






MYSQL初步认识
一: 在理解mysql之前我们先来看一点有趣的东西
计算机的最小信息单位是什么?是byte,例如010100,计算机的存储部件是什么?固态硬盘,机械硬盘
机械硬盘怎么存储数据的?磁信号与电信号的转换,
机械硬盘的结构?

1:磁盘转动的时候,磁头会在磁盘上留下圆弧轨迹,称为磁道,两个磁道之间的环形会被为若干份,其中一份称为扇区
重要的情报:物理扇区是机械硬盘处理的最小存储单位
2:我们可以想到磁盘最外围住的扇区是会比里面的扇区面积更大,所以以前的硬盘中心区域的磁密度更高,是为了让每一个扇区有相同的春储量,但现在整个磁盘的磁密度是一样的,为了追求更高的储存,有的硬盘会提高扇区的存储能力,2048,4096等,这种物理层面的扇区我们称为物理扇区,这样的扇区对计算机去使用硬盘会有兼容问题,于是提出了一个逻辑扇区的概念,逻辑扇区定义一个扇区的储存内容为512字节,由此计算机程序将“无感”物理扇区
重要的情报:
逻辑扇区:是硬盘层面的最小单位
3:但逻辑扇区的容量太小,数据量大的时候将会进行多次寻址,会影响计算机性能,所以提出了 块/簇的概念。每一个 块/簇 可以是2的n次方个逻辑扇区
使用一下命令可以查看你的计算机,块的大小--每群集字节数
Windows:(使用管理员命令提示行)
fsutil fsinfo ntfsinfo E:
Linux:
stat /home | grep "IO Block"
重要的情报: 块/簇 是操作系统最小的存储单位
4:计算机中内存是直接使用数据的地方,当我们需要使用数据的时候,内存会和磁盘进行通信,他们的通信伴随着信息的传递,而这个信息的单位是–页,
重要的情报总结:
扇区:硬盘处理信息的最小单位(512字节)
块/簇:操作系统处理硬盘信息的最小单位
页:内存与操作系统通信的最小存储单位
二:MYSQL的 InnoDB的存储
1:页(page)是InnoDB的最小信息存储单元,每一次从数据库查询出来的数据都是已页为单位,每一个页的大小为16kb,
2:InnoDB表由:
共享表空间、日志文件组(更准确地说,应该是Redo文件组)、表结构定义文件组成
若将innodb_file_per_table设置为on,则每个表将独立地产生一个表空间文件,以ibd结尾,数据、索引、表的内部数据字典信息都将保存在这个单独的表空间文件
3: InnoDB存储引擎的逻辑存储结构:表

4:段: 表空间是由各个段组成的,常见的段有数据段、索引段、回滚段等
5:区: 一个区是由64个连续的页组成的,每个页大小为16KB,即每个区的大小为1MB 对于大的数据段,InnoDB存储引擎最多每次可以申请4个区,以此来保证数据的顺序性能。
6:页: 每个页大小为16KB,页是InnoDB磁盘管理的最小单位,整页整页的读取
数据页(BTreeNode)
Undo页(undo Log page)
系统页(System page)
事务数据页(Transaction SystemPage)

7:页数据是一个双向链表结构,它是B+树的最底层(叶子节点集合)
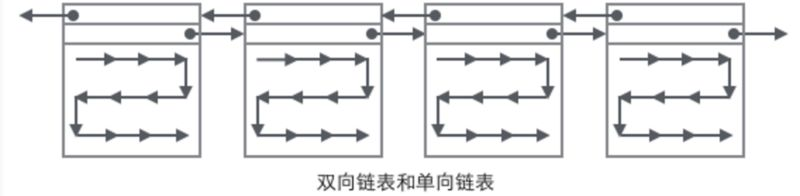
8:B+树:InnoDB的索引结构是b+树,b树与b+树的一个最大区别就是,b树的所有节点都是保存数据的节点,遍历所有节点可以得到所有数据,而b+树的所有数据是所有的叶子节点,非叶子节点只作为索引。
9:为什么b+树比b树更适合做索引,b+树更适合做索引的原因是他的数据是所有叶子节点合集,并且他们是双向链表结构,这个是一个无比有利的。第一因为主键索引的原因,我们大概率可以认为数据在某个维度上看是有序的存储,在连续的磁盘空间,也就是说b+树做到了尽可能的物理存储有序性。这对于查找将提供太多的优势。而b树的所有数据,即是整棵树,如果需要遍历,那就是需要递归一个树。
10:mysql的B+树是多少阶的:
目前我并没有看到什么资料上明确说明mysql的b+树是多少阶的,但好像有这样的说法,一个页的大小是16k,叶子节点用来存数据,非叶子节点的话就用来存索引列,除去page的首尾, 在UserRecord中能存多少索引列那他就是多少阶的树,以下是个人猜测估计的算法
假设mysql的主键是
int类型4字节:16kb/4=4096
bigint类型:16kb/8=2048
varchar(255):16kb/255=64
如果以上为真,那在希望b+树的阶数不高的情况下,应尽量减少作为主键的字节长度
11:从一次简单查询来看:select * from table where id=“”
从InnoDB的b+树上来看,会通过id从b+树上找到叶子节点。并返回数据。但这里我想问,这一次查询在硬盘上有多少次io呢,如果我们只看mysql内部的磁盘操作的话,不关心操作系统与内存之间的交互,数据进入b+树后,根节点并不算一次io,通常情况下b+树的高度会是2或者3,在查到第一个非叶子节点后,会根据指针进行再一次寻址,知道找到叶子节点,并遍历查找到数据。
12:寻址方法
1:chs:在早期的寻址方法我们是比较容易理解的,逻辑扇区–>到物理扇区,这个应该是操作系统,或者硬盘驱动帮我们解决的问题,所以我们只关心物理扇区,所以,如果我们给磁头,磁面,磁道,扇区,进行编号,我们将精确找到我们需要的扇区
2:LBA,逻辑寻址后期的磁盘因为磁信号是均匀的,外圈扇区多 内圈扇区少,3D寻址的难度加大了,并且因为LBA寻址能寻到的数据容量上限是8.4g,大容量磁盘产生出现了新的寻址方法,将3D参数合并成一个编码,里面的逻辑思路我现在不知道,然后直接根据这个编码在磁盘里找到对应的扇区
13:索引:
1:聚集索引:即是b+树的数据体
如果定义了主键,InnoDB会自动使用主键来创建聚集索引。如果没有定义主键,InnoDB会选择一个唯一的非空索引代替主键。如果没有唯一的非空索引,InnoDB会隐式定义一个主键来作为聚集索引
2:辅助索引
辅助索引也是一个b+树,定位主键,再通过聚集索引找到数据,使用场景的话,例如如果学生表id是主键,但我只知道学生姓名,这样的查询就是辅助索引的用途,它相比会聚集索引会更多一些b+ 树上的io
3:覆盖索引
辅助索引上已经可以得到需要查询的数,不必再回表查询,这样的查询称为覆盖索引
4:联合索引
多条辅助索引,index_id,index_name,可以合并为index_id_name. 效果是一样的,在索引中先以id为顺序,在id相同的情况下,以name为顺序,但需要记住一些情况可能会导致索引失效
14:索引失效
1:index_id_name_age,where(id,name,age),不失效,where(id,name,)where(id,age)不失效 where(name,age)失效
2:最左元素条件like 以%开头会失效,因为这样将无法使用辅助索引中关键元素的排序性,
3:where 中有or
4:类型使用错误,类型是字符串,但是没有加引号。如果本身是数字类型,加了引号,确是可以使用到索引的(隐式类型转换 )
5:索引列使用了函数
6:对索引列进行运算
15:Explain:执行计划
















 1442
1442











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









