







最近开始补一补基础,捡起了多次学习后又放弃的操作系统,学习6.s081课程,前三节课的内容都比较简单,就没做笔记了,从这节课开始内容和作业都比较硬核了,也认真看了课程文档并翻译,前前后后大概花了十天,翻译文档花了5天,看课程花了两天,作业花了三天,继续好好学英语,希望后面能提高速度。
1. 课程总结
- 页表的机制,非常简单了,书上八股文都背烂了,就是个数组,通过多级页表的方式减少内存开销
- 页表是由内核维护的,即如何映射页面都是xv6的代码来控制的,但是最终使用页表寻址的MMU硬件,在RISC-V硬件中,通过satp寄存器控制是否开启分页功能,开启后,cpu使用的所有地址都变成了虚拟地址,MMU通过页表将其转换为物理地址,satp中存放页表的根页面地址,给MMU查找页表使用
- TLB是硬件层面的机制,对应用层其实是透明的,其实就是个cache,但是切换页表时需要清空TLB,这个由代码进行控制
- 页表分为进程页表和内核页表,这样设计的作用是隔离性。也有的实现是只使用一个页表,但是通过页面标记位是否可以被用户访问来控制权限。
2. 课后作业
课后作业真是panic到崩溃一共三个题,参考这个大佬的就好,自己的代码就不贴上来献丑了。
大佬的代码
3. 课程文档翻译
Page tables
操作系统通过页表机制为每个进程提供私有的地址空间和内存。页表中可以查询内存地址所对应的可访问的物理地址。这就使得xv6可以隔离不同的进程,并且在同一个物理内存上并发多个进程。页表提供了一个间接层来帮助xv6实现一些功能:将一些地址空间映射到相同的内存(a trampoline page),通过未映射的页面(guard page)保护内核和用户栈。 本章剩余内容介绍RISC-V硬件提供的页表机制以及xv6如何使用他们。
3.1 Paging hardware
RSIC-V指令(包括内核指令和用户指令)都操作虚拟地址。而机器的RAM(物理内存)只能被物理地址寻址。RISC-V的硬件通过将每一个虚拟地址映射到物理地址的方法,连接两种不同的地址。
xv6运行于Sv39 RISC-V,该芯片只使用64bit中的低39位作为虚拟地址。在Sv39的配置中,页表是一个数组,其中有2^27个PTEs(page table entries)。每个PTE含有44位PPN(physical page number)和一些page flag。硬件会使用39位地址中的高27位索引页表中的PPN来将虚拟地址转换为物理地址,56位的物理地址,其中高44位来自于PTE中的PPN,低12位直接使用虚拟地址中的低12位(page number+offset)。图3.1展示了一个页表的逻辑视图,是一个简单的PTEs数组(图3.2是更真实的实现)。页表提供给操作系统一个虚拟地址和物理地址转换的功能,以page(4096bytes)为粒度。
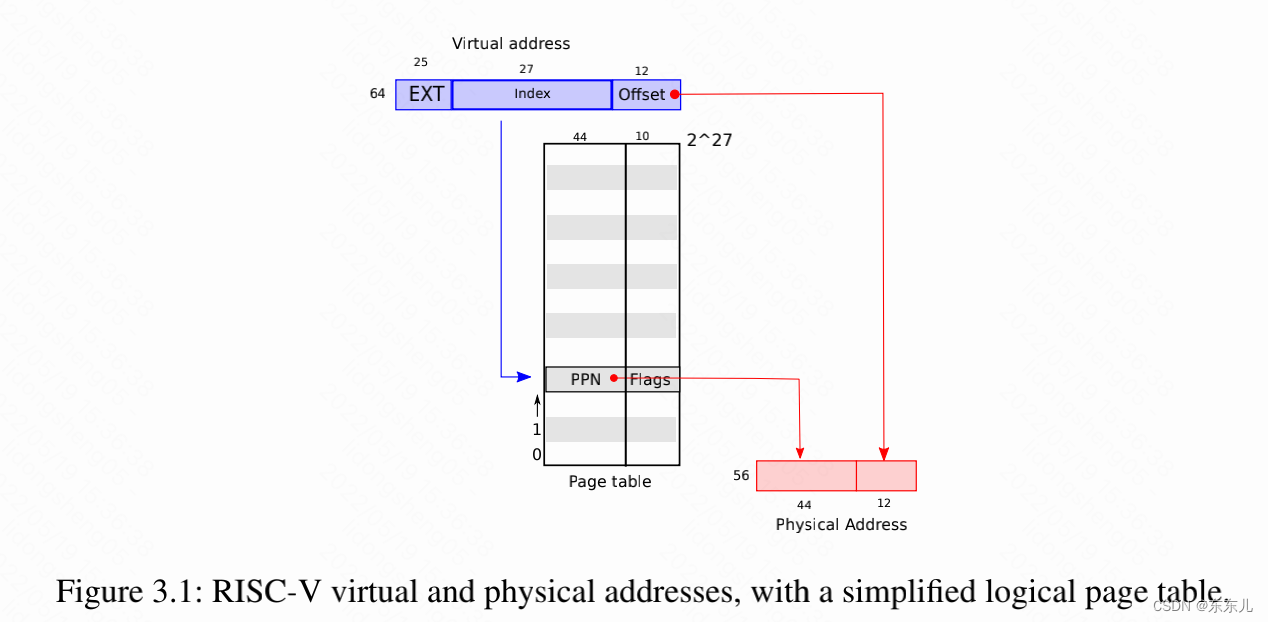
在Sv39 RISC-V中,虚拟地址的高25位并不会被用于地址转换;在未来,也许会用到这些bit来实现更多级的转换。物理地址也有增长的空间:PTE的格式中还有10个bit用户存放PPN。
如图3.2所思,真实的地址转换需要三个步骤。页表被存放在物理内存中,结构类似于一个三级的Tree。根页面是一个4096 byte的页面,其中含有512个PTEs,PTE中包含了下次层页表所对应的物理地址,这些页面中也包含512个PTEs,每个PTE对应一个第三层的页表。寻址的硬件使用27位虚拟页号中的高9位在索引根页表中的PTE,中间9位来索引第二级的PTE,最后9位来索引第三层页表。
在地址转换过程中,如果三级地址中的任何一个PTE不能存在都会触发page-fault 异常,内核将会接手并处理这个异常(参考Chapter 4)。三级页表的好处是,可以节省大量的空间,对于虚拟地址中大量未使用的范围,可以不创建对应的二三级页表。
每个PTE包含的flag可以告知硬件相关的虚拟地址应该如何被使用。PTE_V表示PTE是否存在:如果没有被设置,对该页面的引用会触发一个异常。PTE_R控制是否可以读这个page。PTE_W控制是否可以写这个page。PTE_X控制cpu是否可以将这个页面的数据解释为指令并执行。PTE_U控制是否允许用户态访问这个page。如果PTE_U没有被设置,那这个PTE只能在supervisor mode使用。图3.2展示了整个工作流,flag和所有页面硬件相关的结构被定义在(kernel/riscv.h)中。
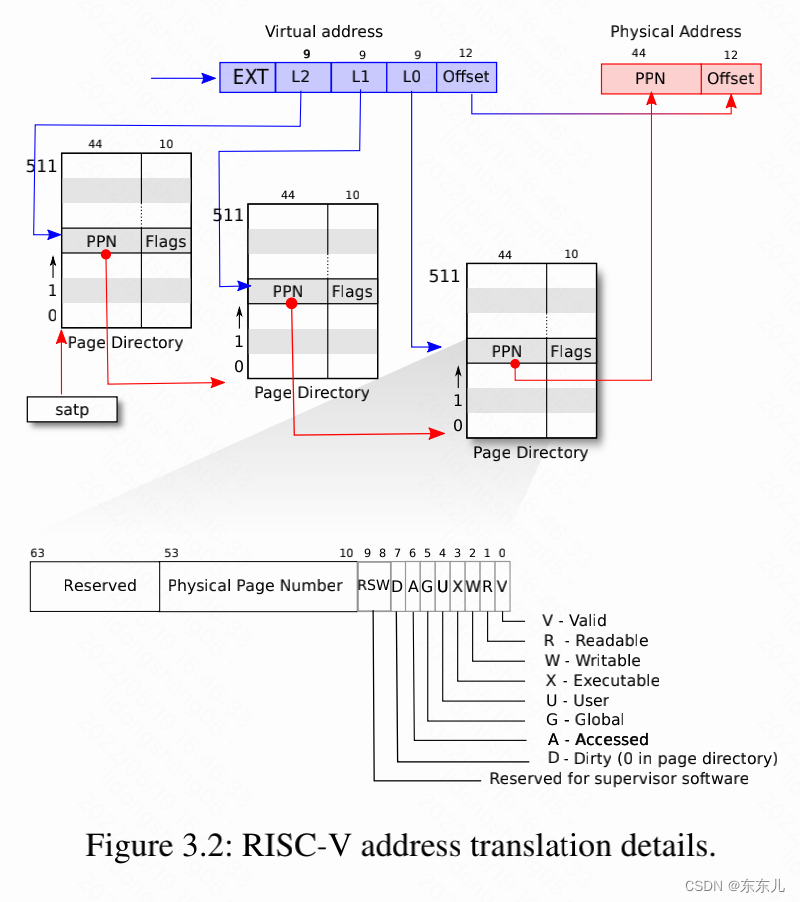
为了让硬件使用页表,内核必须将根页表的物理地址写入到satp寄存器中。每个CPU都有其自己的satp寄存器。CPU将会使用自己的satp寄存器指向的也表来转换后续指令生成的所有地址。每个CPU有自身的satp,所以不同的cpu能运行不同的进程,每个进程的私有空间都由自身的页表所定义。
一些额外的解释。物理内存指的是DRAM中的存储单元。每个物理内存的字节都有一个地址,叫作物理地址。指令(Instruction)仅使用虚拟地址,硬件会将其转换为物理内存,然后将其发送到DRAM硬件来读写数据。与物理内存和虚拟地址不同的是,虚拟内存不是一个物理对象,指的是内核用于管理物理内存和虚拟地址的抽象和机制。
3.2 内核地址空间
Xv6的每个进程都有一个页表,来描述每个进程的用户空间,加上一个单页表来描述内核地址空间。内核配置地址空间的布局,让自身通过可预测的虚拟地址来访问物理内存和大量硬件资源。图3.3展示了内核虚拟地址到物理地址的映射布局。文件(kernel/memlayout.h)定义了xv6内核内存布局所需要的常量。
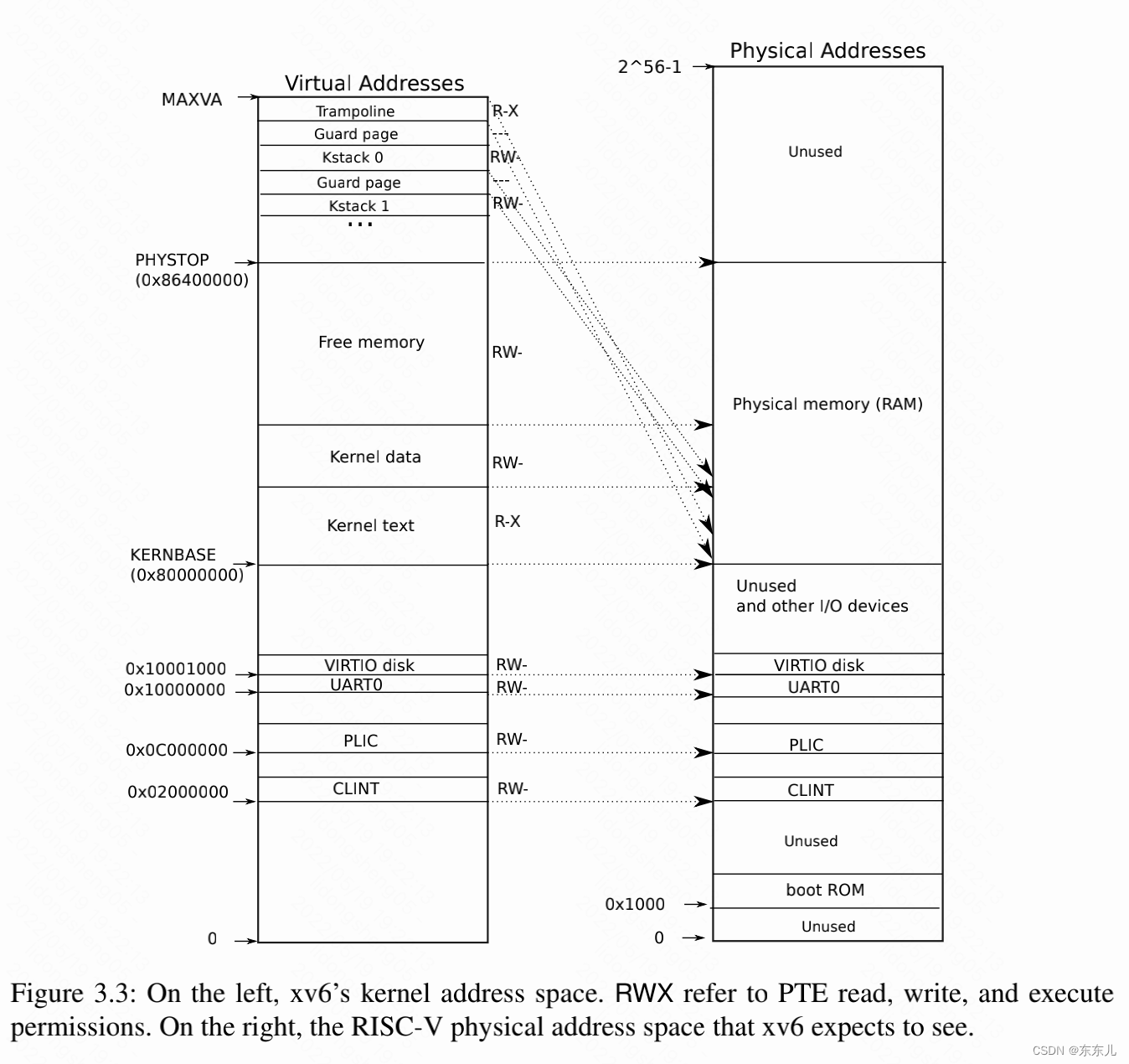
QEMU模拟地址从0x80000000开始的物理内存,至少以0x86400000结束,xv6将这段地址叫做PHYSTOP。QEMU也会模拟IO设备,如磁盘接口。QEMU以内存映射的方式将控制寄存器放置于物理地址空间0x80000000以下,并公开给软件使用。内核可以通过向这些特殊物理地址读写数据来与设备交互;这种方式是和设备硬件通信,而不是和RAM通信。第四节中会介绍xv6如何和设备交互。
内核通过直接映射(direct mapping)的方式访问内存和内存映射设备(上一段段落中所介绍的);内核会将这些资源映射到与物理地址相同的虚拟地址上。举个例子,内核自身位于KERNBASE=0x80000000处,无论是在虚拟地址还是在物理地址中都一样。直接映射降低了kernel读写物理内存代码的复杂度。举个例子,当fork分配用户内存给child 进程时,分配器分会物理内存地址;fork将parent的内存复制给child时,直接使用虚拟地址。
注意有两个内核虚拟地址不是直接映射的:
- trampoline page。它被映射到虚拟地址的最顶端;用户页表也存在相同的映射。第四节中讨论trampoline page的角色,目前我们只需要注意这一点即可;一个物理页面会被两次映射到内核的虚拟地址空间:一次被映射到虚拟地址空间的顶部,一次被直接映射。
- 内核栈页(kernel stack page)。每个进程都有自己的内核栈,他被映射到非常高的地址,以便于在其下方留有一个保护页面(guard page)。保护页面的PTE是无效的(PTE_V is not set),当内核栈溢出时,将会触发缺页中断(防止影响别人的栈)并且panic。如果没有保护页面,栈溢出将会覆盖其他内核内存,导致不正确的操作,相比较而言,crash是一个最好的结果。
While the kernel uses its stacks via the high-memory mappings, they are also accessible to the kernel through a direct-mapped address. An alternate design might have just the direct mapping, and use the stacks at the direct-mapped address. In that arrangement, however, providing guard pages would involve unmapping virtual addresses that would otherwise refer to physical memory, which would then be hard to use.(没看懂)
内核使用PTE_X标记映射trampoline页面和kernel text。内核可以从这些页面读取指令并且执行。对于其他页面,内核使用PTE_W和PTE_R标记,所以其他页面的内存是可以读写的,对于保护页面的映射是无效的(PTE_V invalid)。
3.3 Code: creating an address space
xv6中大部分控制地址空间和页表的代码在vm.c中(kernel/vm.c)。其核心数据结构是pagetable_t,这是指向RISC-V根页表页面的指针;pagetable_t可能是一个内核页表,也可能是每个进程对应的页表。核心函数是walk,该函数功能是找到虚拟地址对应的PTE,也可以新增PTE以映射新页面。以kvm开始的函数操作内核页表,以uvm开始的函数操作用户页表,其他函数也符合该规律。copyout和copyin函数可以从系统调用参数中给定的虚拟地址中拷出/入数据;它们都在vm.c中,因为他们都需要显式的转换他们的地址以找到对应的物理地址。
在启动顺序的早期,main函数调用kvminit(kernel/vm.c:22)来创建内核页表。这个调用在xv6启动RISC-V的页面管理前,所以这时候地址是直接指向物理内存的。Kvminit首先会分配一个物理内存来存放根页表。之后调用kvmmap来装载内核所需要的地址转换信息,这些信息包含内核的指令和数据,高于PHYSTOP的物理内存,指向设备的内存范围。
kvmmap(kernel/vm.c:118)调用mappages(kernel/vm.c:149),将一些虚拟地址和物理地址的转换信息写入到页表中,其中虚拟地址范围并不是连续的,是分段的,页面之间是存在间隔的。对于每一个需要被映射的虚拟地址,mapppages调用walk函数来找到其所对应的PTE的地址,之后会初始化PTE来保存相关的物理页面,并初始化对应的权限(读/写/执行),并设置PTE_V为有效的(kernel/vm.c:161)。
walk(kernel/vm.c:72)模仿RISC-V中的硬件,来查询一个虚拟地址所对应的PTE(过程如图3.2)。其每次使用9bit来寻找下一级页表,找到最终的页面(kernel/vm.c:78)。如果PTE是无效的,说明这个page还没有被分配;如果设置了alloc参数,那么walk将会分配一个新的页面,并将其物理地址写入到对应的PTE中。最终返回的是Tree(指页表结构)中最底层的PTE中的物理地址(即最终查找页面所对应的物理地址)。
上述代码的实现依赖于物理地址与内核虚拟地址的直接映射关系。举个例子,walk函数在查询多级页表时,它从PTE中获取下一级页表的的物理地址(kernel/vm.c:80),并且将这个地址转换为虚拟地址来访问下一级也表中的PTE(kernel/vm.c:78)。
main函数调用kvminithart(kernel/vm.c:53)来安装内核页表,它会将根页表的物理地址写入到satp寄存器中。此后,内核将会使用内核页表进行地址转换。由于内核是用了映射标记(打开了分页功能?),所以下一条指令的虚拟地址可以被映射到正确的物理地址上。
procinit(kernel/proc.c:26)在main函数中被调用了,其为每个进程分配了一个内核栈,其使用KSTACK宏,生成内核栈虚拟地址时会多生成一个保护页面。kvmmap向内核页表增加PTE,随后调用kvminithart重新装载内核页表到satp寄存器中,让硬件能够感知到新的PTE。(这块描述感觉比较绕,代码中的逻辑是在kvminit中实现了页表,并且将内核栈相关的PTE添加到了页表中(proc_mapstack),之后调用了kvminithart函数重新装载页表,procinit就可以直接使用内核栈对应的地址了)
每个RISC-V的CPU都会在TLB(Translation Look-aside Buffer)缓存PTE,当xv6改变页表信息时(进程切换?内核态切换?)必须告知CPU清除掉TLB中的缓存信息,如果不这样做,那么一个进程可能会通过TLB的信息访问到另一个进程的物理内存。RISC-V有一个sfence.vma指令可以清理CPU的TLB信息。xv6在trampoline中,返回用户地址空间之前,会先切换用户页表,所以会在kvminithart中执行sfence.vma来重新装载satp寄存器(kernel/trampoline.S:79)。
3.4 Physical memory alloction
内核必须能够在运行时为页表,用户内存,内核栈,pipe等分配物理内存。
xv6使用[end of kernel, PHYSTOP] 之间的物理内存作为运行时可分配的内存。它一次可以分配或者释放一个4096字节的页面。它通过一个空闲链表来管理哪些页面是可用的;分配指的是从空闲链表中删除一个页面,释放指的是将一个空闲页面加入到链表中。
3.5 Physical memory allocator
物理内存分配器代码再kalloc.c(kernel/kalloc.c:1)中。分配器的数据结构是一个空闲链表,其中的元素是可被分配的物理内存页面,对应代码中的struct run(kernel/kalloc.c:17)。那么分配器本身存放数据结构的内存来自于哪儿呢?它将每个空闲页面的run结构存放在空闲页本身中,毕竟空闲页面中并没有存放其他任何数据。空闲链表被一个spin lock保护(kernel/kalloc.c:21-24)。链表和保护链表的spin lock被封装在一个结构体中,让代码逻辑更清晰。现在,先忽略这个锁,及acquire和release调用,具体细节会在Chapter 6中介绍。
main函数调用kinit来初始化分配器(kernel/kalloc.c:27)。kinit将[end of kernel, PHTSTOP]之间的内存初始化为空闲链表。xv6可以通过硬件提供的信息,来确定有多少物理内存可以被分配。xv6假设只有128M内存可以被使用。kinit调用freerange,该函数中通过对每个页面调用kfree来将其添加到链表中。一个PTE只能引用了个物理地址是4096倍数的物理页面,所以freerange使用PGROUNDUP来保证其只对对齐的(4096倍数的)物理页面进行了初始化。分配器最初是没有内存的,调用kfree之后获得了一些管理链表的空间。
分配器又是会将地址作为一个整数进行计算(freerange红遍历所有的页面),有时会将地址作为一个指针来读写内存(举个例子,每个page中的struct run);这两种使用方式使得分配器代码中充满了C风给的类型转换;充满类型转换代码的另一个原因是释放和分配的本质就是改变内存的类型(没看懂)。
kfree函数(kernel/kalloc.c:47)会将page中的bit全部初始化为1。这将会使得那些使用悬空引用(已经释放的地址)的代码只能读到垃圾数据,而不是读取到就数据,让程序更快的crash掉(crash比按照未知态运行更好);之后kfree将页面加入到空闲链表中,其将pa转换为struct run的指针,将其插入到空闲链表的头部。kalloc会移除并返回空闲链表中的第一个元素。
3.6 进程地址空间
每个进程有一个独立的页表,当xv6进行进程切换时,页表也会切换。如图2.3所示,一个进程的用户内存从虚拟地址0开始,最大时MAXVA(kernel/riscv.c:348)。原则上一个进程可以使用256G的内存地址。当一个进程向xv6索要更多的内存时,xv6首先调用kalloc来分配一个物理页面。随后将该页面对应的PTE添加到进程的页表中。xv6设置PTE_W,PTE_R,PTE_U,PTE_X,PTE_V标记位。大部分进程都不会使用整个地址空间,所以对于未使用的PTE其PTE_V是无效的。
我们来看一些对于页表使用的示例。示例1,不同进程页表会将用户地址转换为物理内存的不同页面,这样每个进程可以获得私有的物理内存。示例2,每个进程自身的虚拟地址空间是一个从地址0开始的连续空间,但是物理内存并不是连续的。示例3,内核将一个 trampoline code映射到用户空间最高的一个地址上,因为页表可以将一个物理内存放置到地址空间的任何一个地址上。
如图3.4所示,是xv6中进程的用户内存空间布局。其中stack是一个单独的页,显示exec创建的初始化内容。在栈的顶端中存放了命令行的参数, Just under that are values that allow a program to start at main as if the function main(argc, argv) had just been called.(看不懂,是想说下面的一些值是函数的参数?)
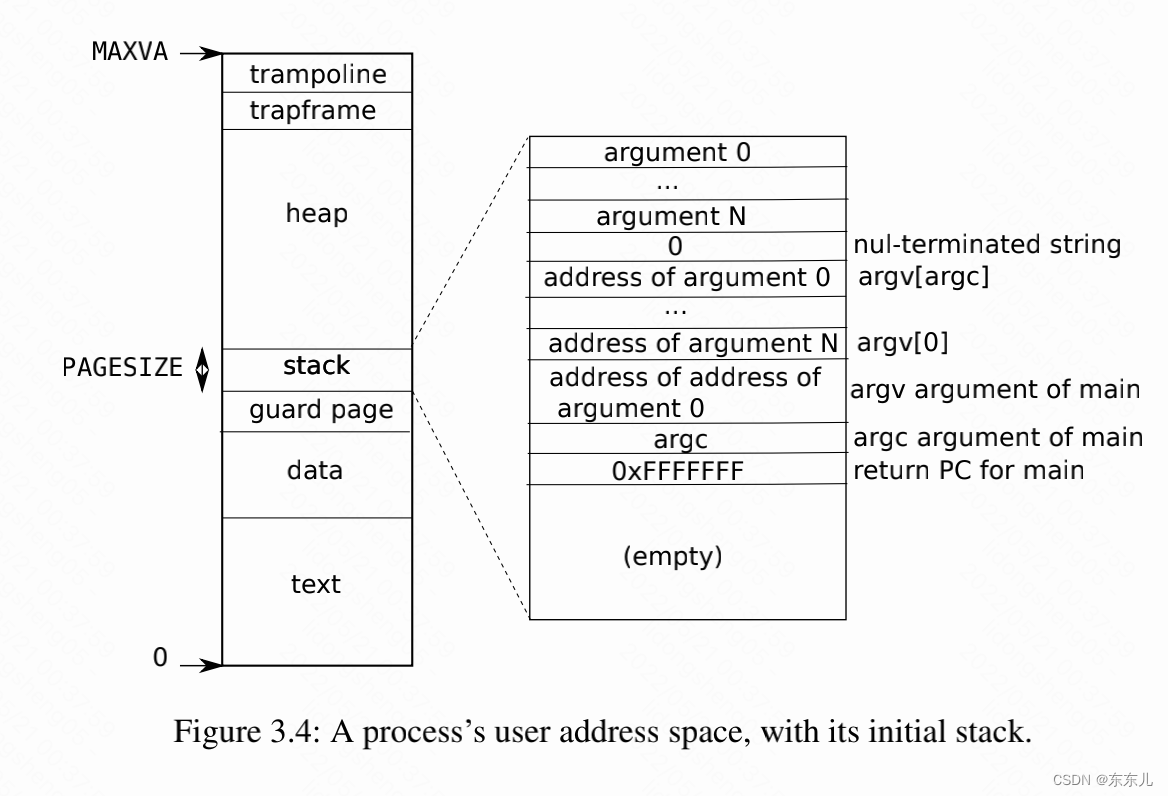
为了检测用户栈的溢出,xv6放置了一个无效的页面在栈的下方。如果用户栈溢出或者进程尝试使用一个栈之下的地址,硬件将会生成一个缺页异常,因为这个地址的映射是无效的。真实的OS中,业务会在栈溢出时分配出更多的物理内存。
3.7 Code: sbrk
Sbrk是一个系统调用,进程可以用它扩展或者收缩自身的内存。该系统调用使用了growproc函数实现(kernel/proc.c:239)。growproc的参数n如果是一个正数就调用uvmalloc,如果是负数就调用uvmdealloc。uvmalloc(kernel/vm.c:239)会使用kalloc来分配物理内存,并使用mmapages将PTE添加到页表中。uvmdealloc调用uvmunmap(kernel/vm.c:174),该函数会使用walk来寻找PTE并调用kfree释放掉对应的内存。
xv6的进程页表不仅告诉了硬件虚拟地址是如何映射的,也是分配给该进程的物理内存的唯一记录。这也是为什么释放用户内存(uvmunmap)需要检查用户页表。
3.8 Code: exec
exec是一个系统钓鱼哦那个,可以创建用户地址空间。它使用文件系统中的文件来初始化用户部分地址空间。Exec(kernel/exec.c:13)使用namei(kernel/exec.c:26)打开一个名为path的二进制文件,其细节将会在Chapter 8中介绍。之后,其读取ELF的头信息。xv6应用程序采用了广泛被使用的ELF格式,其格式被定义在(kernel/elf.h)中。一个ELF二进制文件开始的信息是头信息,struct elfhdr(kernel/elf.h:6),紧接着是程序段的头信息,struct proghdr(kernel/elf.h:25)。每个proghdr都描述了一个会被装载进内存的程序段;xv6程序仅函授一个程序段头信息,但是其他系统可能有多个独立的程序段来装载不同的指令和数据。
第一步是全速检查这个文件是否符合一个ELF二进制文件。一个ELF二进制文件以4字节的magic number开始,ox7f,‘E’,‘L’,‘F’,或者是ELF_MAGIC(kernel/elf.h:3)。如果ELF头信息有一个正确的magic number,exec就认为其是符合规范的。
Exec通过proc_pagetable分配一个没有任何用户映射的新页表(kernel/exec.c:38),使用uvmalloc为每个ELF 段(segment)分配内存(kernel/exec.c:52),并且使用loadseg将每个段装载到内存中(kernel/exec.c:10)。loadseg使用walkaddr来查找已分配内存的物理地址,来写入ELF段的每个页面,使用readi来从文件中读取。
下面是exec创建的第一个进程,init所对应的进程段头信息:

进程段的filesz可能会小于memsz,这意味着二者之间的gap需要以0填充(作为C程序的全局变量),而不是读取文件中的信息。对于init程序而言filesz是2112字节而memsz是2136字节, uvmalloc分配足够多的物理内存来存放2136字节数据,但是仅仅只从init文件中读取2112字节文件数据。
现在exec分配和初始化用户栈。其仅分配一个栈。exec拷贝参数到栈的顶端,并且在ustack中记录它们的指针。其放置一个空指针在参数的末尾。ustack中的头三个信息是,一个虚假的返回程序计数器(PC),argc和argv指针。
exec会在这个栈下方放置一个不可访问的页面(PTE_U是无效的,所以用户无法访问),当程序溢出时,会使用到这个页面从而触发错误。这个不可访问的页面也允许exec来处理参数太大的问题;在这种情况下,exec使用copyout(kernel/vm.c:355)函数来将参数拷贝到栈中时,会发现那个页面不可用,从而返回-1。
因为准备了新的内存映像,当一个exec检测到了一个类似于非法程序段的错误,其将会跳转到一个bad标签,释放掉新的内存映像,并返回-1。exec必须等到能够确定这个系统调用会成功后,才能释放掉旧的内存映像: 如果旧的内存先丢掉,那么这个系统调用就无法返回-1了。exec出现错误的唯一情况是在创建映像的过程中。一旦新映像完成,exec可以提供新的页表(kernel/exec.c:113)并且释放掉旧的(kernel/exec.c:117)。
exec从ELF文件的特定地址装载数据到内存中。用户或者进程可以讲任何他们想要的地址放置到ELF文件中。因此exec是高风险的,因为ELF中的地址可能会意外或者故意引用到内核,如果内核不小心地处理这种问题,将会造成严重问题,轻则crash,重则隔离机制失效(安全漏洞)。xv6使用一系列的检测来规避风险。举个例子if(ph.vaddr + ph.memsz < ph.vaddr)检测求和运算是否溢出。其危险之处在于,用户可以构建一个ELF文件,ph.vaddr在用户可指定范围内选取一个,重点是其ph.memsz足够大,导致求和溢出,最终和为0x1000。在旧版本的xv6中,含有内核(虽然页面在用户态不可读写),用户可以选择一个对应内核的地址,通过上述机制可以将ELF数据拷贝到内核中。在RISC-V版本的xv6种这已经不能再实现了,因为内核有了独立的页表;loadseg会装载用户页表而不是内核页表。
对于一个内核开发者而言很容易漏掉一个关键的检查,在真实的内核中,也有很长一段时间缺乏某些检测,导致了安全漏洞,用户进程可以借助它们获取到内核特权级别。对于用户传入到内核中的数据,xv6并没有做完备的校验,恶意的用户进程可以利用它们来破坏xv6的隔离性。
3.9 Real World
和大多数操作系统类似,xv6使用了分页硬件对内存进行映射和保护。大多数操作系统通过结合page-fault异常和页面机制来实现比xv6更复杂的分页机制,这将在Chapter 4中进行讨论。
xv6的内核将虚拟地址和物理地址进行简单映射,并且假设物理RAM的地址是0x8000000,即装载内核的地址。这种方式仅仅适用于QEMU,在真实的硬件上并不是一个好主意;真实的硬件放置RAM和设备在不可预知的物理内存上,举个例子,在 0x8000000处可能并没有一个物理RAM。更多严谨的内核设计会通过页表将物理内存布局映射到内核虚拟地址布局上。
RISC-V支持在物理地址级别上的保护,但是xv6并没有使用这个功能。
在机器的内存足够过时,可以考虑使用RISC-V支持的“super pages”。当物理内存较小时使用小的page,这样允许更细粒度的分配和页面置换。举个例子,如果程序使用了8K内存,那么分配给它一个4M大小的super page就是浪费。拥有大量内存的机器上可以考虑使用大页内存,可以减少页表操作的开销。
xv6内核缺少一个malloc这样的分配器,来为小对象分配内存,以预防内核使用某些需要动态分配内存的复杂结构。
内存分配是一个永远的话题,最基础的关注点在于分配内存的利用率和为未来请求的预分配。现在的人们对于速度的重视超过了空间利用率。此外,一个完备的内核可以分配多种尺寸的小块,并不是像xv6一样只能分配4096大小的块;一个真实的内核分配器能够很好的处理大的块分配和小的块分配。















 560
560











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









