






一:MySQL函数—控制流函数
1. if逻辑判断函数
(1)select if (5>3,'大于','小于');
解释:如果条件5>3成立,则返回的是大于,反之则小于。
(2)select ifnull (5,0);
select ifnull (null,0);
解释:第一个逗号前5不为null,则返回其本身5,第二个为null,则返回0。
(3)select isnull (5,0); //0
select isnull (null,0); //1
解释:此函数就是用来判断是否为null,不是的话返回0,是的话返回1
(4)select nullif (12,12); //null
select nullif (12,13); //12
解释:此函数就是用来判断两个值是否相同,相同返回null,不相同返回第一个值
注意:前两个用的较多,比较重要,后两个了解就行,这些函数都挺简单,主要是能在查询表格时灵活运用。
2.case when 语句
(1)
select
case 5
when 1 then '你好'
when 2 then 'hello'
when 5 then '正确'
else
'其他'
end as info;//正确
解释:就是用case 后面的表达式或值和when后面的值相比较,相等则返回其then后面的值
(2)
select
case
when 2>1 then '你好'
when 2<1 then 'hello'
when 3>2 then '正确'
else
'其他'
end as info;//你好
解释:第二种就是case后面没有值,那就直接判断when后面的表达式,正确的话就返回其then后面的东西,但要注意如果有多个表达式正确,那么以第一个为准,后面的就不在执行了。
二:MySQL函数—窗口函数
1.序号函数
序号函数有三个:row_number(),rank(),dense_rank(),可以用来实现分组排序,并添加序号
格式:row_number() | rank() | densc_rank() over(
partition by...
order by...
)
操作:对每个部门的员工按照薪资排序,并给出排名
建表employ,查数据略
对表进行操作如下:
select
dname,
ename,
salary,
row_number() over(partition by dname order by salary desc) as rn1,
rank() over(partition by dname order by salary desc) as rn2,
dense_rank() over(partition by dname order by salary desc) as rn3,
from employee;操作后如下表:

注意对比三种函数操作后的结果,一般后两种函数用的较多。
2.开窗聚合函数
概念:在窗口中每条记录动态地应用聚合函数sun(),max(),avg(),min(),count(),可以动态计算在指定的窗口内的各种聚合函数值。
他们用法一样,这里就以sum()为例,其他的替换一下就可以了。
(1)建表employ,查数据略
对表进行操作如下:
select
dname,
ename,
hiredate,
salary,
sum(salary) over (partition by dname order by hiredate) as c1
from employee;操作后如下表:

(2)如果没有order by,则就是把分组后组内的薪资相加
操作如下:
select
dname,
ename,
hiredate,
salary,
sum(salary) over (partition by dname ) as c1
from employee;结果如图:

(3)还可以控制相加的范围。
sum(salary) over (partition by dname order by hiredate rows between unbounded preceding and current row) as c1解释:从开头加到当前行
sum(salary) over (partition by dname order by hiredate rows between 3 preceding and current row) as c1解释:从上三行加到当前行,没有就不用管,例如第一行没有上三行就不用管
sum(salary) over (partition by dname order by hiredate rows between 3 preceding and 1 row) as c1解释:从上三行加到后一行。
3.分布函数
(1)cume_dist()函数
用途:分组内小于,等于当前rank值的行数 / 分组内总行数
应用场景:查询小于等于当前薪资的比例
select
dname,
ename,
salary,
cume_dist() over(order by salary)as rn1,
cume_dist() over(partition by dname order by salary)as rn2
from employee;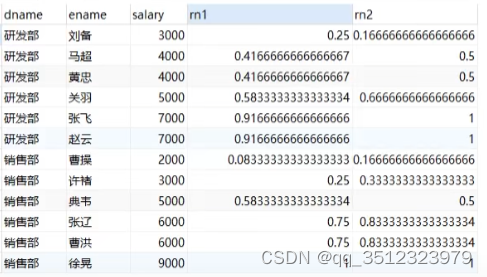
partiton by 就是起到一个分组的作用 。
解释:rn1中的0.25=3/12 rn2中的0.166666666666=1/6
(2)percent_rank()函数
介绍:每行按照公式(rank-1)/ (rows-1)进行计算。其中rank为rank()函数产生的序号,rows为当前窗口记录的分组后每组总行数。
应用场景:不常用...(了解)
select
dname,
ename,
salary,
rank() over(partition by name order by salary)as rn,
percent_rank() over(partition by dname order by salary)as rn2
from employee;
4.前后函数
(1)lag()函数
用途:返回位于当前行的前n行lag(expr,n)的expr的值。
应用场景:查询前一名学生成绩和当前学生成绩的差值。
select
dname,
ename,
hiredate,
salary,
lag(hiredate,1,'2000-01-01')over(partition by dname order by hiredate)as time1,
lag(hiredate,2)over(partition by dname order by hiredate)as time2
from employee;
第一个lag()函数给了默认值,第二个没给的话,默认值就为null。
(2)lead()函数
用途:返回位于当前行的后n行lead(expr,n)的expr的值。
应用场景:查询后一名学生成绩和当前学生成绩的差值。
此函数和lag()函数用法一样,这里就不多解释了。
5.头尾函数
(1)first_value()函数
(2)last_value()函数
用途:返回第一个first_value(expr)或最后一个last_value(expr)的expr的值
应用场景:截至目前,按照日期排序查询第一个入职和之后一个入职员工的薪资
为了表现得直观,这里将两个函数在一张表里同时使用。
select
dname,
ename,
hiredate,
salary,
first_value(salary) over(partition by dname order by hiredate)as first,
last_value(salary) over(partition by dname order by hiredate)as last
from employee;
6.其他函数
(1)nth_value(expr,n)函数
用途:返回窗口中第n个expr的值,expr可以是表达式,可以是列名
应用场景:截至目前,显示员工薪资中排名第二或第三的薪资
select
dname,
ename,
hiredate,
salary,
nth_value(salary,2) over(partition by dname order by hiredate)as second_salary,
nth_value(salary,3) over(partition by dname order by hiredate)as third_salary
from employee;
(2)ntile()函数
用途:将分区中的有序数据分为n个等级,记录等级数
应用场景:将每个部门员工按照入职日期分为三组
select
dname,
ename,
salary,
hiredate,
ntilea(3)over(partition by dname order by hiredate)as nt
from employee;操作后表格如下:
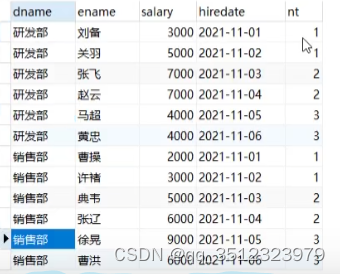















 153
153











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









