









1、直接使用sql搜索存在的问题
大多数搜索引擎应用都必须具有某种搜索功能 搜索功能往往是巨大的资源消耗 它们由于沉重的数据库加载而拖垮你的应用的性能 所有我们一般在做搜索的时候 会把它单独转移到一个外部的搜索服务器当中进行 Apache Solr是一个流行的开源搜索服务器
2、Apache Solr
Solr是一个开源搜索平台,用于构建搜索应用程序。 是一个独立的企业级搜索应用服务器,它对外提供类似于Web-service的API接口 它建立在Lucene(全文搜索引擎)之上。 Solr是企业级的,快速的和高度可扩展的。 用户可以通过http请求,向搜索引擎服务器提交一定格式的XML文件,生成索引;也可以通过Http Get操作提出查找请求,并得到XML格式的返回结果。
3、为什么选择Solr ?
第一点原因:来自SQL数据库在性能上缺乏亮点。基本上,你需要在你的查询中使用JOIN操作。 第二点原因是文档的天然数据特性松散的文本文件,这种查询都是需要使用LIKE。然而joins和likes都是性能杀手,在目前的数据库引擎中是不方便的。 solr底层采用的是倒排索引。这种数据结构类似于美化过的词典
4、Solr 关键特性
1.基于标准的开放接口:Solr搜索服务器支持通过XML、JSON和HTTP查询和获取结果。 2.易管理:Solr可以通过HTML页面管理,Solr配置通过XML完成。 3.可伸缩性:能够有效地复制到另外一个Solr搜索服务器。 4.灵活的插件体系:新功能能够以插件的形式方便的添加到Solr服务器上。 5.强大的数据导入功能:数据库和其他结构化数据源现在都可以导入、映射和转化。
5、Solr安装
5.1、上传安装包

5.2、对以上内容进行解压
解压tomcat
tar -zxvf apache-tomcat-8.5.32.tar.gz
mv apache-tomcat-8.5.32 tomcat
解压solr
tar -zxvf solr-4.10.3.tar
解压IK
unzip IKAnalyzer.zip
5.2、复制solr.war到tomcat/webapp下
cd /usr/local/solr/solr-4.10.3/example/webapps/
cp solr.war /usr/local/solr/tomcat/webapps/

5.3、启动tomcat让solr.war自动解压
/usr/local/solr/tomcat/bin/startup.sh
5.4、关闭tomcat
/usr/local/solr/tomcat/bin/shutdown.sh
5.5、进入到webapps删除solr.war包
cd /usr/local/solr/tomcat/webapps/
rm -rf solr.war
5.6、将solr-4.10.3/example/lib/ext/目录下的所有jar包拷贝到/usr/local/solr/tomcat/webapps/solr/WEB-INF/lib目录中
cd /usr/local/solr/solr-4.10.3/example/lib/ext
cp * /usr/local/solr/tomcat/webapps/solr/WEB-INF/lib
5.7、将solr-4.10.3/example/目录下的solr文件夹复制到/usr/local/solr/目录下并且重命名为solrhome
cd /usr/local/solr/solr-4.10.3/example/
cp -r solr /usr/local/solr/
cd /usr/local/solr mv solr solrhome
5.8、配置tomcat/webapps/solr/WEB-INF/web.xml家的位置
cd /usr/local/solr/tomcat/webapps/solr/WEB-INF/
vim web.xml
添加solrhome

6、域的分类
域的配置文件 cd /usr/local/solr/solrhome/collection1/conf/ vim schema.xml
6.1、什么是域
域相当于数据库的表字段,用户存放数据用户根据业务需要去定义相关的Field(域)
6.2、域的分类:
- field普通域 大多数情况都可以用这个域来完成, 主要定义了域名和域的类型.
- copyField复制域 复制域中有source叫做源域, dest代表目标域, 在维护数据的时候, 源域中的内容会复制到目标域中一份, 从目标域中搜索, 就相当于从多个源域中搜索一样
- dynamicField动态域 solr中域名要先定义后使用, 没有定义就使用会报错, 如果没有定义的域名想使用可以模糊匹配动态域, 让没有定义的域名可以使用.
- uniqueKey主键域 在添加数据的时候必须有主键域, 没有会报错, 这个不用添加也不用修改, 就使用这个默认的域名id就可以.
6.3、域的常用属性
name:指定域的名称type:指定域的类型indexed:是否索引stored:是否存储required:是否必须multiValued:是否多值想要往solr存储数据,就把相关字段写进域中
6.4、普通域
<field name="item_goodsid" type="long" indexed="true" stored="true"/>
<field name="item_title" type="text_ik" indexed="true" stored="true"/>
<field name="item_price" type="double" indexed="true" stored="true"/>
<field name="item_image" type="string" indexed="false" stored="true" />
<field name="item_category" type="string" indexed="true" stored="true" />
<field name="item_seller" type="text_ik" indexed="true" stored="true" />
<field name="item_brand" type="string" indexed="true" stored="true" />
<field name="item_updatetime" type="date" indexed="true" stored="true" />6.5、复制域
<field name="item_keywords" type="text_ik" indexed="true" stored="false" multiValued="true"/>
<copyField source="item_title" dest="item_keywords"/>
<copyField source="item_category" dest="item_keywords"/>
<copyField source="item_seller" dest="item_keywords"/>
<copyField source="item_brand" dest="item_keywords"/>6.6、动态域
<dynamicField name="item_spec_*" type="string" indexed="true" stored="true" />7、solrj
概述
solrJ是solr官方推出的客户端工具包, 将solrj的jar包放到我们项目中, 我们调用solrj中的api来远程给solr服务器发送命令, solr服务器就可以完成对索引库的操作(添加修改删除查询)
操作步骤
- 创建一个普通的Java工程
- 添加soloJ相关Jar包
- 操作
- 添加或者修改 修改时, 会把以前的内容删除, 然后再添加
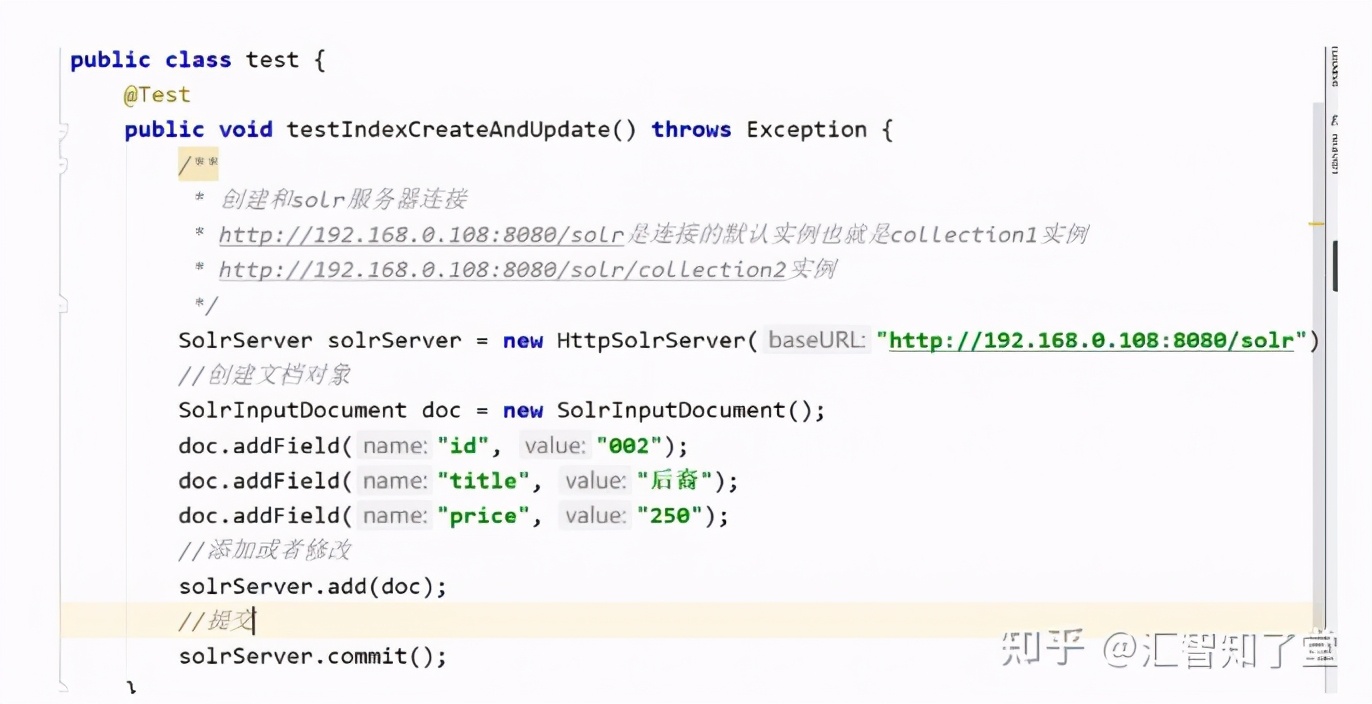
public class test {
@Test
public void testIndexCreateAndUpdate() throws Exception {
/**
* 创建和solr服务器连接
* http://192.168.0.108:8080/solr是连接的默认实例也就是collection1实例
* http://192.168.0.108:8080/solr/collection2实例
*/
SolrServer solrServer = new HttpSolrServer("http://192.168.0.108:8080/solr");
//创建文档对象
SolrInputDocument doc = new SolrInputDocument();
doc.addField("id", "002");
doc.addField("title", "后裔");
doc.addField("price", "250");
//添加或者修改
solrServer.add(doc);
//提交
solrServer.commit();
}
}查询所有
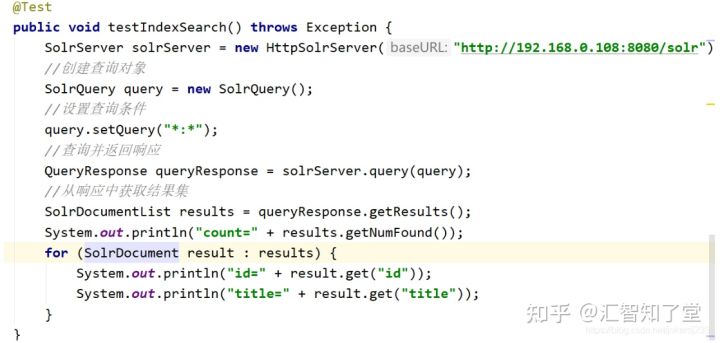
@Test
public void testIndexSearch() throws Exception {
SolrServer solrServer = new HttpSolrServer("http://192.168.0.108:8080/solr");
//创建查询对象
SolrQuery query = new SolrQuery();
//设置查询条件
query.setQuery("*:*");
//查询并返回响应
QueryResponse queryResponse = solrServer.query(query);
//从响应中获取结果集
SolrDocumentList results = queryResponse.getResults();
System.out.println("count=" + results.getNumFound());
for (SolrDocument result : results) {
System.out.println("id=" + result.get("id"));
System.out.println("title=" + result.get("title"));
}
}删除
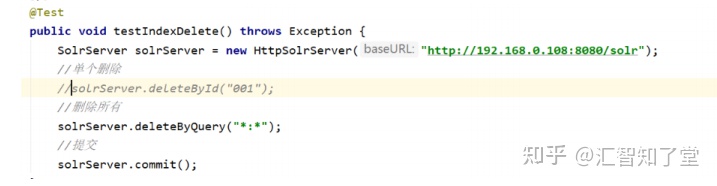
@Test
public void testIndexDelete() throws Exception {
SolrServer solrServer = new HttpSolrServer("http://192.168.0.108:8080/solr");
//单个删除
//solrServer.deleteById("001");
//删除所有
solrServer.deleteByQuery("*:*");
//提交
solrServer.commit();
}8、中文分词器
IK Analyzer简介
IK Analyzer 是一个开源的,基亍 java 语言开发的轻量级的中文分词工具包。它是以开源项目Luence 为应用主体的,结合词典分词和文法分析算法的中文分词组件IK 实现了简单的分词歧义排除算法,标志着 IK 分词器从单纯的词典分词向模拟语义分词衍化。作用: 有中文语义分析的效果, 对中文分词效果好.
安装
8.1、把IKAnalyzer2012FF_u1.jar 添加到 solr 工程的 lib 目录下
cd /usr/local/solr/IKAnalyzer/
cp IKAnalyzer2012FF_u1.jar /usr/local/solr/tomcat/webapps/solr/WEB-INF/lib/
8.2、创建WEB-INF/classes文件夹
cd /usr/local/solr/tomcat/webapps/solr/WEB-INF/
mkdir classes
8.3、把扩展词典、停用词词典、配置文件放到 solr 工程的 WEB-INF/classes 目录下
cd /usr/local/solr/tomcat/webapps/solr/WEB-INF/classes
cp /usr/local/solr/IKAnalyzer/IKAnalyzer.cfg.xml ./
cp /usr/local/solr/IKAnalyzer/ext_stopword.dic ./
mv ext_stopword.dic stopword.dic
8.4、修改IKAnalyzer.cfg.xml配置文件

http://blog.csdnimg.cn/20200808150618399.png)
stopword.dic已经有了,ext.dic还没有
创建ext.dic:touch ext.dic
stopword.dic-停止词典
切分词的时候, 凡是出现在停止词典中的词都会被过滤掉.
ext.dic-扩展词典
凡是专有名词都会放到这里, 如果自然语义中不是一个词, 放到这里后solr
切分词的时候就会切分成一个词.
8.5、配置分词器
修改 Solrhome 的 schema.xml 文件
cd /usr/local/solr/solrhome/collection1/conf
vim schema.xml
在最后添加
<fieldType name="text_ik" class="solr.TextField">
<analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>自定义域名使用自己创建的分词器
<field name="content_ik" type="text_ik" indexed="true" stored="true"/>

9、测试:
配置完毕后重启tomcat
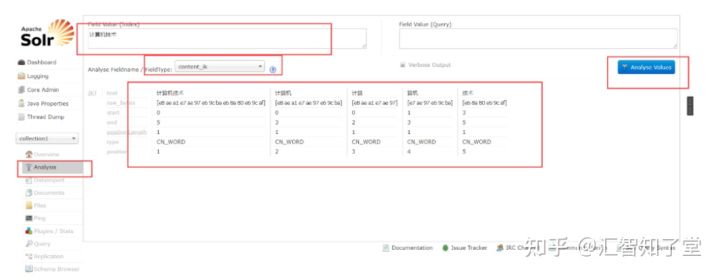
测试成功!















 6968
6968











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









