC的时候,但是如果这个对象已经在GC的过程中了,那么讨论锁降不降级也没有意义了,因为降级之后也会被GC掉,所以锁降级可以被认为是不存在的
锁消除 lock eliminate
public void add(String str1, String str2){
StringBuffer sb = new StringBuffer();
sb.append(str1).append(str2);
}
我们都直到StringBuffer是线程安全的,因为他的关键方法都是被synchronized修饰过的,但我们看上面这段代码,我们会发现,sb这个实例只会在add中使用,不可能被其他线程引用(因为是局部变量,栈私有),因此sb是不可共享的资源,JVM会自动消除StringBuffer的对象内部的锁
锁粗化 lock coarsening
public String test(String str){
int i = 0;
StringBuffer sb = new StringBuffer();
while (i < 100){
sb.append(str);
i++;
}
return sb.toString();
}
JVM会检测到这样一连串的操作都对同一个对象加锁(while循环内100次执行append,没有锁粗化就要进行100次加锁、解锁),此时JVM就会将加锁的范围粗化到这一连串的操作的外部(比如while循环体外),使得这一连串的操作只需要加一次锁即可。
Unsafe
java中提供的原子操作类(Atomic包下的类),有很多的CAS操作,其底层都是调用的native方法(本地方法,c++写的),当查看JVM的源码的时候会发现,最底层使用的是汇编语言的 lock cmpxchg 指令
cmpxchg = cas 修改变量值
lock锁定当前的值
硬件:
lock指令再执行后面指令的时候锁定一个北桥信号(不采用锁总线的方式)
hsdis反汇编插件可以看jit编译后的汇编文件,不会用的话就搜一下
查看汇编文件可以看到volatile和synchronized用的都是lock cmpxchg 指令
synchronized 实现过程
1.java代码:使用synchronized关键字
2.字节码文件中:使用monitorenter{同步代码块}和monitorexit
3.JVM执行过程中自动升级
4.汇编层面使用lock comxchg
内存屏障的基本概念
线程和进程的区别
进程:分配资源的基本单位
线程:cpu执行的基本单位
cpu的组成
ALU(逻辑运算单元)
PC(指令寄存器)存储下一条指令在内存中的位置
Registers(寄存器)临时存储需要计算的资源
cache(缓存)
线程上下文切换(比如A线程切B线程)
先将PC | Registers中A线程的内容保存起来,然后读取B线程执行所需的资源,再次切回A的时候先将B的保存起来,然后再将A之前临时存的读回来
超线程:
一个ALU对应多组 PC | Registers(一般是两组,工程的最佳实践)例如四核八线程
节省了线程切换的时间
volatile
两个特性
- 线程可见性
- 禁止指令重排序
cache line的概念 缓存行对齐 伪共享
如果读取缓存中没有的数据,那么缓存全部读取顺序为 L1->L2->L3->内存,此时读到资源,再将该资源进行内存->L3->L2->L1的顺序进行缓存,这么一趟操作下来很费时间,所以有了缓存行的概念,该概念是
将缓存按块读,比如读X的时候,会将X所在的内存块全部读取进来,因为程序运行有连续性,和X在同一块内存的资源很容易在运行下一条指的时候用到
缓存行的一行数据64字节
缓存行被迫刷新
由于cpu在读取资源的时候有读取一个缓存行的特性,假设T对象只有一条属性x,并且使用volatile关键字修饰该x属性,那么此时新建一个长度为2的T对象数组a[],由于两个对象的大小加起来也不够64字节,所以在内存中很容易就分配到同一个缓存行中,假如a[]数组的两个元素分配到同一个缓存行中,现在有两个线程A、B同时修改a[0]和a[1](A只修改a[0],B只修改a[1]),那么A修改之前会从缓存行读取整个行中的数据,只修改了其中一部分也就是a[0],但是a[1]也在缓存行中,由于volatile的特性,导致A修改完成后,会强制通知其他线程,该缓存行的数据更新了,那么线程B读取a[1]的时候会被强制刷新整个缓存行,重新走一遍缓存的逻辑,由于B修改的是同一块缓存行,下次A线程再修改或者读取a[0]的时候,又被强制刷新,这样导致了两个线程修改的不是同一个对象的原子属性,却被迫做了刷新缓存的操作
总结:每次某个线程修改整个缓存行中的一部分数据的时候,其他线程如果想修改该行内的其他数据则会被强制刷新缓存,从而导致效率降低,这里多个线程修改的不是同一个volatile属性,理论上不应该做同步操作,但却做了线程强制可见的操作,使我们不希望看到的,所以有些人就会使用缓存行进行填充填充使volatile的字段与缓存行对齐,来解决这个问题
比如disruptor这个最快的单机队列,他就使用的缓存行填充
缓存行填充
前提:使用volatile关键字修饰主要属性,导致线程强制可见的时候才需要填充缓存行
原理:在对象内主要属性的前后填充一些无关数据,比如volatile修饰的主要属性占用8个字节,那么在该对象的主要属性前声明7个long类型的字段,后面再声明七个long类型的字段,这样不管是从前面还是后面,该属性永远不可能和其他的字段在同一个缓存行内,在两个线程不会同时修改这个属性的时候会大大提高效率(大概三倍)
代码

当然这样也造成了缓存的浪费,缓存行越大所需空间越大,造成的浪费也就越多














 112
112











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









