






class Embeddings(nn.Module):
def init(self, d_model, vocab):
“”“类的初始化函数, 有两个参数, d_model: 指词嵌入的维度, vocab: 指词表的大小.”“”
# 接着就是使用super的方式指明继承nn.Module的初始化函数, 我们自己实现的所有层都会这样去写.
super(Embeddings, self).init()
# 之后就是调用nn中的预定义层Embedding, 获得一个词嵌入对象self.lut
self.lut = nn.Embedding(vocab, d_model)
# 最后就是将d_model传入类中
self.d_model = d_model
super(Embeddings, self).init()
#使用super的方式指明继承Embeddings父类(nn.Module)的初始化函数
也就是继承nn.module的init函数
- input = t.arange(0, 6).view(3, 2).long() # 3个句子,每句子有2个词
input = t.autograd.Variable(input)
class torch.autograd.Variable:为什么要引入Variable?首先回答为什么引入Tensor。仅仅使用numpy也可以实现前向反向传播,但numpy不支持GPU运算。而Pytorch的Tensor提供多种操作运算,此外Tensor支持GPU。问来了,两三个网络可以推公式写反向传播,当网络很复杂的时需要自动化。autograd可以帮助我们,当利用autograd时,前向传播会定义一个计算图,图中的节点就是Tensor。图中的变就是函数。当我们将Tensor塞(Variable(tensor,…))到Variable时,Variable就变成了节点。若x为一个Variable,那么x.data即为Tensor,x.grad也为一个Variable。那么x.grad.data就为梯度的值。总结:Pytorch Variable与Pytorch Tensor有着相同的API,Tensor上的所有操作几乎都可用在Variable上。两者不同之处在于利用Variable定义一个计算图,可以实现自动求导。
总之更有利于求导和反向传播
3.>>> embedding = nn.Embedding(10, 3) #代表建立一个可以将10个字,转化为10个3维的向量
input = torch.LongTensor([[1,2,4,5],[4,3,2,9]]) # 两行代表2个句子,四列代表每个句子有4个词
embedding(input)
tensor([[[-0.0251, -1.6902, 0.7172],#1 每行代表每个字 列代表1 的一二三 维
[-0.6431, 0.0748, 0.6969],#2
[ 1.4970, 1.3448, -0.9685],#4
[-0.3677, -2.7265, -0.1685]],#5
[[ 1.4970, 1.3448, -0.9685],#4
[ 0.4362, -0.4004, 0.9400],#3
[-0.6431, 0.0748, 0.6969],#2
[ 0.9124, -2.3616, 1.1151]]])#9
([[1,2,4,5],[4,3,2,9]])
4.向量与矩阵的区别
创建一个向量
import numpy as np
#创建一个行向量
vector_row = np.array([1,2,3])
#创建一个列向量
vector_column = np.array([[1],[2],[3]])
print(vector_row)
print(vector_column)
out:
[1 2 3]
[[1]
[2]
[3]]
创建一个矩阵
import numpy as np
#创建一个矩阵
matrix = np.array([[1,2],[1,2],[1,2]])
print(matrix)
out:
array([[1, 2],
[1, 2],
[1, 2]])
可以看出向量和矩阵都是用数组array组成
区别在于向量是二维行或列向量
[[1]
[2]
[3]]
矩阵是二维行和列向量
array([[1, 2],
[1, 2],
[1, 2]])
都可以用np.array表示
列表list不可以进行数学四则运算,数组array可以进行数学四则运算;
lis1=[1,2,3,4] #lis1是列表类型
a = np.array([1,2,3,4]) #a是数组类型
二阶n维张量可以理解为n ∗ n 的矩阵,就像n维向量可以理解为n ∗ 1的矩阵一样
列向量就是只有一列的矩阵,可以用来表示向量
7.
tensor 与array数组的区别(基本一致只不过用于神经网络需要用tensor)
可以简单理解为,tensor可以用于神经网络
张量是就是神经网络里的数组,叫它张量而不是数组是因为它有自己的特质,它是神经网络计算的基本单元,tensor可以轻易地进行卷积,激活,上下采样,微分求导等操作,而numpy数组就不行,普通的数组要先转化为tensor格式才行。
8.
向量和矩阵都是二维数组 特点:两个方括号’[]’
b = np.random.randn(1,5) #1行5列的行向量
print(b)
[[ 0.16572125 0.61840102 -0.06370723 -0.56107341 1.04560651]]
n维向量可以理解为n ∗ 1的矩阵,1行5列的行向量理解为1 ∗ 5的矩阵
[[[1]]]即使有三个括号依旧是标量
9.
x = np.array([[[12]]])
b = np.arange(1,5)
print(b)
print(x*b)
[1 2 3 4]
[[[12 24 36 48]]]
Process finished with exit code 0
总之大部分情况可以根据方括号数量判断,但是本质上讲与括号多少无关系
接着,我们获得一个batch_size的变量,他是query尺寸的第1个数字,代表有多少条样本.
batch_size = query.size(0)
query尺寸的第1个数字,代表有多少条样本.
意思是query(2x8x512) 则size(0)为 2
例子:

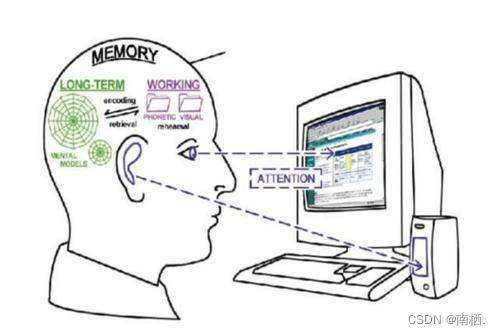
11.谈谈我对encoder的理解
就相当于人读书,然后理解后将其读的结果存到记忆里(memory)















 1263
1263











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









