









学习内容
前情提要
使用一个vector来表示一个word,怎么做?
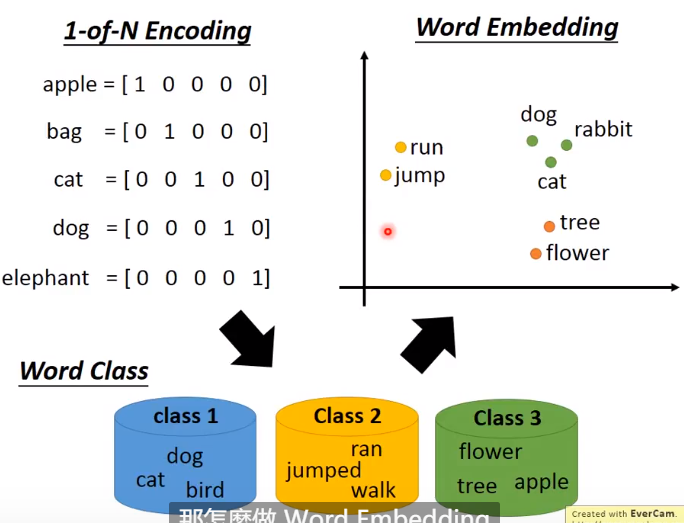
1-of-N Encoding
维度就是所有单词的量
缺点: dog 和 cat是不能归为一类的,只能单独的表示;
Word CLass
将同类别的归为一类; 但是更高层的token表示不清. 比如dog + flower = creature
Word Embedding
将word映射到高维度上,通常有50维度、100维度这个样子的dimension; 但是也比-of-N Encoding维度少的多,这是dimension reduce的化身。 类似语义的在这个图上相同位置,而且不同语义中有不同的维度,dimension也会有不同的语义。
Word Emedding
方法
这是一个无监督问题; 机器需要通过读大量的文件学习单词的意思。 而且我们只知道它的输入,不知道它的输出(多少维度的word)。

所以应该怎么做? 我们可以通过上下文来获得,比如马英九和蔡英文通过这样句子的分析,都是上下文类似的,那么必然都是同一种物件。

Count based
两个单词越近越好; w i w_i wi和 w j w_j wj是两个单词,而 V ( w i ) V(w_i) V(wi)是它的向量表示;

Predition based
学习一个neural network来预测下一个单词是某个word的几率。
输出是所有的words的概率!输入和输出都是lexicon words (因为都是1-of-N-encoding)
我们选取hidden layer中的一层就可以表示它的向量了。 为什么用这个prediction based的方法呢?
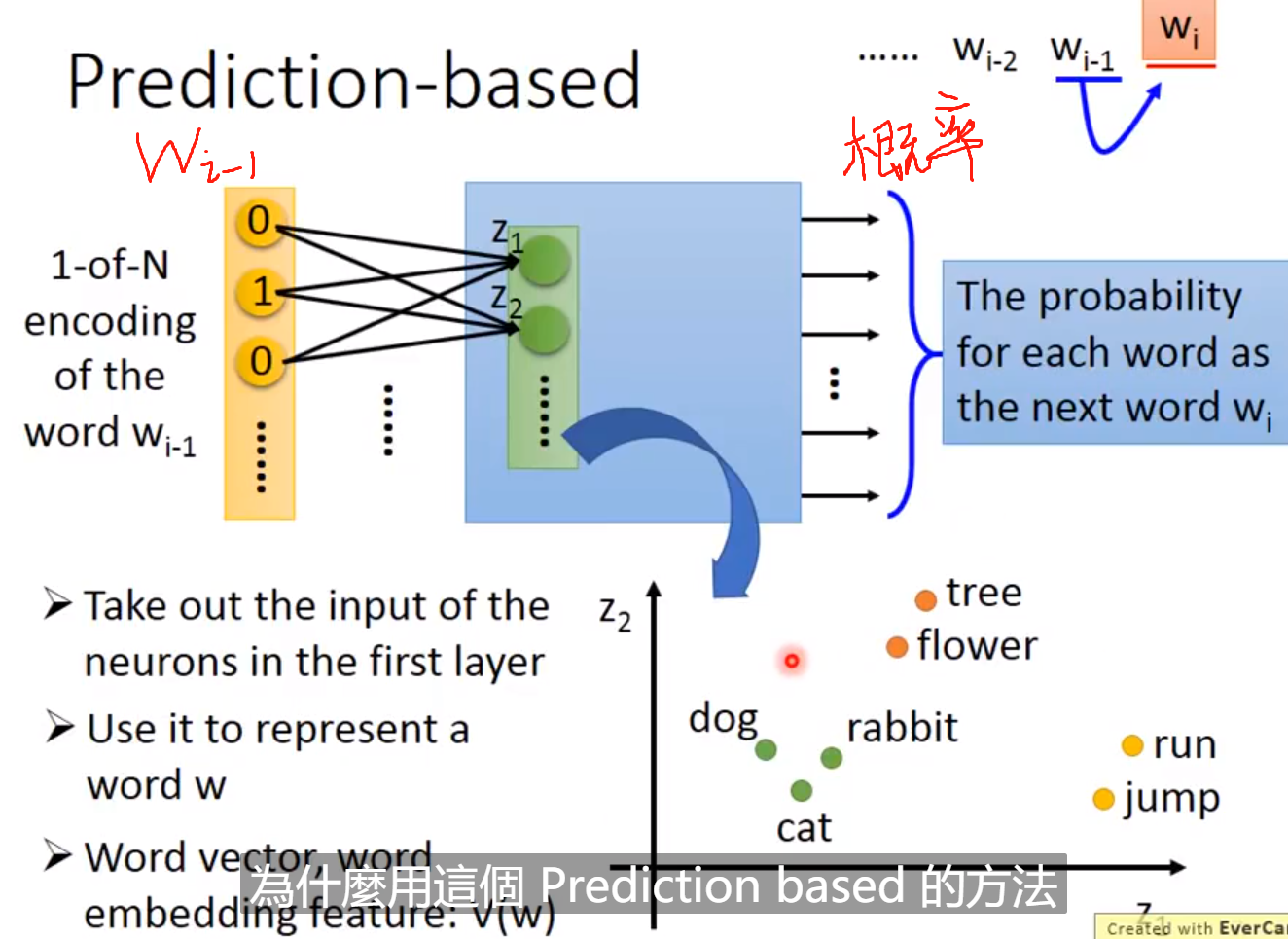
比如,下面的句子:我们输入蔡英文和马英九那, 我们希望他输出的“宣誓就职”的概率比较大,如果要完成这样的效果那么必须蔡英文和马英九两个的vector应该类似。

Predition based-sharing parameters
当然我们输出下一个单词的概率,输入不能是一个单词,最起码应该是两个或者十个;
其次我们在同时输入两个单词时,他们的权重应该都是共享的。 为什么呢?
如果我们不这么做,两个单词换个位置(比如apple: 00001 换成 10000),那么得到的embedding就会不一样哦! 其次是多个单词不用再用很长的权重维数了;



问题:propose word vector ,但是neural network不是deep network,而是普通的hidden layer?
tookit他做的很好;
hidden layer运算量少! 可以训练很多的data;
推论
相减

Multi-lingual Embedding
多语言的嵌入网络,必须输入的是英文和中文的材料。
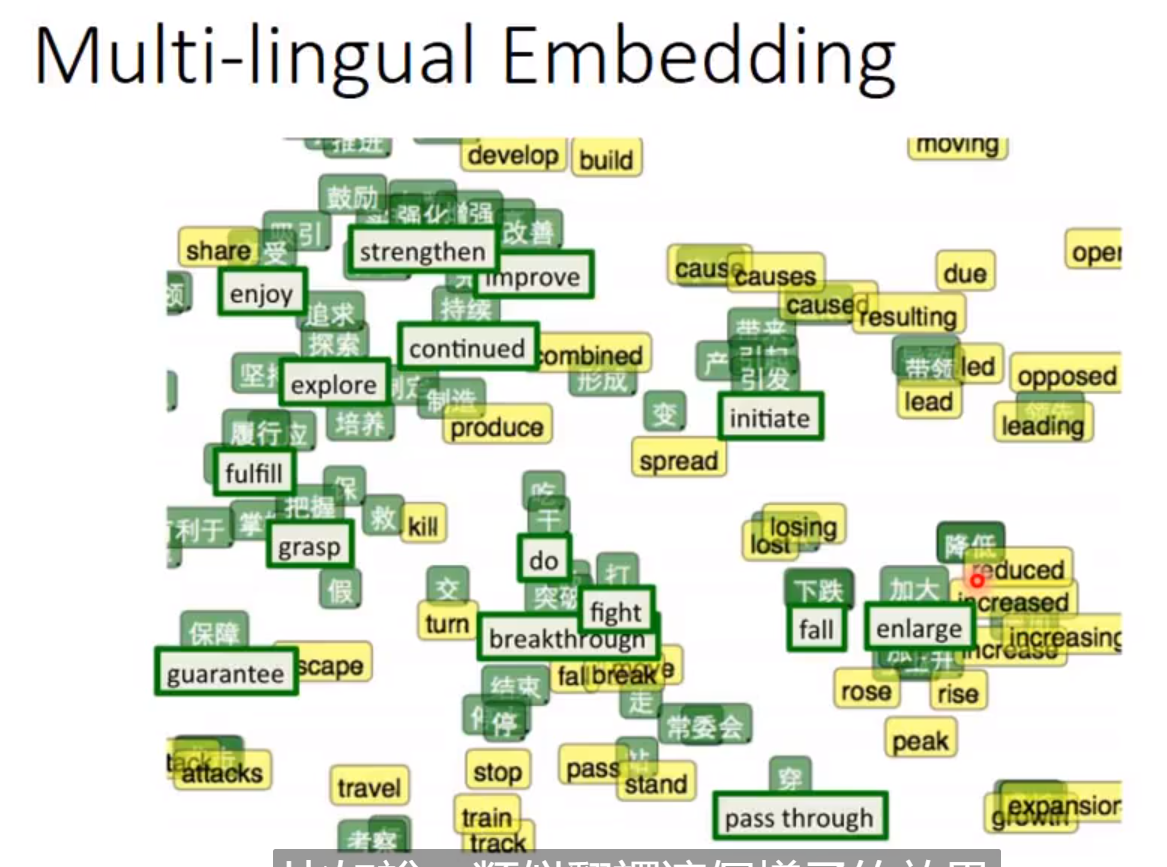
Multi-domain embedding
就是将类似的图片映射到同一领域
Document embedding
将Document变成bag-of-word,然后使用auto-encoder就可以learn出这个document的Semantic Embedding; 但是呢这样是不够的,只用这个word来表示document是不够的,为什么呢?
因为词汇的顺序有很重要的信息。
比如下面的两句话,它们的bag-of-word是一样的,因为相同的单词;但是他们的语义却完全不同。

bag - of -word: 就是只是单独考虑一个单词的意思,所以说是布袋里的单词,都是孤零零的!
Beyond bag of word
















 248
248











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









