







总的公式:
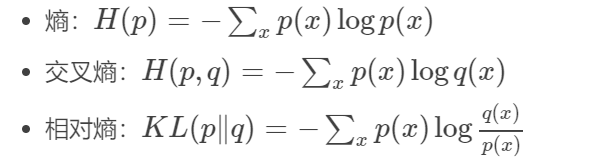
信息熵
信息熵是指一个概率分布p的平均信息量,代表着随机变量或系统的不确定性,熵越大,随机变量或系统的不确定性就越大。从编码的角度来看,信息熵是表示一个概率分布p需要的平均编码长度,其可表示为:
交叉熵
交叉熵是指在给定真实分布q情况下,采用一个猜测的分布p对其进行编码的平均编码长度(或用猜测的分布来编码真实分布得到的信息量)。交叉熵可以用来衡量真实数据分布于当前分布的相似性,当前分布与真实分布相等时(q=p),交叉熵达到最小值。其可定义为:
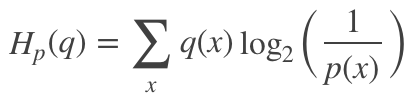
因此,在很多机器学习算法中都使用交叉熵作为损失函数,交叉熵越小,当前分布与真实分布越接近。此外,相比于均方误差,交叉熵具有以下两个优点:
- LR中,如果用均方误差损失函数,它是一个非凸函数,而使用交叉熵损失函数,它是一个凸函数;
- 在LR中使用sigmoid激活函数,如果使用均方误差损失函数,在对其求残差时,其表达式与激活函数的导数有关,而sigmoid的导数在输入值超出范围后将非常小,这会带来梯度消失问题,而使用交叉熵损失函数则能避免这个问题。
KL散度(又称相对熵)(上面两种熵的差值)
KL散度又称相对熵,是衡量两个分布之间的差异性。从编码的角度来看,KL散度可表示为采用猜测分布p得到的平均编码长度与采用真实分布q得到的平均编码长度多出的bit数,其数学表达式可定义为:
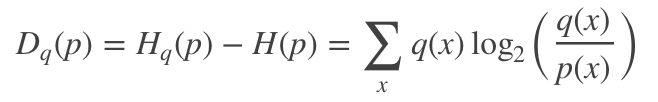
一般地,两个分布越接近,其KL散度越小,最小为0.它具有两个特性:
- 非负性,即KL散度最小值为0
- 非对称性,即Dq(p)不等于Dp(q) ;
求熵例子:
求投掷均匀正六面体骰子的熵
-
问题描述:向空中投掷硬币,落地后有两种可能的状态,一个是正面朝上,另一个是反面朝上,每个状态出现的概率为1/2。如投掷均匀的正六面体的骰子,则可能会出现的状态有6个,每一个状态出现的概率均为1/6。试通过计算来比较状态的不确定性与硬币状态的不确定性的大小。
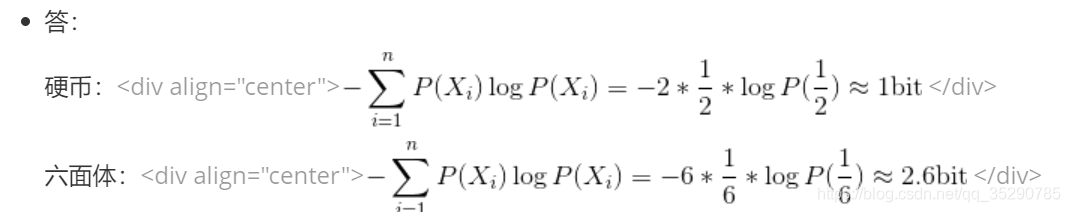
reference:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











