









万人群聊系统设计的难点与架构优化实践
引言:群聊场景的独特挑战
在即时通讯系统中,系统的设计难度随着群组人数上限的增高而增大,这也是为什么微信的群组最多支持500人,本文将深入探讨万人群聊系统的核心难点,并给出经过大规模验证的优化方案。
一、消息存储:从写扩散到读扩散的范式升级
1.1 点对点与群聊的存储差异
- 点对点场景(写扩散)
每条消息为收发双方各自存储索引(如消息ID、时间戳),优势在于支持用户维度的快速检索,但存储成本与用户数线性增长。
对于点对点聊天来说,针对消息收发双方进行用户维度的索引存储,能便于后续会话维度的消息查看和离线消息的获取,但如果群聊场景也采取这种方式,那么假设一个群有一万个人,就需要针对这一万个人都进行这一条消息的存储,一方面会使写入并发量巨大,另一方面也存在存储浪费的问题。
所以,业界针对群聊消息的存储,一般采取“读扩散”的方式。也就是一条消息只针对群维度存储一次,群里用户需要查询消息时,都通过这个群维度的消息索引来获取
- 群聊场景(读扩散)
单条消息仅按群维度存储一次,所有群成员共享同一份数据。存储成本从O(N)降至O(1)(N为群成员数),但需解决以下问题:
1.2 关键问题与解决方案
| 问题场景 | 解决方案 | 技术实现 |
|---|---|---|
| 新成员历史消息隔离 | 记录用户加群时间戳与最新消息ID | 在用户-群关系表中存储join_time和last_msg_id,查询时自动过滤旧消息 |
| 成员删除单条消息 | 维护用户-群维度的删除记录 | 使用布隆过滤器或位图标记被删除消息,查询时动态过滤 |
| 消息冷热分离 | 分层存储策略 | 热数据存Redis(近3天),温数据存Cassandra(3天-1年),冷数据存S3/OSS |
读扩散架构示例:
class GroupMessageStorage:
def store_message(self, group_id, message):
# 写入群维度存储
cassandra.execute(
"INSERT INTO group_messages (group_id, msg_id, content) VALUES (%s, %s, %s)",
(group_id, generate_snowflake(), message)
)
def get_messages(self, user_id, group_id):
# 获取用户加群信息
join_info = redis.hgetall(f"user:{user_id}:group:{group_id}")
# 查询群消息并过滤
return cassandra.execute(
"SELECT * FROM group_messages WHERE group_id = %s AND msg_id > %s",
(group_id, join_info['last_msg_id'])
)
二、未读数风暴:合并变更的削峰艺术
2.1 未读数写入的雪崩效应
假设一个5000人群每秒产生10条消息,传统方案的未读变更QPS为:
5000用户/群 × 10消息/秒 = 50,000 QPS/群
100个此类群组将产生500万QPS,远超常规数据库的写入能力。
2.2 三级缓冲合并架构
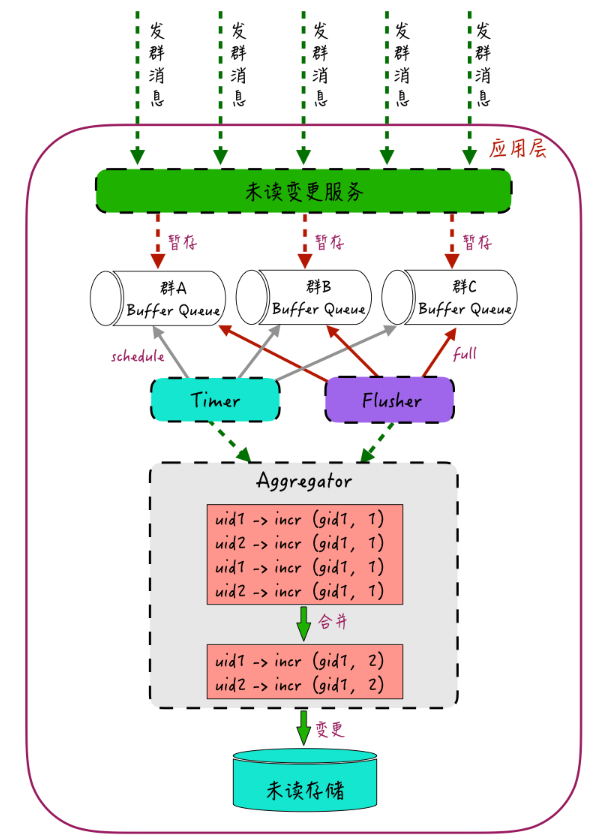
-
暂存队列
按群ID哈希到不同队列,内存暂存变更请求 -
双触发机制
- Timer:固定时间窗口(如1秒)批量处理
- Flusher:队列长度阈值(如100条)触发处理
-
聚合器
将多条增量合并为单条incr N操作:
// 示例:合并未读增量
Map<Long, Integer> userUnreadMap = new HashMap<>();
for (UnreadRequest req : requests) {
userUnreadMap.merge(req.userId, 1, Integer::sum);
}
// 批量写入:UPDATE user_unread SET count = count + ? WHERE user_id = ?
2.3 性能收益分析
| 合并度 | QPS降低比例 | 潜在延迟 |
|---|---|---|
| 10条合并 | 90% | ≤1秒 |
| 100条合并 | 99% | ≤1秒(Timer) |
注意事项:
- 使用WAL日志防止内存数据丢失
- 采用一致性哈希确保同群请求路由到同一节点
三、离线消息:轻量化存储与可靠投递的平衡
3.1 离线消息的存储优化
| 传统方案痛点 | 优化方案 | 收益 |
|---|---|---|
| 同消息多副本存储 | 仅存储消息ID | 存储空间降低90%+(假设消息体5KB) |
| 突发流量导致存储过载 | 动态限流+版本号链式同步 | 写入QPS可控,支持断点续传 |
版本号链式同步流程:
- 用户上线时携带最后接收的消息ID
last_msg_id - 服务端返回缺失ID范围
[start_id, end_id] - 客户端分批拉取具体消息内容
3.2 批量ACK机制
借鉴TCP的Delay ACK设计:
type BatchAcker struct {
pendingACKs map[int64][]MessageID
timer *time.Timer
}
func (a *BatchAcker) OnReceive(msg Message) {
a.pendingACKs[msg.UserID] = append(a.pendingACKs[msg.UserID], msg.ID)
if len(a.pendingACKs) >= 100 || a.timer.Expired() {
a.flush()
}
}
func (a *BatchAcker) flush() {
// 批量发送ACK: [user1: [id1,id2,...], user2: [...]]
sendBatchACK(a.pendingACKs)
a.pendingACKs = make(map[int64][]MessageID)
}
优势:
- ACK包数量减少50%-90%
- 容忍网络抖动,降低重复推送概率
四、在线推送:去中心化的连接治理
4.1 传统中心化方案的瓶颈
- 全局状态存储成为性能瓶颈(如Redis集群)
- 网关机与状态存储的跨机房调用增加延迟
4.2 自治式网关架构
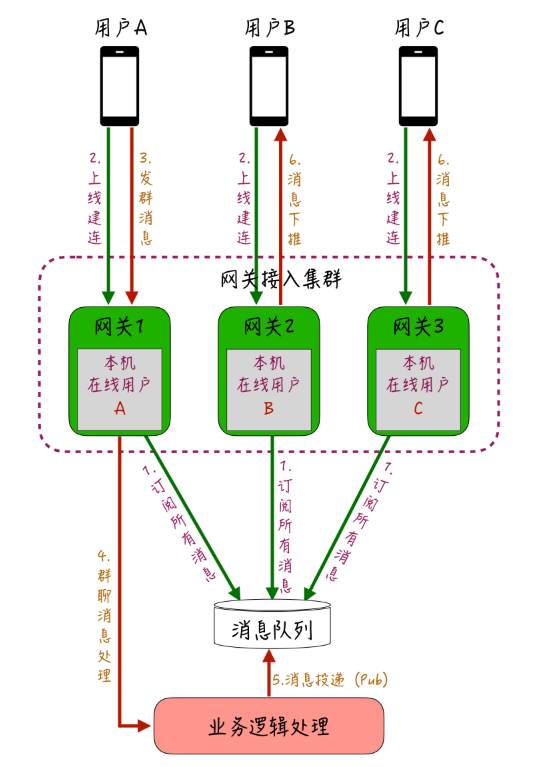
-
本地状态维护
各网关在内存维护<用户ID, 连接通道>映射表 -
消息广播机制
- 生产者将消息发布至Kafka Topic
- 所有网关消费全量消息,过滤本地连接用户
-
异常处理
- 心跳检测自动清理僵尸连接
- 网关宕机时客户端自动重连其他节点
关键代码片段:
class Gateway:
def on_message(self, msg):
# 过滤本地用户
local_users = self.connection_map.get_users(msg.group_id)
for user in local_users:
if user != msg.sender:
self.send(user.conn, msg)
def on_user_online(self, user_id, conn):
self.connection_map.add(user_id, conn)
五、总结:架构优化的核心思想
-
空间换时间
通过内存缓冲、合并操作化解写入风暴 -
异步化与批处理
将同步操作转化为异步队列处理,提升系统吞吐 -
数据分片与本地化
避免全局状态依赖,利用哈希分片实现水平扩展 -
柔性设计
允许短暂延迟/数据不一致,换取系统整体可用性
这些方案已在微博等亿级用户平台验证,可扩展至社交、IoT等需要海量消息分发的场景。在面对类似挑战时,开发者应重点关注写入放大与状态同步问题,通过分层治理实现系统弹性的跃升。
最后
欢迎关注gzh:加瓦点灯, 每天推送干货知识!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









