







链表
- 线性链表(单链表)
- 循环链表
- 双向链表
线性链表(单链表)

插入
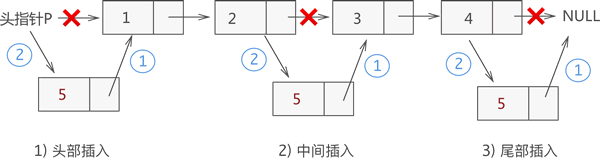
node2.next == node3 || node2->next == node3
# 插入过程
node5.next = node3 = node2.next
node2.next = node5
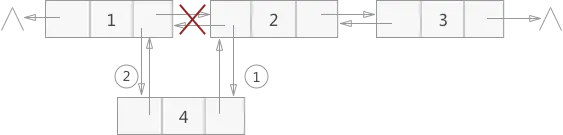
删除

temp == node2 || node2.next == node3
# 删除过程
# 写法1:
node2.next = node4
# 写法2:
node3 == node2.next && temp == node2
temp.next == node3 || node2.next == node3
node3.next = node4 || node2.next.next == node4 || temp.next.next == node4
||temp->next->next == node4
temp.next = temp.next.next
temp->next = temp->next->next
循环链表
其实就是把单链表的最后一个结点的next从null改为了头结点地址

双向链表
就是将原本单链表中一个结点只知道后续结点的地址,改为,一个结点既知道其后续结点的地址,也知道其前趋结点的地址。

插入
# 插入过程
temp == node1 || temp.next == node2 || temp.prior == NULL
node2.prior == node1 || temp.next.prior == temp == node1
# 先后再前
node4.next = node2 || node4.next = temp.next
node2.prior = node4 || temp.next.prior = node4
node4.prior = temp = node1
temp.next = node4
栈和队列
- 栈
- 队列
栈
只能从栈顶进行插入和删除,遵循先进后出(FILO)原则

# 入栈 push
stack = [] || top == -1
top++ stack.append(a) || top++ stack[top] = a || stack[++top]
# 出栈 pop
stack.remove(a) top--|| top-- || --top || stack.pop() == stack.pop(-1) || stack = stack[:-1]
队列
只能从队尾(rear)进行插入,只能从队首(front)进行删除。遵循先进先出(FIFO)原则

# 判断队空
front == rear
# 入队
que = np.array(4, dtype = np.char)
front = rear = 0
que[rear++] = 'A' # front == 0 rear == 1
que[rear++] = 'B' # front == 0 rear == 2
que[rear++] = 'C' # front == 0 rear == 3
# 出队
que[front++] = '' # 出A front == 1 rear == 3
que[front++] = '' # 出B front == 2 rear == 3
que[front++] = '' # 出C front == 3 rear == 3
排序
- 直接插入排序
- 希尔排序
- 快速排序
- 简单选择排序
- 堆排序
- 归并排序
python实现各种排序
堆排序使用python自带的heapq包即可
直接插入排序
思想:将一个序列分为两部分:有序和无序。初始有序部分为序列的第一个元素,其余元素组成了无序部分。然后,每次将无序部分的第一个元素插入有序部分的合理位置,直到无序部分为空。

temp表示监查哨兵,即上一个移动过位置的值。
希尔排序
思想:每次按照一定的间隔,将原始序列中的元素抽取出来,对这一部分进行排序。间隔逐渐减小,直至为1。当间隔为1时就是直接插入排序,直接插入排序完成,则算法结束。

快速排序
思想:有两个指针,分别指向初始序列的首元素和尾元素位置。比较两个指针上的值,若左指针的值比右指针的值大(即出现了顺序错误),则对换两个指针上的值,再移动左指针;否则移动右指针。重复此步骤,直到左右指针指向同一个值,即完成了一个阶段的快速排序,使得该序列被一个值分为两部分,左侧比其小,右侧比其大,这个值的排序最终位置就此确定,不再改变。接下来,分别对左右两部分进行快速排序,直到整个序列上所有的值的最终位置都被确定,不再变化。

initial = [19,38,65,97,76,13,27,49]
left = 0 right = 7
pivotkey = 19 # 当前轮要确定最终位置的数字用pivotkey存下来
# 左右指针轮流移动,若左值大于右值,则对换值的位置
# 一旦进行了对换,则换一个指针移动
# 一般第一轮开始的时候,默认先右指针动。
简单选择排序
思想:每次从序列中选择最小的值放入有序序列,直到原始序列中的值都被拿走。

堆排序
思想:通过构建最大堆或最小堆,依次从堆顶取出一个元素,并进行堆调整,再取出下一个元素,直到所有元素被取出,即可得到排序结果。

归并排序
思想:以“二路归并”为例,两两组合并排序,直到全部排完。

常见排序方法的时间和空间复杂度

树
二叉树
- 三种遍历
- 线索二叉树
- 平衡二叉树
- 最优二叉树(赫夫曼编码)
三种遍历
前序遍历,中序遍历,后续遍历。
思想:将树看成一串葡萄,将根结点向左拽,就是前序,向上拽就是中序,向后拽就是后续。
线索二叉树
通过某种遍历得到每个结点在这种遍历下的前驱结点和后续结点的地址,存入该结点。好处是当这种遍历经常使用时,可以快速得到遍历结果。

平衡二叉树
思想:为了使得二叉树不变成“长条状”,即为了让同一层的位置尽量被用满,同时也是为了减小二叉树的深度,方便快速查询,对一般二叉树中“过长分支”进行多次旋转操作之后得到的二叉树。

最优二叉树
思想:当树的“树枝”和结点上有权重时,整个树上所有“树枝”的权重*结点权重之和成为树的带权路径长度(WPL),通过调整树的结构使得WPL最小,此时得到的树为最优二叉树(赫夫曼树)。
由此得到的到每个结点的路径上的权重所组成的编码成为赫夫曼编码。
构造方法:给定结点集合,每次从中拿两个最小的,构成两个子结点,并构造他们的父结点。父结点权值为两个子结点权值之和。然后再每次选两个权值最小的子树构造他们的父结点,即整合成一个树。依次类推,最终得到赫夫曼树。
至多m叉树(B-树和B+树)
- 结构
- 插入
- 删除
B-树结构

思想:每个结点存至多存m-1个值,然后这m-1个值的左右两边存子结点地址。如果这个地址左边为的值为a,右边的值为b,则这个地址指向的子树中所有的值都在(a,b)范围内。
B-树插入
分为三步:1.找到插入位置d;2.判断d处值的个数小于或等于m-1,若满足则插入d,完成;否则执行3.插入d,然后选则中间值放入父结点,将d拆分为两个结点,并对父结点做同样判断和判断过后的操作。
图
- 遍历(深度优先搜索(DFS)和广度优先搜索(BFS))
- 数组表示法和邻接表(逆邻接表)
- 连通分量(强和弱)
- 生成树(最小生成树)
- 拓扑排序
遍历
深度优先搜索:即树的深度优先搜索(栈实现)
广度优先搜索:即树的广度优先搜索(队列实现)
图的表示法
二维数组,邻接表(行出列入),逆邻接表(列出行入)
这三种都是表示的邻接矩阵或其转置矩阵,第一种用二维数组(连续内存)实现,后两种用二维链表(分散内存)实现。
连通分量
定义:连通分量就是一个子图中任意两点之间有可达路径。
强连通分量:一个子图中任意两点之间存在单向可达路径。
弱连通分量:一个子图中任意两点之间存在双向可达路径。
最小生成树
目标:对连通的带权图而言,找到其边权之和最小的生成树。
Prim算法:从一个点出发,每次选当前生成树的邻边中权重最小的一条,直到整个图中的点都在生成树中。

Kruskal算法:首先从所有边中选出权重最小的一条,这条边及其两个端点构成了初始的生成树,然后从继续从剩下的边中选出权重最小的一条,加入这个生成树,直到原图中所有点都在这个生成树中。

拓扑排序
思想:从原始图中,每次找一个只有出度没有入度的点,将这个点拿出来,并在原图中将这个点及其出边删除。以此类推,最终整个图中的点和边都被删除,得到的拿出来的点的顺序就是这个图的拓扑排序。

















 521
521











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









