







 超级会员免费看
超级会员免费看
爬虫技术是一门看似简单却可以很深入的技术,甚至在测试工作中也可用到。例如,Google、百度等公司的搜索引擎就是使用大规模分布式爬虫技术来采集网页和收录网站的,我们的搜索结果都是从爬虫爬取的数据中检索出来的。
1、爬虫测试简介
爬虫技术也可以用于测试,例如通过爬虫对测试页面进行采集和分析,对功能点进行冒烟测试。网络爬虫可以爬取Web站点的内容,对爬虫爬取的对应接口添加断言,便可进行自动化测试。通过循环不同的URL来抓取多个页面,便可将结果持久化以便进一步分析。
1. 爬虫测试的思路和流程
爬虫测试的核心在于爬虫,其流程大致如图所示。
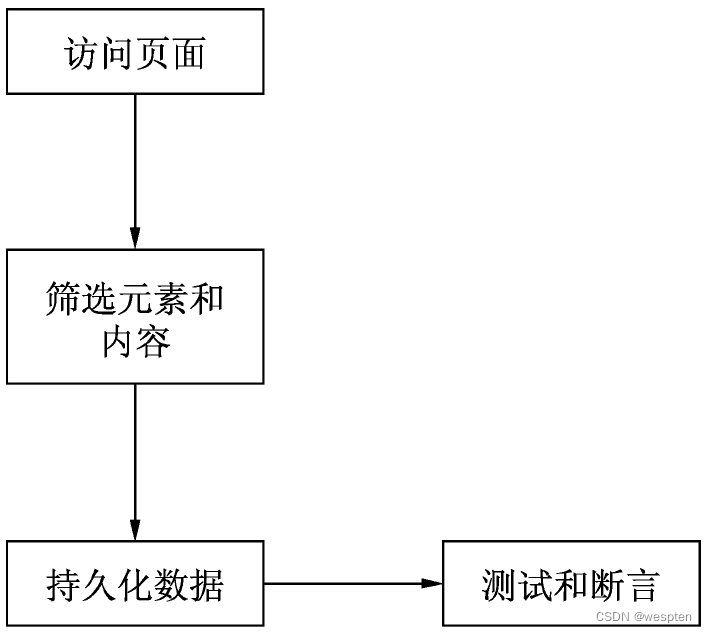
(1)访问页面。可以使用requests库进行GET或者POST请求,访问页面资源。
(2)筛选元素和内容。针对返回的页面数据进行元素定位,可以使用BeautySoap 4或者正则匹配方式匹配出特定元素。例如,针对股票详情页收集该股票的开盘价、收盘价和量比等数据。
(3)持久化数据。根据收集到的数据,选择适合的持久化手段,如写入本地文件,或者使用关系型数据库写入相关表。持久化有利于后续的分析工作,使结果可视化有了数据基础。
(4)测试和断言。使用断言来判断爬取到的数据是否和预期的一致。根据断言结果来判断测试是否通过,以此发现功能缺陷和存在的逻辑问题。
以上步骤中的第(1)步可能遇到的问题是反爬虫策略。网站会对这种固定IP和浏览器信息高频访问某一页面的行为产生警

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











