






数据库相关
JDBC
过程
1.加载数据库驱动
Class.forName(“com.mysql.jdbc.Driver”)
2.创建connection
conn=DriverManager.getConnection(“jdbc:mysql://localhost:3306/test?characterEncoding=utf-8”,“root”,“root”)
3.准备statement
预编译防止sql注入
prepareStatement=conn.prepareStatement(sql)
4.设置参数
prepareStatement.setString(“第几个问号”,“参数是什么”)
5.返回结果集
resultSet=prepareStatement.excuteQuery()
6.资源释放
resultSet.close()
缺点
频繁开关数据库连接,影响数据库的性能
存在数据库的硬编码和sql硬编码
Mybatis
是什么
是一个用来操作数据库的持久层框架,不需要关注加载数据库驱动等操作,只需关注sql本身,通过xml或者注解的方式将java对象和statement的sql映射成最终的sql,再将结果映射成java对象返回
原理
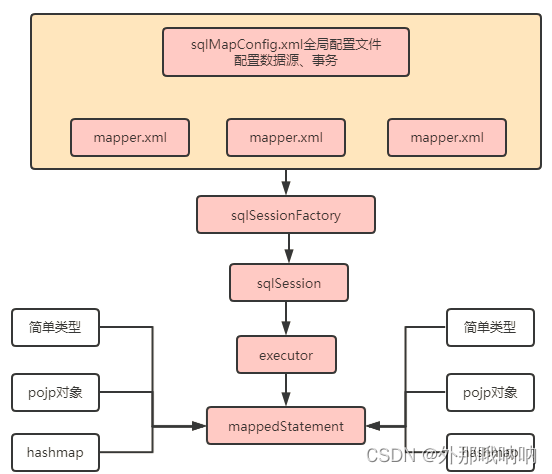
1.全局配置文件配置了数据源、事务mapper映射文件配置了sql相关操作
2.mybatis通过读取配置文件构造sqlsessionFactory
3.sqlSessionFactory创建sqlSession会话操作数据库
4.sqlsession会话不能直接操作数据库,通过executor执行器接口操作数据库,两个实现类普通执行器和缓存执行器(默认)
5.executor执行器执行的sql封装到mappedStatement对象中,包括sql、输入参数映射信息、输出结果集映射信息。输入输出的类型包括简单类型、pojo、hashMap
怎么用
1.jar
2.sqlMapperConfig.xml+Mapper.xml
3.InputStream in=Resource.getResourceAsStream(“sqlMapperConfig.xml”)
4.sqlSessionFactory sf=New SqlSessionFactoryBuilder().build(in)
SqlSessionFactoryBuilder创建工厂后销毁,生命周期在方法内
sqlSessionFactory需要创建sqlSession所以在应用范围内
sqlSession方法体内
5.sqlSession session=sf.openSession()
6.session.update(“test.updateUser”, user)
7.session.commit()
8.session.close()
主键返回的几种类型
主键返回之MySQL自增主键 LAST_INSERT_ID()
<!--
[selectKey标签]:通过select查询来生成主键
[keyProperty]:指定存放生成主键的属性
[resultType]:生成主键所对应的Java类型
[order]:指定该查询主键SQL语句的执行顺序,相对于insert语句
[last_insert_id]:MySQL的函数,要配合insert语句一起使用
-->
<insert id="insertUser" parameterType="User">
<selectKey keyProperty="id" resultType="int" order="AFTER">
SELECT LAST_INSERT_ID()
</selectKey>
INSERT INTO USER(...) VALUES (#{...})
</insert>
主键返回之MySQL函数UUID UUID()
<!--
[uuid]:生成的主键是35位的字符串,所以要修改id的类型为字符类型
1、此时order采用BEFORE,因为需要先生成出主键,再执行insert语句
2、显式的给ID赋值
-->
<insert id="insertUser" parameterType="User">
<selectKey keyProperty="id" resultType="string" order="BEFORE">
SELECT UUID()
</selectKey>
INSERT INTO USER(...) VALUES (#{...})
</insert>
主键返回之Oracle序列返回
SELECT user_seq.nextval() FROM dual
<insert id="insertUser" parameterType="User">
<selectKey keyProperty="id" resultType="int" order="BEFORE">
SELECT user_seq.nextval() FROM dual
</selectKey>
INSERT INTO USER(...) VALUES (#{...})
</insert>
#{}和${}的区别
#{} 这种取值是编译好SQL语句再取值,相当于预处理中的占位符?
select * from student where student_name = #{name}
预编译后,会动态解析成一个参数标记符?:
select * from student where student_name = ?
#{}可以防止SQL注入。
${} 这种是取值以后再去编译SQL语句,相当于拼接SQL串,对传入的值不做任何解释的原样输出。
select * from student where student_name = ${}
在动态解析时候,会传入参数字符串
select * from student where student_name = lyrics
不加引号所以会出现sql注入风险
传入‘user’; delete user;
一般用于传入数据库对象,例如传入表名.
当接受简单类型的参数时,
只能是
v
a
l
u
e
,
{}只能是value,
只能是value,{value}
select * from user where username like '%${value}%
select * from user where username like ‘%王%’
自定义别名
<typeAliases>
<!-- 单个定义别名 -->
<typeAlias type="cn.yaorange.mybatis.po.User" alias="user"/>
<!-- 批量定义别名(推荐) -->
<!-- [name]:指定批量定义别名的类包,别名为类名(首字母大小写都可)
<package name="cn.yaorange.mybatis.po"/>
</typeAliases>
resource/url/class
使用相对于类路径的资源 resource
如:<mapper resource="sqlmap/User.xml" />
使用完全限定路径 url
如:<mapper url="file:///D:\workspace_spingmvc\mybatis_01\config\sqlmap\User.xml" />
使用mapper接口的全限定名 class
如:<mapper class="cn.yaorange.mybatis.mapper.UserMapper"/>
表字段与实体类名称不同时
<resultMap type="最终映射的pojo对象" id="userResultMap">
<id column="表字段名称" property="pojo对象属性名"/>
<result column="..." property="..."/>
</resultMap>
<select id="接口方法名" parameterType="参数类型" resultMap="上面定义的resultMap的id" 如果返回相同则是resultType=“实体的别名”
关系映射配置resultMap
one To one(Person-Card) association +javatype
<resultMap type="domain.Person" id="OrdersUserRstMap">
<id column="id" property="id" />
<result column="user_id" property="userId" />
<association property="card-Person对象的Card属性名称" javaType="domain.Card">
<id column="user_id" property="id" />
</association>
</resultMap>
one To many(Student-Classes) collection +ofType
<resultMap type="domain.Classes" id="resultClasses">
<collection property="stus" ofType="domain.Student">
<id column="stu_id" property="id" />
<result column="items_id" property="itemsId" />
</collection>
</resultMap>
Many To Many(Student-Course) collection+ofType
<resultMap type="domain.Student" id="resultClass">
<id ... />
<result.../>
<collection property="course" ofType="domain.Course">
<id column="id" property="id" />
</collection>
</resultMap>
特殊标签比对
resultType:
作用:
将查询结果按照sql列名pojo属性名一致性映射到pojo中。
resultMap:
使用association和collection完成一对一和一对多高级映射(对结果有特殊的映射要求)。
association:
作用:
将关联查询信息映射到一个pojo对象中。
collection:
作用:
将关联查询信息映射到一个list集合中。
javatype:
和association一起使用,指定的是映射对象的类型(例如一对一中domain.Card),
oftype:
和collection一起使用,指定的是映射到list集合属性中pojo的类型(List 中的domain.Student)
延迟加载
在mybatis中使用association和collection有延迟加载
在做关联查询是会先加载主信息,做需要关联信息再加载关联信息
默认是不开启
怎么开启 lazyLoadingEnabled
sqlMapperConfig.xml配置
<settings>
<setting name="lazyLoadingEnabled" value="true">
</settings>
使用association延迟加载
<resultMap type="pojo.Orders" id="OrdersUserLazyLoadingRstMap">
<id column="id" property="id" />
<result column="user_id" property="userId" />
<!-- select:指定延迟加载需要执行的statement的id(是根据user_id查询用户信息的statement)
我们使用UserMapper.xml中的findUserById完成根据用户ID(user_id)查询用户信息
如果findUserById不在本mapper中,前边需要加namespace-->
<!-- column:主信息表中需要关联查询的列,此处是user_id -->
<association property="user" select="mapper.UserMapper.findUserById" column="user_id"></association>
</resultMap>
查询缓存
一级缓存是SqlSession级别的缓存。默认支持一级缓存
sqlSession对象中有一个数据结构(HashMap)用于存储缓存数据。
原理
第一次查询用户id为1的用户信息,sqlsession查询没有则取数据库查询,有则直接拿出
如果添加、修改、删除了用户信息则清空sqlsessino避免脏读
二级缓存是mapper级别的缓存,多个SqlSession可共用同一个Mapper的sql语句
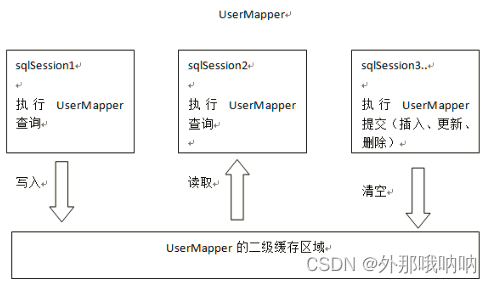
原理
第一次调用mapper下的SQL去查询用户信息。查询到的信息会存到该mapper对应的二级缓存区域内。
第二次调用相同mapper相同的SQL去查询会去对应的二级缓存内取结果
如果调用相同mapper中的增删改SQL,并执行了commit操作。此时会清空该二级缓存。
hibernate
是一个持久层的orm对象关系映射框架,用面向对象的思想来操作数据库
rom 对象、关系(表数据),映射xml配置文件
1、Configuration 接口:负责配置并启动 Hibernate
2、SessionFactory 接口:负责初始化 Hibernate
3、Session 接口:负责持久化对象的 CRUD 操作
4、Transaction 接口:负责事务
5、Query 接口和 Criteria 接口:负责执行各种数据库查询
Configuration 实例是一个启动期间的对象,一旦 SessionFactory 创建完成它就被丢弃了
怎么使用
1、配置数据源、方言等
2.new Configuration().configure(“hibernate.cfg.xml").buildSessionFactory().openSession()
增删改需要提交事务
session.beginTransaction()
session.commit()
session.close()
保存:session.save(对象)
删除 delete(obj)
修改对象 update(obj)
保存或者修改(如果没有数据,保存数据。如果有,修改数据)saveOrUpdate(obj)
通过id得到对象get(Class,id)
HQL 语句的查询的方式createQuery()
返回一行一列数据session.creatQuery().uniqueResult()
分页
query.setFirstResult(benginRow)
query.setMaxResults(pageSize)
query.list()
为什么使用
数据库操作简单,提升开发效率
缺点 表中关系复杂,表之间的关系很多不建议使用效率变慢
重点概念
持久化类 javabean+映射文件
类与表建立了映射关系就可以成为是持久化类
规则
1.必有构造函数()反射
2.唯一标识的主键
3.地址->对象 oid->记录
4.set,get(public)
5.基本数据的包装类(会有默认值)
主键
自然主键
主键本身是对象的一种属性,并且会用于业务当中。并非简单的标识作用,比如身份证
代理主键
不是对象本身的属性,是用来做标识而衍生出来的(常用)本身的存在与否不会影响到业务的执行
主键的生成策略
格式
<id name="id" column="id">
<generator class="....."/>
</id>
策略分类
自动生成:
-
适用于 char,varchar 类型的作为主键
uuid 随机的字符串作为主键
-
适用于 short,int,long 作为主键
1.increment
Hibernate 中提供的一种自动增长机制.先进行查询 :select max(id) from user;
再进行插入 :获得最大值+1 作为新的记录的主键.并发访问不可使用
2.identity
有自动增长数据库中,数据库提供的自动增长机制,Orcale没有自动递增,故无法使用
3.sequence
序列的增长方式。Oracle 数据库底层没有自动增长,想自动增长需要使用序列来实现自增
4.native自适应,根据不同的数据库选择不同的生成策略
底层使用的 MySQL 数据库=identity。
底层使用 Oracle 数据库= sequence。
手动生成:
assigned 主键的生成不用 Hibernate 管理了,也不用数据库管理.必须手动设置主键
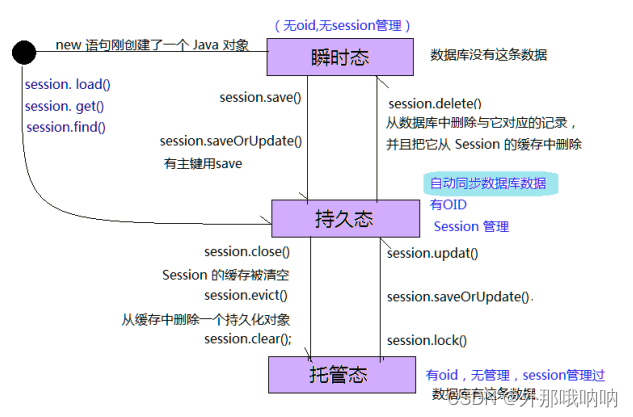
持久化对象的状态转换
瞬时状态:Transient Object 简称 TO
没有持久化标识 OID(手动方式除外)
没有被纳入到 Session 对象的管理
持久化状态:Persistent Object 简称 P0
自动同步数据库数据
有持久化标识 OID
已经被纳入到 Session 对象的管理(操作).
脱管状态:Detached Object 简称 DO
有持久化标识 OID
没有被纳入到 Session 对象的管理(已经被管理过,此时session已经关闭)
状态转换图:
hibernate缓存
一级缓存session
实现:map存放缓存数据,对象数组存放数据库拿出的对比数据
不同则更新
使用:
存入
get
load
saveOrUpdate
save
取用
get
load
清除
clear-- 清空缓存
close
evict -- 从一级缓存中清除指定的实体对象。
flush
等待提交(立即执行sql,提交后数据库才改变)
使用的原因
可以提升查询效率
二级缓存sessionFactory

sessionFactory级别缓存,用于跨session共享数据。
只对oid检索方式有效
查询缓存
基于二级缓存,将hql查询出来的数据存入二级缓存
hibernate.cfg.xml
use_query_cache
<property name="cache.use_query_cache">true</property>
session.createQuery().setCacheable(true).list()
事务
逻辑上的一组sql操作,要么全成功,要么全失败
特性
原子性:最小单位,不能被分割
一致性:前后数据要保持一致(A少了多少B就多了多少)
隔离性:事务执行途中不受其他事无干扰
持久性:从内存写到硬盘
不考虑隔离性:
读
1脏读:没有提交的数据被其他事务读取
2.不可重复读:读到已提交的UPDATE操作的事务,多次的读取结果不同
3.虚读:读到已提交的INSERT操作的事务,多次的读取结果不同
解决办法:设置隔离级别
配置文件:
hibernate.cfg.xml
connection.isolation
1—Read uncommitted isolation
2—Read committed isolation
4—Repeatable read isolation
8—Serializable isolation
例如:hibernate.connection.isolation = 4
1未提交读
2读已提交:解决脏读
4可重复读:解决脏读,不可重复读
8串行化
都可以解决
写
更新丢失
两个事务同时对某一条记录做修改
如果 A 事务修改完成后,提交了事务B 事务修改完成后,不管是提交还是回滚,如果不做处理,都会对数据产生影响
解决办法:锁机制
悲观锁:数据库锁机制,SQL 语句的后面for update
只有当 A 事务提交后,锁释放了,其他事务才能操作该条记录
乐观锁:hibernate锁机制 version
entity
private Integer version;
get set
hbm.xml
<version name="version"/>
谁先提交谁成功















 6724
6724











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









