









第三阶段(2012年~至今 ,基于相关滤波的跟踪算法提出,及深度学习的应用)
1、相关滤波
MOOSE(ICCV 2010)是目标跟踪领域第一篇相关滤波算法,采用单通道灰度特征,在训练和检测时都没有加padding,速度:615FPS,第一次显示了相关滤波的潜力。
CSK(与KCF/DCF同一作者)在MOSSE的基础上扩展了密集采样(加padding)和kernel-trick,速度:362FPS。
KCF/DCF在CSK基础上扩展了多道通的HOG特征,速度:KCF–172FPS,DCF–292FPS。
CN(Martin Danelljan大神–林雪平大学)在CSK的基础上扩展了多通道颜色的Color Names,速度:152FPS。
1)MOSSE
相关滤波的跟踪算法始于2010年David SBolme提出的MOSSE方法,其方法利用了信号处理中的相关性,通过提取目标特征来训练相关滤波器,对下一帧的输入图像进行滤波,不难发现,当两个信号越相似,即后一帧中图像的某个位置的目标与前一帧用于训练的特征越相似,在该位置滤波器所计算得到的相关值越高,相关性计算如下图,g为计算的相关值,f为输入图像,h为滤波器模板。
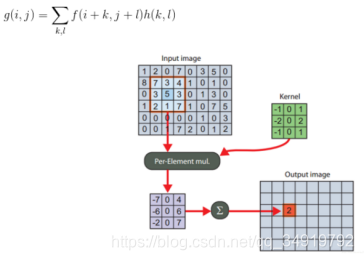
作者在文中提及为了减少计算量,加快相应,通过快速傅里叶变化(FFT)将卷积操作变成了点乘操作。那剩下的问题在于怎么在每一帧之后更新相关滤波器呢?
由于考虑到了外观变化等情况,并不单能从前一帧图像去考虑相关滤波器,而需要同时考虑前面的多个图像,相加最小。
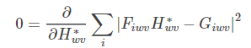
求导得:
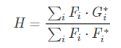
考虑光照等,作者也加入了权值滤波计算:
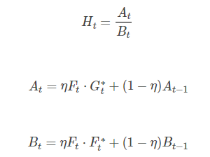
MOOSE的工作流程:
1、先手动或条件给定第一帧目标区域,提取特征,训练相关滤波器。
2、对下一帧输入图像裁剪下预测区域,进行特征提取,做FFT运算,与相关滤波器相乘后将结果做IFFT运算,得到输出的相应点,其中最大响应点为该帧目标的位置。
3、将该帧的目标区域加入训练样本中,对相关滤波器进行更新。
4、重复步骤2、3,即可实现目标跟踪。
2)CSK
CSK在MOSSE的基础上扩展了密集采样(加padding)和kernel-trick。密集采样通过循环矩阵似的图片向量移位,在不增加过多内存的基础上增加样本数。而用核技巧可以在低维空间完成高维空间的计算,避免维度灾难。
CSK用一个线性分类器来求解相关滤波。
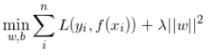
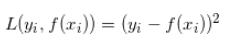
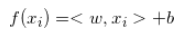
与之前的方法的最大不同是加入了正则项,为了防止求得的滤波器过拟合。那如何求解呢?CSK算法使用核技巧是为了提高在高维特征空间中分类样本的速度。
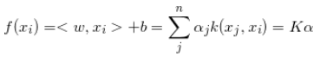
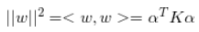
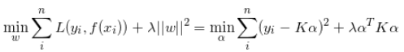
建议目标函数,求导,计算最小值,可以得到:
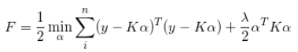
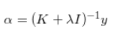
循环矩阵和稠密采样都是为了求滤波器w,换言之就是为了求α,理想响应y是已知的,所以求出K即可。
稠密采样是通过构建循环矩阵实现稠密采样,x为输入图像,为一个nx1的向量,P表示循环移位操作,每次移动一个元素。
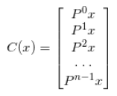
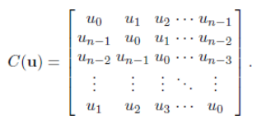
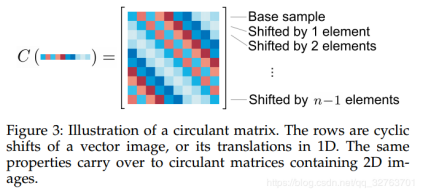
第一行为实际采集的目标特征,其他行表示周期性地把最后的矢量依次往前移产生的虚拟目标特征。因为整个循环矩阵都是由n×1向量演变而来,所以循环矩阵不需要空间专门去保存它。这样的好处是增加了样本的数量,使得训练的结果更为准确。

3)KCF/DCF
KCF全称为Kernel Correlation Filter 核相关滤波算法。是在2014年由Joao F. Henriques, Rui Caseiro, Pedro Martins, and Jorge Batista提出来的,算法出来之后也算是轰动一时。
KCF在CSK的基础上拓展了HOG特征,替代原有的特征能取得更好的效果。HOG特征也是运用的比较广的一个特征,简单来说是对输入图片进行分块,分成最小单位cell后计算一个cell水平梯度和竖直梯度,并将ixi个cell组成一个block进行归一化,这样做我们可以忽略平面内部一些大块非边缘信息,也可以减少光照的影响。HOG特征的好处在于它用的是像素与像素之间的向量来作为特征,这个意味着全局光照的亮暗对其影响有限,鲁棒性强,HOG对局部纹理的敏感性更强。

KCF和DCF是在特征上采用了多通道,而两者的不同在于采用不同核函数,用Gauss核函数叫KCF,采用linear kernel时叫DCF,其中DCF由于采用的linear-kernel,所以multi-channel合并时有优势,速度比KCF快,效果差一点点。

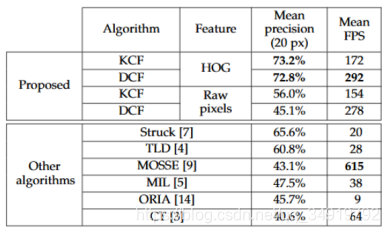
至今对于DCF这个模型为基础仍有很多学者进行研究改进,如SRDCF在其基础上解决了多尺度问题和加入惩罚项。
4)CN
CN是在CSK的基础上拓展多通道颜色特征,其方法是将RGB的3通道图像投影到11个颜色通道,分别对应英语中常用的语言颜色分类,分别是black,blue, brown, grey, green, orange, pink, purple, red, white, yellow(对比汉语中常用的语言颜色分类:赤橙黄绿青蓝紫+黑白灰,英语和汉语对颜色的认知还是略有差异的),并归一化得到10通道颜色特征。作者还测试了多种颜色特征在相关滤波中的效果,发现CN最好,其次是LAB;
5)DSST
DSST算法也是基于KCF算法改的较好的一种。DSST(Accurate Scale Estimation for RobustVisual Tracking)是2015年BMVC(InProceedings of the British Machine Vision Conference)上的文章,并在2014VOT比赛中夺得了第一名,算法简洁,性能优良,可移植性高。之篇文章是基于MOSSE,KCF基础上的改进,主要有两个方面:(1)引入多特征融合机制,这个和SAMF算法一样,使用的特征为HOG+CN+灰度特征;(2)文中最大的创新点是对于尺度的改进。
DSST的最大改进在于通过取图像金字塔,增加了一个尺度滤波器,其计算过程如下:
1、和KCF一样,用一个相关滤波器进行跟踪,得到目标的位置;
2、在目标的基础上通过调整跟踪框的比例,通过图像金字塔,从不同的尺寸去检测,寻找响应值最大的尺度,从而实现尺度自适应。
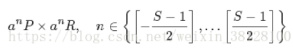
其中,P,R分别为目标在前一帧的宽高,a=1.02为尺度因子,S=33为尺度的数量。上述尺度不是线性关系,而是由精到粗(从内到外的方向)的检测过程。
小结
相关滤波的出现在目标跟踪领域引起了很长一段时间基本上统治了目标跟踪领域,虽然在2016年之后,相关滤波和深度学习的融合越来越多,但是其跟踪思想直至现在依然处于主流的地位。
2、基于深度学习的跟踪算法
1)MDNet
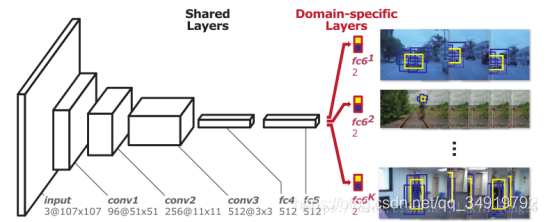
MDNet是2015年VOT的冠军,将深度学习引入目标跟踪,这篇文章的创新点是用深度学习抽取运动的特征,将运动特征添加到目标跟踪中,下图是MDNet的网络结构模型。
MDNet在视觉跟踪方面更有效的原因
1、网络较浅:视觉跟踪的任务是为了区分目标和背景两类,比一般的视觉识别问题具有更小的复杂度(ImageNet的分类任务需要区分1000类)
2、定位精确:深层的CNN不利于精确地目标定位,因为网络越深,空间信息往往会被稀释
3、目标较小:视觉跟踪中的目标往往较小,这就使得网络的输入图像尺寸变小,继而降低了网络的深度
4、速度较快:目标跟踪任务中较小的网络效果往往更好,训练和测试是在线进行的。
5、与相关滤波相比,正负样本是以经过卷积后的特征图保存的,可以节省空间,总正样本集为最近100次成功帧的正样本,而总负样本集为最近20次成功帧的负样本。
具体的网路结构和实验可以自行去看MDNet的论文,在这我们更加关心的是它如何实现目标追踪任务。
MDNet的跟踪过程:
1、根据上一帧的target bounding box 生成256个候选区域(如果是第一帧的话输入预训练好的CNN网络和第一帧的目标输入)
2、前向传播计算这256个候选区域的得分(conv1-FC6),挑选出计算目标得分最高的5个,对这5个候选区域取平均生成当前帧的target bounding box,并且计算这5个区域得分的平均值,与一个阈值(作者代码中提供的是0)比较,判断是否跟踪成功。若成功,则进行bounding box 微调;若跟踪不成功,首先扩大搜索区域(下一帧生成候选区域时用到),然后复制前一帧的结果为当前帧的结果。
3、跟踪成功时收集数据:根据当前帧预测的target bounding box 生成50个正样本区域(IOU>=0.7),生成200个负样本区域(IOU<=0.3),然后分别对这些样本区域进行前向传播,最后保存的是这些区域的conv3特征 【其中帧数超过100个则抛弃最早的那些帧的正样本区域,帧数个数若超过20个则抛弃最早的那些帧的负样本区域】
4、跟踪失败时进行网络的短期更新,选择最近的20帧的正样本和负样本(这些正样本和负样本都是以conv3特征进行保存),然后进行迭代训练15轮,迭代过程和步骤3相同(迭代更新的是fc4~fc6)
5、每10帧进行一次长期更新,选择最近100帧的正样本区域和最近20帧的负样本区域进行网络更新,然后迭代15轮,迭代过程和步骤3相同(迭代更新的是fc4~fc6)
值得一提fc6是一个二分类层(Domain-specific layers),一共有K个,对应K个Branches(即K个不同的视频),每次训练的时候只有对应该视频的fc6被使用,前面的层都是共享的。
2)TCNN
Modeling and Propagating CNNs in a Tree Structure for Visual Tracking(TCNN,CVPR2017)这篇论文是VOT2016的亚军,是由韩国POSTECH大学的Hyeonseob这个组做的,这个组之前提出了MDnet,CNN-SVM算法。
TCNN通过在树形结构中管理多个目标外观模型来呈现在线视觉跟踪算法。所提出的算法使用卷积神经网络(CNN)来表示目标外观,其中多个CNN协作以估计目标状态并确定树中在线模型更新的期望路径。通过在树形结构的不同分支中维护多个CNN,可以方便地处理目标外观中的多模态,并通过沿树路径的平滑更新来保持模型可靠性。由于多个CNN共享卷积层中的所有参数,因此通过节省存储空间和避免冗余网络评估,它利用了多个模型而几乎没有额外成本。
TCNN算法的原理:
1、这篇论文使用多个CNN用树形结构组合起来,一起对新的一帧进行目标检测,检测分数最高的proposal就是选中的target;
2、当一个新的帧进来时,根据上一帧的跟踪结果生成256个候选框,对每个候选框都使用目前的CNN树来计算自己的score,score最高的就是选中的target;
3、在在线跟踪过程中,每十帧添加一个新的CNN节点,并删除最前的一个节点,只保留最近的十个CNN节点,这样就做到了模型更新;
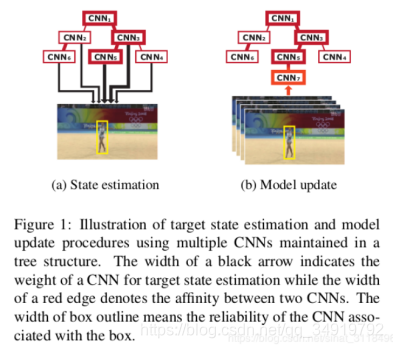
阅读完后,我对树结构是这样理解的,每个CNN实际上是一个CNN块,里面包含着3个conv和3个fc,每个CNN都有自行对输入图片输出前景和背景两个概率值的能力。而作者想用树形结构组合多个CNN,一起对新的一帧进行目标检测,取得分数最高的,这就在于如何训练使得这多个CNN有不同的评分能力,为了节约资源,文中提出CNN的conv3层是共享的,也就是说不同的只有全卷积层。
从论文中,发现其实不同的全卷积层对目标外观的姿态有不同的敏感性,举个例子,当一个人的正脸图和侧脸图同个全连接层可能会评分不同,但是却可以专门训练一个全连接层对该状态敏感。在跟踪时,虽然TCNN通过了10个CNN去求分数,由于每个CNN之间实时递归了关联性,只通过关联性高的路径求加权来执行目标估计,这样可以防止某个CNN出错带来的问题。然后再通过得到的所有加权估计比较最大值为该候选框的分数。
3)GOTURN
GOTURN算法采用了YCNN的结构,但是该算法无法控制下一帧的变换形式,不具有变换的内在不变性,除非样本集包含所有种类所有位置的变换。并且不能自适应调节搜索区域的大小。在GPU上,GOTURN可以达到100帧及以上的速度。
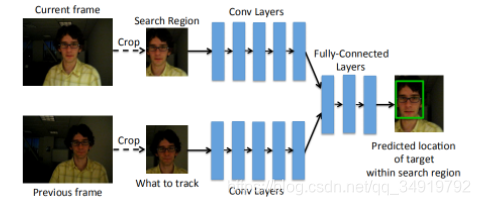
其实我们不难发现GOTURN的网络结构和SiamFC很像。
4)Deeper and Wider Siamese Networks for Real-Time Visual Tracking(CVPR,2019)
文章对影响跟踪精度的主干网络因素进行了系统的研究,为Siamese跟踪框架提供了一个架构设计的指导;基于文章提出的无填充残差单元,设计了一种新的用于Siamese跟踪的更深、更宽的网络架构。实验结果显示新的架构对基准跟踪算法确实有很明显的性能提升效果。
作者通过消融实验对加深Siamese的网络结构造成的性能下降进行定性定量的实验,总结了四个基本的设计指南:
1、即使网络深度增加也尽量不要增加步长,从经验上权衡准确率和效率的化,补偿选择4或者8;
2、应该根据其与样本图像大小的比例来设置输出特征的感受野,经验来看,有效比例为60%~80%,最大感受野不应该大于目标图像;
3、设计网络结构时应该综合考虑步长、感受野和输出特征图尺寸,如果改变一个,其他两个也需要相应改变,这样可以给Siamese框架提取更有区分度的特征;
4、对于全卷积Siamese网络,去掉填充操作是至关重要的。由其引起的位置偏差会影响Siamese跟踪器的精度和鲁棒性,尤其是目标快速移动或者在图像边界移动时。
为此,本文作者设计了一个CIR单元模块,可以通过该模块的堆叠获得更深、更宽的主干网络。
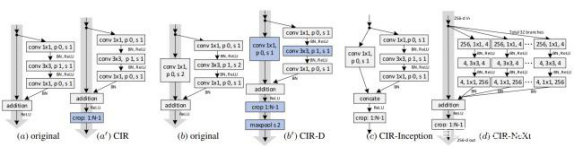
图中可以看到,基本的CIR单元,在残差单元的add后面加入了一个裁剪层,其目的在于将那些受到之前填充操作影响的地方都删除;下采样的CIR-D单元,为了消除填充的影响,作者在瓶颈层和短接层中将步长改为1,在add之后同样采用裁剪,最后再使用最大池化执行尺寸下采样;CIR-Inception和CIR-NeXt单元,将CIR单元通过多个特征变换扩宽而来,其他修改与CIR-D的修改差不多。
3、深度学习和相关滤波相结合
1)DeepSRDCF
DeepSRDCF在VOT2015中取得了第四名的成绩,它是在SRDCF的基础上进行改进的,速度为4fps。这也是深度学习和相关滤波的一次结合。虽然结合的方式和直接,作者发现CNN所提取的feature map的在解决跟踪的问题比传统方法所提取的特征好,而且在跟踪问题中,不需要太高的语义信息,浅层的特征在目标跟踪中的效果更好。为此DeepSRDCF与SPDCF的不同在于将原有的特征换成了CNN的特征。
2)C-COT
C-COT算法是DCF(KCF)算法的又一重要演进算法,该算法在VOT-16上取得了不错的成绩。C-COT使用深度神经网络VGG-net提取特征,通过立方插值,将不同分辨率的特征图插值到连续空间域,再应用Hessian矩阵可以求得亚像素精度的目标位置(就和SURF、SIFT里面获取亚像素精度特征点的思想类似)。确定插值方程之后,还解决了在连续空间域进行训练的问题。C-COT也是基于SRDCF的框架去改进的,最大不同在于将学习检测过程推广到连续空间域中,获得亚像素精度的位置。
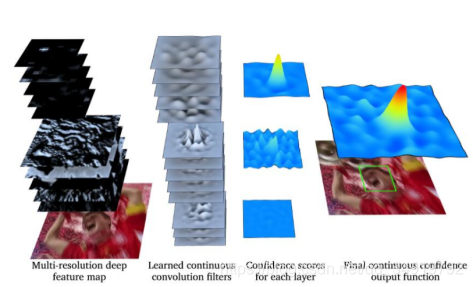

由于不同的卷积层能获得的信息意义不同,底层的特征更有利于确定精确的位置,越深层的特征包含语义信息。通过多分辨率的特征图,结合多分辨率的滤波器进行训练和检测,可以获得更加精确的位置和更好的鲁棒性。应用三次线性内插值进行目标位置亚像素精度的定位。
D-COT的由于采用了深度信息实际上测试速度很慢,也符合近几年的改进情况,以牺牲高效性来提高性能。
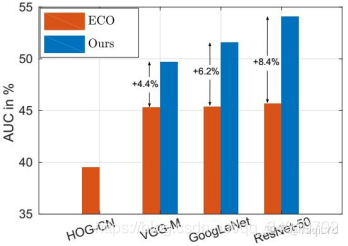
3)ECO(2017)
自MOOSE的提出之后,在相关滤波上有很多学者做了获得工作,但是随着特征维度越来越高,算法复杂性上升,跟踪效果虽然逐步提升,但是却以跟踪效率的牺牲作为代价。ECO算法(下一作)在C-COT的基础上将速度提升到了60fps,并且将样本分组解决过拟合问题,效果更好了。
为此ECO以提高时间效率和空间效率为出发点,分析了速度降低的三个重要的因素:
1、模型大小,更加复杂的特征的融合和应用,使得每一次更新模型的参数量越来越大,模型速度就下降了。而且增加维度却没有足够的样本数,容易引起过拟合。
2、训练集大小,将每一帧的目标作为新的样本加入到训练集之中,对相关滤波器进行更新,但是随着视频序列的增加,训练集中的样本数会越来越多,使得训练越来越慢。像传统方法是进来一帧我就丢弃最前面的一帧,如果后面的帧是错误的话,目标跟踪就会越跟越偏。
3、模型更新,模型更新是否需要对每一帧都进行更新。
针对以上三个问题,在ECO中进行了改进:
1、 Factorized Convolution Operator(因式分解的卷积操作)
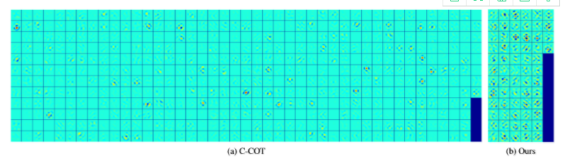
在C-COT中,作者对每一个特征图都对应一个滤波器,ECO在特征提取上做了简化。用了原来特征的子集,从D维的特征中选了其中的C维。C-COT是每个维度的特征对应一个滤波器,D维的特征就有D个滤波器,其实很多滤波器 的贡献很小。如图一所示,C-COT的大部分滤波器的能量很小。而ECO只选择其中贡献较多的C个滤波器,C<D,然后每一位特征用这C个滤波器的线性组合来表示。这里的C维如何选择文中没有具体说,我猜测是简单的利用滤波器中大于某个阈值的元素个数来选择。
新的检测函数为:
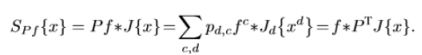
2、ECO简化了训练集
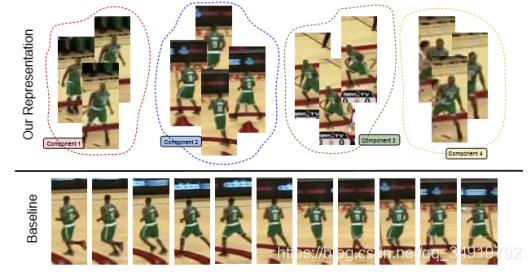
上图中下面一行是传统的训练集,每更新一帧就加一个进来,那么连续的数帧后训练集里面的样本都是高度相似的,即容易对最近的数帧样本过拟合。上面一行是ECO的做法,ECO用了高斯混合模型(GMM)来生成不同的component,每一个component基本就对应一组比较相似的样本,不同的component之间有较大的差异性。这样就使得训练集具有了多样性。
3、对样本更新每一帧都做,对模型更新只是每隔i帧做一次。
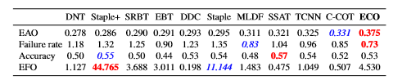
总结一下ECO效果好的原因:
- 特征全面(CNN, HOG, CN),这个对结果的贡献很高;
- 相关滤波器经过筛选更具代表性(2.1做的),防止过拟合;
- 训练样本具有多样性(2.2做的),减少冗余;
- 非每帧更新模型,防止模型漂移;
4)SiamFC
SiamFC的提出被很多人当成了破冰之作,打破了相关滤波在目标跟踪领域的垄断地位,可以说真正出现了一种可以和相关滤波相匹敌的目标追踪网络。
全卷积孪生网络作为基本的跟踪算法,这个网络在ILSVRC15的目标跟踪视频数据集上进行端到端的训练。我们的跟踪器在帧率上超过了实时性要求,尽管它非常简单,但在多个benchmark上达到最优的性能。
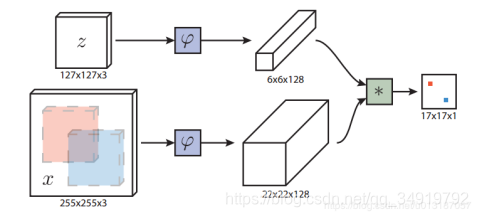
上图的∗表示的就是相关滤波,就是用一个FeatureMap卷积另一个Feature Map的操作。最后生成一张17x17的概率(score)分布表,概率最大的那个就是目标位置,映射会原图像就可以得到输出bbox。
全卷积网络的优点是待搜索图像不需要与样本图像具有相同尺寸,可以为网络提供更大的搜索图像作为输入,然后在密集网格上计算所有平移窗口的相似度。本文的相似度函数使用互相关,公式如下
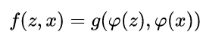
本文提出了一种全卷积的Siamese网络,称为SiamFC。全卷积的结构可以直接将模板图像与大块的候选区域进行匹配,全卷积网络最后的输出就为我们需要的响应图。在响应图中寻找响应值最高的一点,该点在候选区域中的对应部分,就是预测的目标位置。也可以用感受野来理解,上图中输出的小红点和小蓝点,对应在输入层的感受野就是输入图像x中的红色区域和蓝色区域。
5)Siamese Net大爆发(2018,SiamRPN, SA-Siam-R)
上文所说的Siamese FC存在一些问题:bbox需要回归,需要多尺度测试,效率低;由于采用模板,提取的数据为首帧较为单一,单有两个人重叠时bbox框容易跑到其他人身上去。
而Siamese RPN的提出是将网络后的FC换成了RPN,网络结构如下:
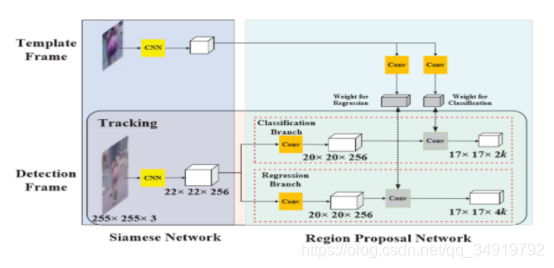
RPN相关的知识可以通过阅读Faster R-CNN来了解,这里不再多说明。
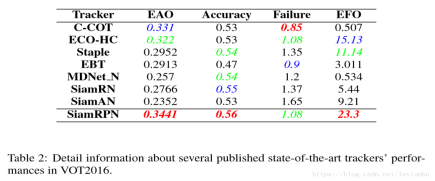
一开始我比较好奇的是为什么SiamRPN比SiamFC的EFO要高那么多,通过总结的是因为RPN的应用,不需要进行多尺度的测试了,可以直接进行位置、大小的回归,因此提高了算法的跟踪速度。
SA-Siam由语义分支和外观分支组成,每一个分支都是一个相似性学习孪生网络。作者分别训练了这两个分支来保持两种类型特征的异质性,也就是让两种特征不一样。此外,作者在语义分支上加入了通道注意力机制,这个东东是干啥的,它可以根据目标位置周围的信息激活来计算通道权重,不同的跟踪目标有不同的通道权重。同时SiamFC的固有结构可以让跟踪器保持实时性,两个孪生网络和注意力机制的设计可以大大的提高跟踪性能。
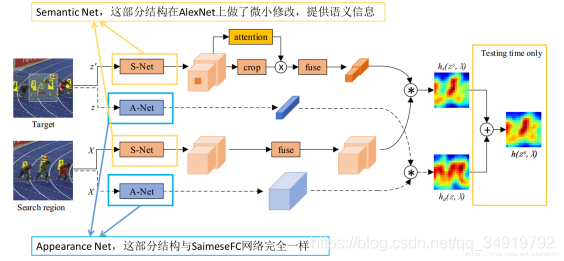
这个分支的训练方法与Appearance branch类似。
testing阶段,这个分支也会得到一个响应图,这个响应图会与Appearance branch的响应图求加权平均,得到最终响应图。经过实验,论文给出的加权系数为0.3,即0.3A+0.7S。
有几个点需要注意:
(1)S-Net直接使用预训练好的AlexNet参数,不用再训练;
(2)两路输入均包含了背景。groundtruth分支输入以真实目标为中心的与搜索区域等尺寸的区域图像,而不仅仅输入真实目标图像,是为了使用更多的背景信息,这对attention结构是有用的;
(3)使用了conv4和conv5层特征。两层特征融合,已经证明对跟踪精度有好处,因为高层特征关注语义,而低层特征保有更精确的位置信息,二者可以互补;
(4)有一个attention结构。attention结构提供特征的channel-wise权重,参数需要学习;
(5)有一个fuse结构。fuse结构可以看作是特征融合,参数需要学习。
其中的attention结构:
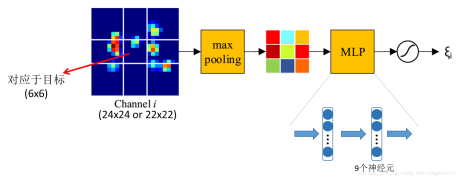
在此结构中,特征的各通道权重分别计算,其中conv4层特征空间分辨率为24x24,conv5层则为22x22。对每个特征通道,按上图方法划分成9格(9个格子尺寸不等),然后执行最大池化,得到9维特征,经过MLP(多层感知机)和一个sigmoid函数,最后得到该通道权值。
fuse结构较简单:是1x1的ConvNet,对conv4和conv5特征分别做fusion,得到总共256个通道的特征(其中conv4和conv5特征各有128个通道)。
6)SiamMask(CVPR,2019)
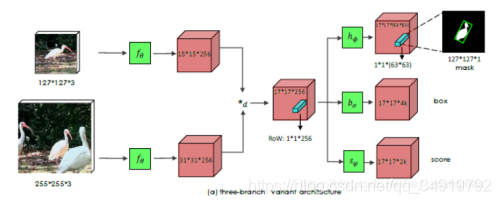
SiamMask同样是基于孪生网络,和SiamFC不同的是,这里的*d是depth-wise的cross correlation操作,也就是说这里是对逐通道进行相关性计算,所以得到的响应保持了通道数不变(这里是256)。文章把中间的这个响应称为RoW(response of candidate window),而后在这个RoW的基础上分出了三个分支,分别进行分割,回归和分类。
利用mask生成
(1)axis-aligned bounding rectangle (Min-max):根据mask的最小最大x、y坐标值生成坐标轴对齐的bounding box,易知,这种方法生成的框是正的,如上图中的红框。
(2)rotated minimum bounding rectangle (MBR):根据mask计算最小外接矩形作为bounding box,这种方式生成的框可以是歪的,如上图中的绿框。
(3)Opt:最优的方法。这个最优的策略是在VOT-2016的挑战中被提出来的,(这个方法我没有去研究),生成的框也可以是歪的,如上图中的蓝框。
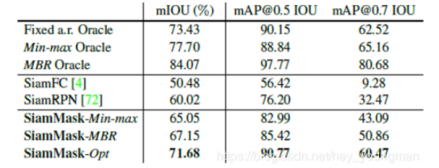
这个实验比较有意思,是在VOT-2016数据集上做的,其标注是带有旋转角度的bounding box。实验是为了对比SiamFC、SiamRPN、SiamMask三个网络的表现,并且找到这三者在这个数据集上的上限。第一大栏的三行分别表示再给出ground truth的基础上,用固定比例的框、按照gt的边缘生成和坐标轴平行的框以及用gt的最小外接框这三种方式预测能够得到的最好结果。也就分别对应了SiamFC、SiamRPN以及SiamMask三种方法能够达到的上界。下面两大行就是这几个网络实验结果的对比了,SiamMask明显好于其他两者。
7)UPDT(2018,DCF+CNN)
在ECO提出后的很长一段时间,在相关滤波方向都是基于ECO和C-COT来进行改进的,并没有什么实质性的进展,没有性能能全面超过ECO的论文。在ECO中,深度特征的性能并没有发挥出来,
UPDT对ECO的核心改进是两种特征区别对待,分而治之,深度特征负责鲁棒性,浅层特征负责准确性,两种检测响应图在最后阶段自适应融合,目标定位最优化,兼具两者的优势。
在ECO中,深度特征和浅层特征的高斯标签函数相同,UPDT提出要区别对待,实验结果如上图(b),深度特征标准差1/4最好,浅层特征标准差1/16最好。通过标签函数增加的正样本等价于平移数据增强,所以论文解释是:深度特征对小平移的不变性,同上从增加的正样本获益,深度特征更应该关注鲁棒性;小平移会使feature map差异巨大,tracker无法处理大量有差异的正样本,浅层特征更应该关注准确性。将深层特征和浅层特征加权融合。
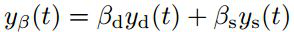
这是在VOT2017的实验效果

UPDT从研究deep tracker为什么无法从更好更深的CNN获益这一问题开始,研究发现深度特征和浅层特征表现出截然不同的特性,先分后合的处理方法:
分,区别对待,深度特征负责鲁棒性,浅层特征负责准确性,数据增强和宽标签函数对深度特征提升巨大。
合,自适应融合,提出质量评估方法,以最大化融合质量为目标函数,最优化方法同时获得深度特征的鲁棒性和浅层特征的准确性。
参考连接
C-COT参考:http://www.p-chao.com/2017-04-20/图像��%9
F%E8%B8%AA%EF%BC%88%E5%8D%81%EF%BC%89c-cot%E7%AE%97%E6%B3%95%EF%BC%9A%E8%BF%9E%E7%BB%AD%E7%A9%BA%E9%97%B4%E5%9F%9F%E7%9A%84%E5%8D%B7%E7%A7%AF%E6%93%8D%E4%BD%9C/
ECO参考:https://blog.csdn.net/zixiximm/article/details/54378397
SiamFC 参考:https://blog.csdn.net/nightmare_dimple/article/details/74210
147
SiamRPN参考:https://blog.csdn.net/leviopku/article/details/81068487
SA-Siam参考:https://blog.csdn.net/fzp95/article/details/81028039
SiamMask参考:https://blog.csdn.net/hey_youngman/article/details/88751952
UPDT参考:https://zhuanlan.zhihu.com/p/36463844
MDNet参考连接:https://blog.csdn.net/Zfq740695564/article/details/79598559
TCNN参考连接:https://blog.csdn.net/sinat_31184961/article/details/84023617
相关滤波、KCF参考:https://blog.csdn.net/sgfmby1994/article/details/68490903
MOSSE参考:https://blog.csdn.net/qq_17783559/article/details/82254996
HOG参考:https://blog.csdn.net/wjb820728252/article/details/78395092
DSST参考:https://blog.csdn.net/weixin_38128100/article/details/80557460

















 1064
1064

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









