







 本文介绍了作者如何利用简单的爬虫技术,通过分析B站网页源代码,使用正则表达式抓取视频链接。作者强调这是对爬虫基础知识的复习,并分享了11行代码实现的爬虫程序。
本文介绍了作者如何利用简单的爬虫技术,通过分析B站网页源代码,使用正则表达式抓取视频链接。作者强调这是对爬虫基础知识的复习,并分享了11行代码实现的爬虫程序。
因为去年看过机器学习 Andrew Ng的课程,今天想找来重看一下,发现当没有中文字幕, 啊?? 难当我去年看的就是不带字幕的英文版??
他讲的有一些算法的推导,我认为讲的还是比较好理解的,但是不看中文字幕,推导起来还是有些吃力,找了半天终于找到一个连接,竟然在哔哩哔哩上。
因为之前学了一点爬虫,爬过哔哩哔哩的弹幕,所以今天想把这些视频也爬下来。
我也是上个星期才接触爬虫,只会一些简单的的。今天就把这个最简单的贴出来,也算是对前几天做一下复习吧。
首先我们分析一下哔哩哔哩网址
右键 查看网页源代码 如下图
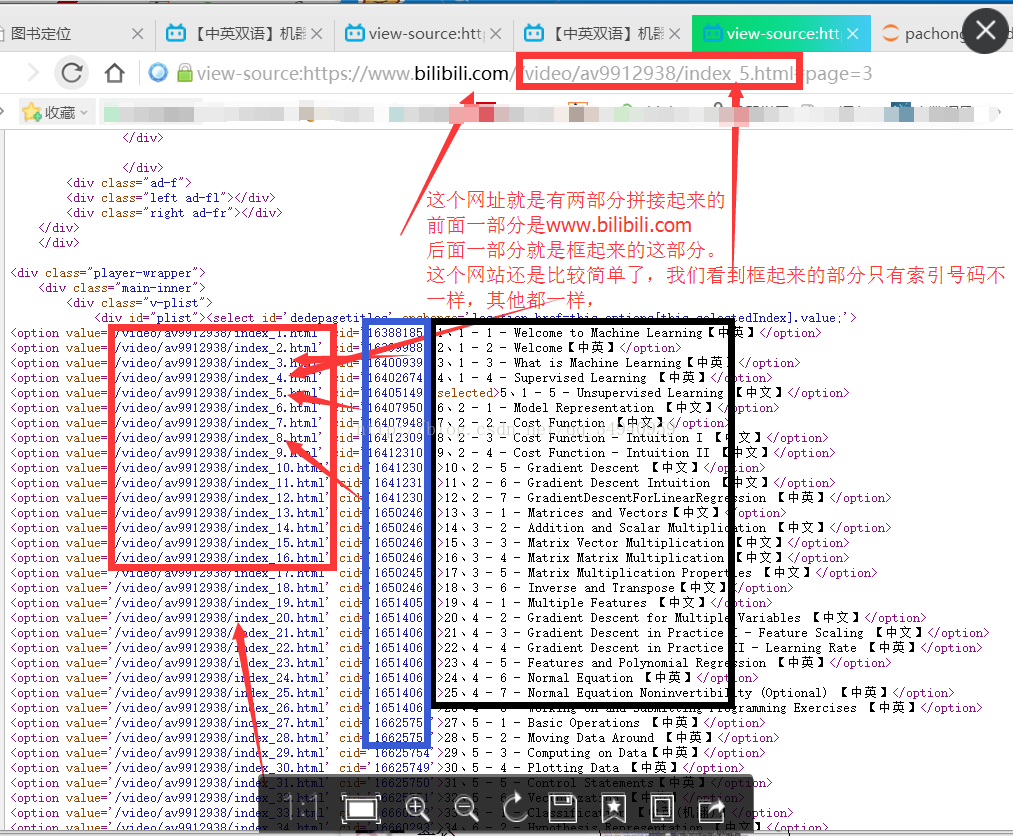
这里直接把框起来的用正则表达式匹配一下 然后提取出来。 当然,如果只想要前面红框的部分,可以用for循环ÿ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 702
702

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









