









Generative Methods是通过构建代理任务(proxy task)来进行自监督学习。
在前文(自监督学习(Self-Supervised Learning)个人小结)中我们已经讨论了这种方法的原理和为什么它可以work,本篇博客主要想总结下这类方法的几篇工作。
文献目录
[1] Xiaolong Wang, Abhinav Gupta. “Unsupervised leaning of visual representation using videos”. In: ICCV 2015.
[2] Carl Vondrick, Abhinav Shrivastava, Alireza Fathi, et al. “Tracking emerges by colorizing videos”. In: ECCV.
2018.
[3] Xiaolong Wang, Allan Jabri, and Alexei A Efros. “Learning correspondence from the cycle-consistency of
time”. In: CVPR. 2019.
[4] Xueting Li, Sifei Liu, Shalini De Mello, et al. “Joint-task self-supervised learning for temporal correspondence”.
In: NeurIPS. 2019.
[5] Ning Wang, Yibing Song, Chao Ma, et al. “Unsupervised Deep Tracking”. In: CVPR. 2019.
[6] Allan Jabri, Andrew Owens, and Alexei A Efros. “Space-time correspondence as a contrastive random walk”.
In: NeurIPS. 2020.
一、Unsupervised leaning of visual representation using videos
作者:Xiaolong Wang, Abhinav Gupta
Paper:https://arxiv.org/pdf/1505.00687v2.pdf
1、摘要
学习良好的视觉表现需要强有力的监督吗?我们真的需要数百万张语义标记的图像来训练卷积神经网络(CNN)吗?在本文中,我们提出了一种简单但令人惊讶的方法的CNN无监督学习。具体来说,我们使用网络上成十万的未标签视频来学习视觉表征。我们的关键思想是,通过视觉跟踪来提供了监督信号。也就是说,由轨道连接的两个补丁在深度特征空间中应该具有相似的视觉表示,因为它们可能属于同一个对象或对象部分。我们设计了一个具有排序损失函数的Siamese-triplet网络来训练这个CNN表示。如果不使用来自ImageNet的单一图像,只使用100K未标记的视频和VOC2012数据集,我们训练一个无监督网络的集合,可以达到52%的mAP(不包括box的回归)。这种性能非常接近imagenet监督的集成,一个达到了54.4%的集合。我们还表明,我们的无监督网络可以在其他任务应用,如表面状态估计。
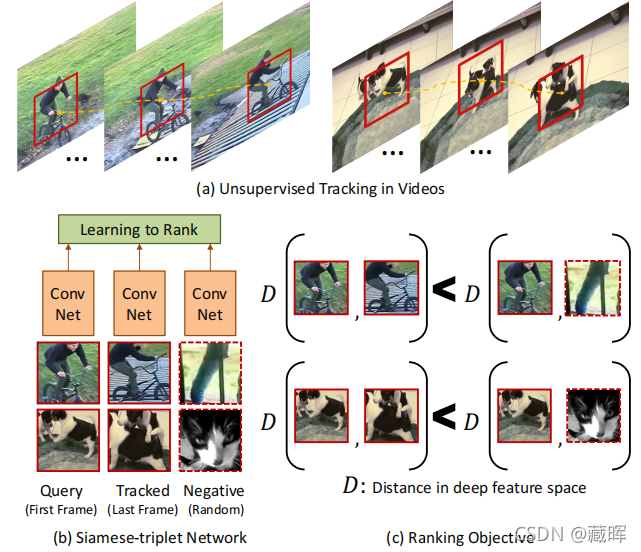
🔺比较早期的文章,思想很好理解(如图示),方法基于视频的时序性相似假设,一个视频中越相邻的两个帧在深度特征空间中应该具有相似的视觉表示,因为他们属于同样的对象,而在不同的视频序列上的目标应该具有不一样的特征表示。通过这种思路就可以构建一个rank的损失,保持同一个视频序列中的目标distance小于不同视频序列的目标。
2、方法
方法主要涉及到两个方面,一个是如何采样triple,另一个是怎么构建损失。
对于triple的采样来说,负样本其实很好定义,正样本如何无监督的提取感兴趣位置比较难。文中这部分采用了一个方法,分为以下两步:
1)我们得到了SURF的兴趣点,并使用改进的密集轨迹方法(IDT)来获得每个SURF点的运动。请注意的是,由于IDT采用了同源估计(视频稳定)方法,因此它减少了相机运动引起的问题。给定SURF感兴趣点的轨迹,如果流的大小大于0.5像素,我们将这些点归类为移动。我们会不采用这样的帧:(a)极少(<25%)的SURF兴趣点被归类为移动的,因为它可能只是噪声;(b)大多数SURF兴趣点(>75%)被归类为移动兴趣点,因为它可能对应于移动的照相机。
2)一旦我们提取了移动的冲浪兴趣点,我们找到了最好的边界框,这样它就包含了大部分移动的SURF点。边界框的大小设置为h×w,我们在框架中执行滑动窗口。我们以包含最多移动SURF兴趣点的边界框作为兴趣边界框。
在边界框获得之后就锁定了感兴趣问题,然后用KCF来获得整个视频的跟踪结果。
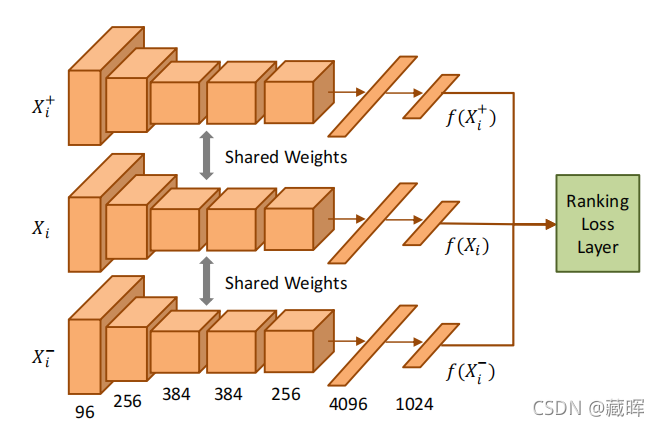
该网络结构用的是AlexNet,中通过只使用两个完全连接的层进行修正。对于损失来说,将每一个patch提取出向量,计算余弦距离,然后损失比较像triple loss。
二、Tracking emerges by colorizing videos
作者:Carl Vondrick, Abhinav Shrivastava, Alireza Fathi, et al
Paper:http://www.cs.columbia.edu/~vondrick/videocolor.pdf
1、摘要
我们使用大量的未标记的视频来学习视觉跟踪的模型,而无需人工监督。我们利用颜色的自然时序一致性来创建一个模型,通过从参考系中复制颜色来学习灰度视频的着色。定量和定性实验表明,这项任务会导致模型自动学习跟踪视觉区域。虽然该模型的训练没有任何groundtruth,但我们的方法学习了足够好的跟踪,以优于基于光流的最新方法。此外,我们的研究结果表明,跟踪失败与着色失败相关,提示推进视频着色可能进一步改善自我监督的视觉跟踪。
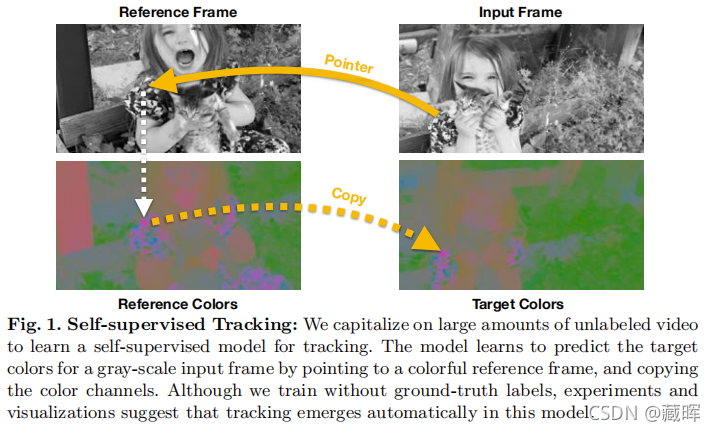
🔺 本文章提出了在颜色空间来学习tracking的思路,其本质是基于一个假设,学习视频的着色可以在本质上学习出一个跟踪器(我的理解是tracking的本质是学习特征的一致性,而跨帧的着色存在一样的本质,所以用它做proxy task可以学习到tracking的能力)。
2、方法
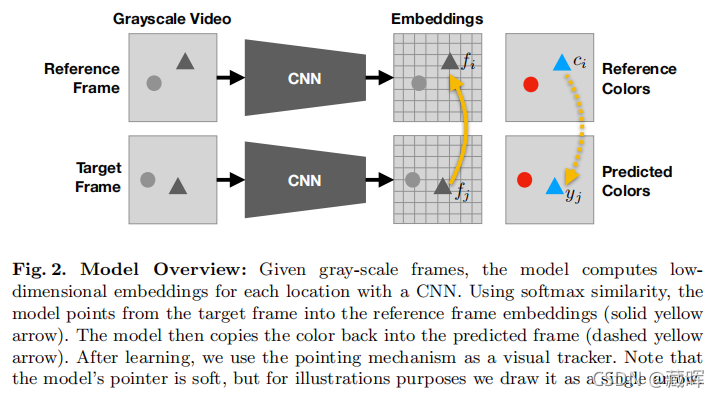
这个方法很有意思,首先将灰度图输入到CNN网络(用的ResNet-18)中获得两个特征图,然后计算Target Frame在Reference Frame的相似性,获得变换矩阵A,这个变换矩阵的含义通过相似性找到该点于周围其他点之间的关联,如果相似性很高在着色的时候就会多考虑其像素值,反之少考虑。通过该操作可以获得Reference Frame在Traget Frame上的着色预测。之后通过和原来的Target Frame做比较就可以构建一个有效的监督信号。
与之前的图片pixel学习不同,作者用的损失是用于分类的的交叉熵损失。因此需要通过使用k-means(使用16个聚类)对数据集中的颜色通道进行量化。
因为在训练的过程中,着色的最理想情况就是学习到了pixel的相似度,而本方法所学习到的模型很自然地可以利用在一些pixel相关的跟踪,比如Segment Tracking或者Keypoints Tracking。
在测试的时候,因为可以计算获得两帧之间的变换矩阵A,所以很容易去获得一个Mask或者Key points的传播。具体计算可以了解原文,或者可以去看下我在之前一篇博客,有写过这个的步骤:
https://blog.csdn.net/qq_34919792/article/details/120127373?spm=1001.2014.3001.5501
三、Learning correspondence from the cycle-consistency of time
作者:Xiaolong Wang, Allan Jabri, and Alexei A Efros
Paper:https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=8954240
1、摘要
我们介绍了一种自监督学习方法从未标记的视频中学习视觉对应关系。其主要思想是利用时间上的周期一致性作为自由的监督信号,从头开始学习视觉表征。在训练时,我们的模型学习了一个特征图表示,以用于执行周期一致的跟踪。在测试时,我们使用获得的表示来寻找在空间和时间上的最近邻居。我们展示了无需任何微调的通用性表征,可以用于一系列的任务,包括视频物体语义分割,关键点跟踪和光流。我们的方法优于以前的自监督方法,并在强监督方法中具有竞争力。
🔺这篇文章的思路也是想通过视频的时序一致性来构建监督信号进行自监督学习。相比于第二篇文章用颜色来作为监督信号,这篇文章的作者提到用周期一致性(cycle-consistency)的监督能力要更强一些。
2、方法
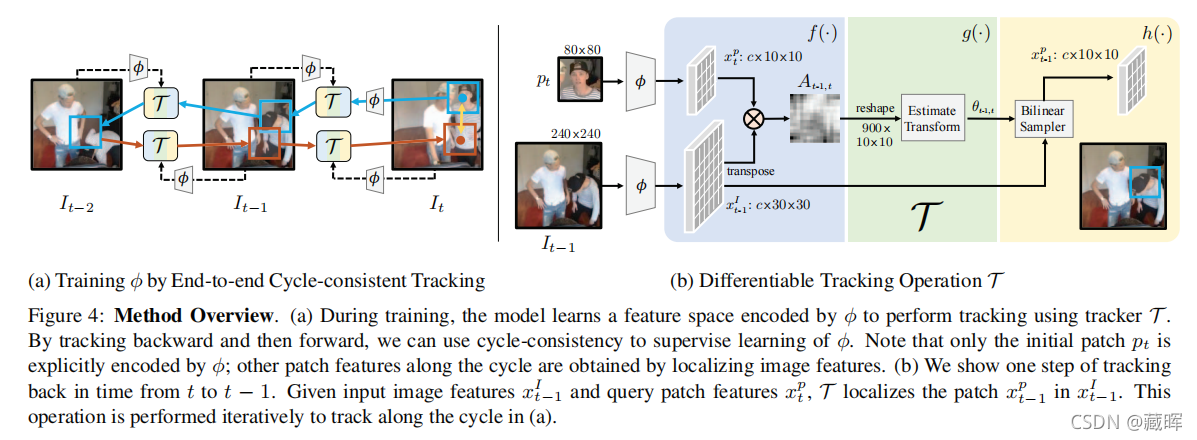
其思路很好理解,是想通过跟踪从图像中提取的补丁pt(蓝色框),用单目标跟踪器从t帧跟踪到t-k帧,然后再跟踪回来,同时最小化周期一致性损失lθ(黄色箭头)。因为所提出的无监督学习方案旨在获得一个通用的特征表示,而不是严格意义上需要去跟踪一个物体。所以在第一帧中的pt是一个随机初始化的边界框,它可能不覆盖整个对象。
网络结构很好懂,是一个比较正常的SOT的framework(提取器文中用的ResNet50,也有ResNet18的实验),主要是如何构建Cycle-Consistency Loss上,在这之前,我们先了解下lθ是啥?它是一个带双线性插值的均方误差损失,双线性插值为了是包装x的大小一样。

Cycle-Consistency Loss包含三个损失:
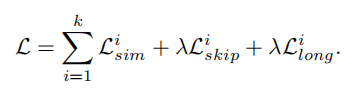
第一个损失关于跟踪:周期一致损失定义为(跟踪回来的目标要和之前的在特征上一致):
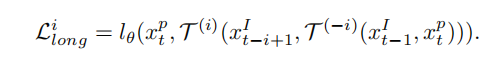
第二个损失是Skip Cycle,意思是增加步长来获得更长范围的匹配(好像就是跳一步,再跳回来)。
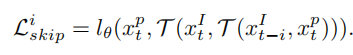
第三个是特征相似性,希望每一次跟踪到的特征和当前帧的特征相似。
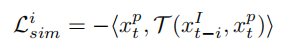
在测试上和上一篇文章一样,通过计算两帧之间的相似矩阵A来实现传播。
四、Joint-task self-supervised learning for temporal correspondence
作者:Xueting Li, Sifei Liu, Shalini De Mello, et al
Paper:https://arxiv.org/pdf/1909.11895.pdf
1、摘要
本文提出以自监督的方式从视频中学习可靠的密集通信关系。我们的学习过程整合了两个高度相关的任务:跟踪大图像区域,在连续视频帧之间建立细粒度像素级关联。我们通过一个共享的帧间亲和矩阵来利用这两个任务之间的协同作用,该矩阵同时在区域和像素级别上模拟视频帧之间的转换。而区域级定位通过缩小搜索区域,有助于减少细粒度匹配中的歧义;细粒度匹配提供了自下而上的特性,以方便区域级的定位。我们的方法在各种视觉对应任务中优于最先进的自监督方法,包括视频对象和部分分割传播、关键点跟踪和对象跟踪。我们的自监督方法甚至超过了从ImageNet上预训练的ResNet-18中获得的完全监督的亲和特征表示。
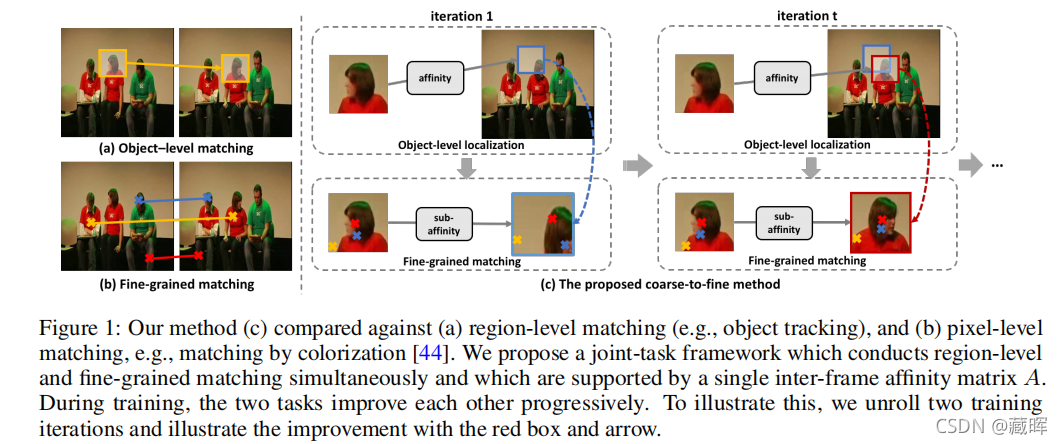
🔺 依然是想从视频序列学习到自监督的信息,但是和之前的方法不同的是,这个方法提出了区域的匹配和细粒度的匹配是可以共同促进的。这篇文章的关键思想是通过学习一个单一的亲和关系矩阵,用于建模所有的帧间转换,通过一个网络,学习适当的特征表示来建模亲和关系。
2、方法
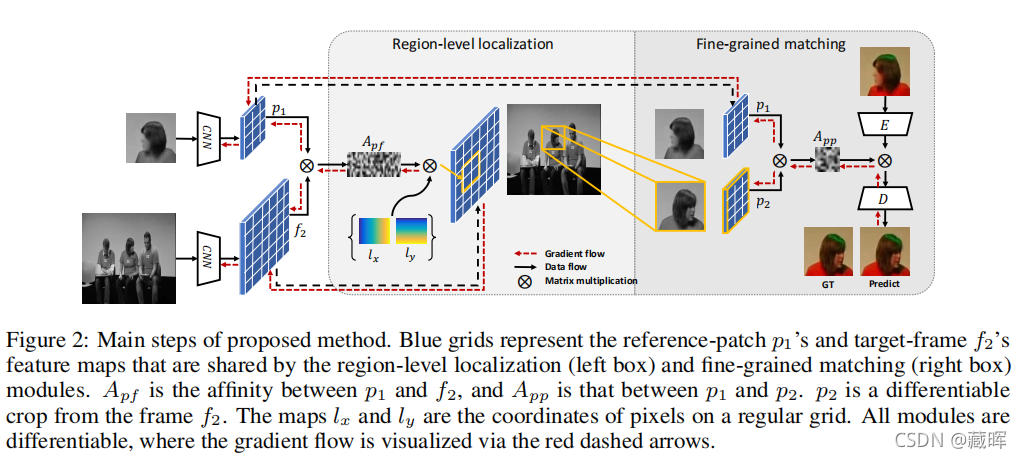
这个方法从图中很直观的可以了解到。第一部分是一个SOT的模型,用embeddings去计算相似性矩阵(变换矩阵)A,然后将预测到的位置裁剪出来,再计算相关性,将这个相关性的信息融入到一个生成网络中,希望通过生成网络去重构出GT,也相当于再一定程度上训练到了pixel级别的两两对应关系。其损失依然是采用了MSE loss的形式。
由于这两个任务是cascade,所以在迭代的过程中两个任务也起到了相互促进的作用,一方想往好的方向发展势必要求另一个任务往好的方向去靠近。
五、Unsupervised Deep Tracking
作者:Ning Wang, Yibing Song, Chao Ma, et al
Paper:https://arxiv.org/pdf/1904.01828.pdf
1、摘要
本文提出了一种无监督的视觉跟踪方法。与现有的使用广泛的注释数据进行监督学习的方法不同,我们的CNN模型是以无监督的方式在大规模的无标记视频上进行训练的。我们的动机是,一个鲁棒的跟踪器在正向和向后的预测中都应该是有效的(即,跟踪器可以在连续的帧中向前定位目标对象,并回溯到其在第一帧中的初始位置)。我们在暹罗相关滤波器网络上建立了我们的框架,该网络使用未标记的原始视频进行训练。同时,我们提出了一种多帧验证方法和一种成本敏感的损失,以促进无监督学习。在没有任何花里胡哨的技巧的情况下,所提出的无监督跟踪器达到了完全监督跟踪器的精度。此外,无监督框架可以利用未标记或弱标记数据来进一步提高跟踪精度方面的潜力。
🔺 这个文章和上述第三篇文章的做法和出发点都很相似,都是用一个SOT的网络去tracking,然后跟回自己的这张图去做监督。
2、方法
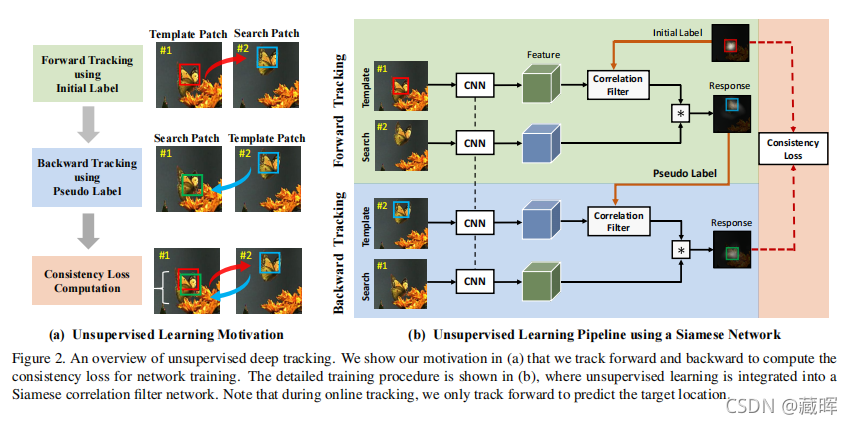
从框架上看也和之前的方法比较相似,损失也是去构建一个pixel级的损失,不同的是引入了一个Anorm来做一个损失调节权值,用于弱化在训练过程中,有噪声、背景或静止目标的无信息的图像补丁对模型的影响。
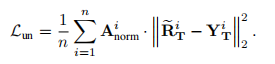
六、Space-time correspondence as a contrastive random walk
作者:Allan Jabri, Andrew Owens, and Alexei A Efros
Paper:https://arxiv.org/abs/2006.14613
1、摘要
本文提出了一种简单的自监督方法来学习从原始视频的视觉对应的表示。我们将对应关系转换为由视频构建的时空图中的链接的预测。在这个图中,节点是从每一帧采样的补丁,在时间上相邻的节点可以共享一条有向边。我们学习了一种表示,其中成对相似性定义了一个随机行走的转移概率,因此长距离对应被计算为沿着图的行走。我们将优化目标表示为包装沿路径都是高概率的。学习目标是在没有监督的情况下形成的,通过周期一致性:其目的是在沿着由帧回文构造的图行走时,最大限度地提高返回到初始节点的可能性。因此,一个单一的路径级约束隐式地监督中间比较的链。当作为不适应的相似度量时,学习到的表示在涉及对象、语义部分和姿态的标签传播任务方面优于自我监督的最先进技术。此外,我们还证明了一种我们称之为边缘辍学的技术,以及在测试时的自我监督自适应,进一步改善了以对象为中心的对应关系的传输。
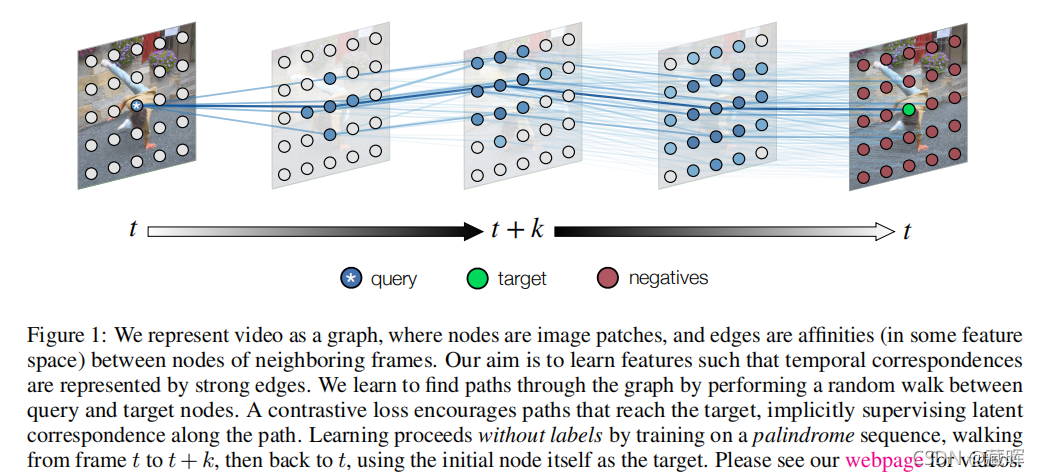
🔺于之前的方法用SOT来做匹配不同,这个思路直接监督到了一张图片上的所有pixel。虽然也是用了cycle的思路,但是是通过优化图上的通路的最大概率,于之前的做法也有所不同。
2、方法
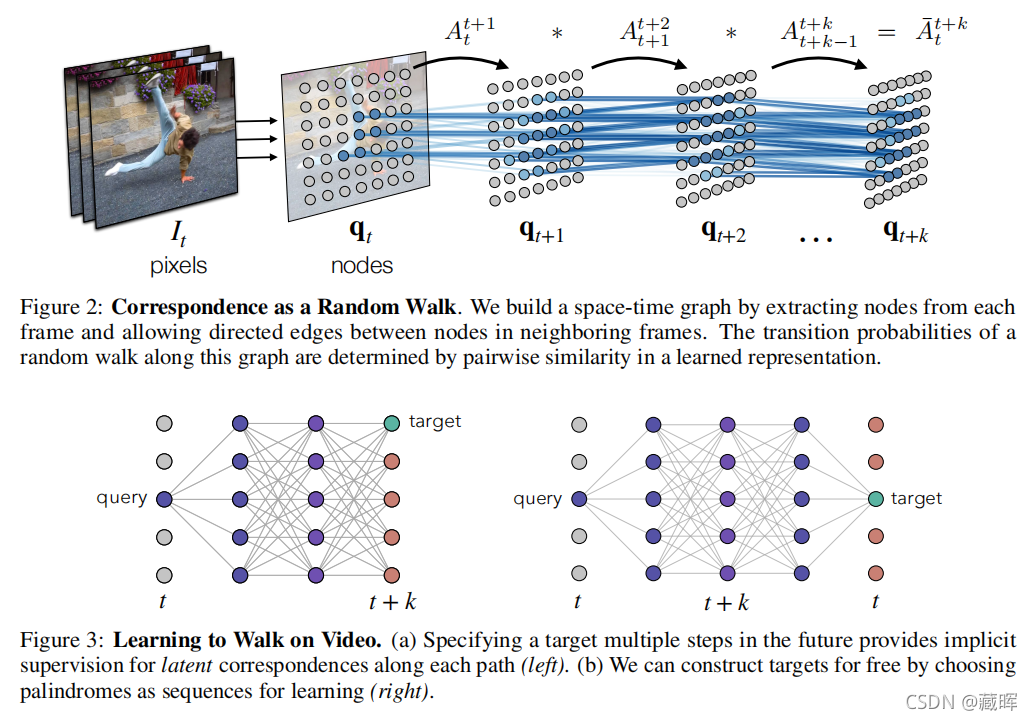
这是个很稠密的连接,通过统计每一个点和之前点之间的关系,用这个相似性表示点i到点j的概率。整个图的亲和矩阵将视频中的所有节点作为一个马尔可夫链关联起来,是块稀疏的,由局部亲和矩阵组成。
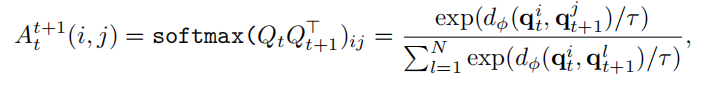
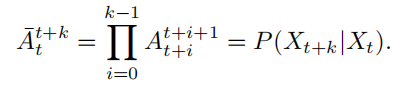
损失用的交叉熵损失,计算出发点为初始位置,并回到该位置的最大概率,使其最大。

🔺其实上在传播的过程中,该方法不关心路径是怎么样的,只关心最后能不能关联回原点。为什么这样的建模可以学习到相似性特征表达,中间的隐式链接能力是怎么建成的?作者说这个可以解释为具有潜在观点的对比性学习(Contrastive Learning)。这个问题可以理解为在特征空间上结构相似或者特征相似的一些目标总会聚合在一起。
测试的过程基本上和之前的方法相同,通过变换矩阵做逐帧的传播,在实验部分作者提到该方法也可以在测试的过程中利用新的数据进一步提高性能。















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









