






1.admin管控界面搭建
1.1 安装配置admin
下载安装包
https://github.com/alibaba/canal/releases/download/canal-1.1.4/canal.admin-1.1.4.tar.gz
解压安装包,进入conf目录

编辑application.yml
server:
port: 8089
spring:
jackson:
date-format: yyyy-MM-dd HH:mm:ss
time-zone: GMT+8
spring.datasource:
address: 10.1.2.27:3306
database: canal_manager
username: canal_manager
password: canal_manager
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://${spring.datasource.address}/${spring.datasource.database}?useUnicode=true&characterEncoding=UTF-8&useSSL=false
hikari:
maximum-pool-size: 30
minimum-idle: 1
canal:
adminUser: admin
adminPasswd: admin123
创建数据库:
通过 改目录下 canal_manager.sql ddl创建数据库以及表
配置密码: adminPasswd: admin123
踩坑: 一直以为 adminPasswd 是登陆密码,测试发现其实这是server注册到admin管控平台的密码
登陆密码默认是123456
1.2 启动
…/bin/startup.sh 就能启动管控平台
2.server高可用环境搭建
2.1 安装配置server
通过官方下载安装包
https://github.com/alibaba/canal/releases/download/canal-1.1.4/canal.deployer-1.1.4.tar.gz
解压安装包,进入conf目录
编辑canal_local.properties文件(基于admin管控平台),就只要注册到admin平台的简单配置,其他的配置听过管控页面配置,简单配置如下:
# register ip
canal.register.ip = 10.1.2.72
# canal admin config
canal.admin.manager = 10.1.2.72:8089
canal.admin.port = 11110
canal.admin.user = admin
#admin 配置的密码
canal.admin.passwd = 01A6717B58FF5C7EAFFF6CB7C96F7428EA65FE4C
# admin auto register
canal.admin.register.auto = true
#即在管控平台创建的集群名称
canal.admin.register.cluster =suppliper-cluster
注:上面密码的加密可以通过 mysql select password(‘admin配置的密码’) 来获取 如下图: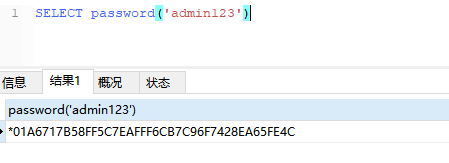
去掉结果中的*即可。
指定local配置文件启动
./bin/startup.sh local
进入另外一台机器重复上述步骤,那么集群环境中的两台server已经搭建。如下图:
2.2 配置server的基础配置
2.2.1 登陆admin管控平台

2.21 配置
集群环境中server的配置是共用的,必须通过上图中的操作按钮主配置来添加配置
#################################################
######### common argument #############
#################################################
#zoopeeper地址
canal.zkServers =10.1.2.72:2182,10.1.2.42:2181,10.1.2.46:2181
# flush data to zk 刷数据到zookeeper 中的时间间隔
canal.zookeeper.flush.period = 1000
canal.withoutNetty = false
# tcp, kafka, RocketMQ
#将数据推送至kafka
canal.serverMode = kafka
# flush meta cursor/parse position to file
canal.file.data.dir = ${canal.conf.dir}
canal.file.flush.period = 1000
## memory store RingBuffer size, should be Math.pow(2,n)
canal.instance.memory.buffer.size = 16384
## memory store RingBuffer used memory unit size , default 1kb
canal.instance.memory.buffer.memunit = 1024
## meory store gets mode used MEMSIZE or ITEMSIZE
canal.instance.memory.batch.mode = MEMSIZE
canal.instance.memory.rawEntry = true
## detecing config
canal.instance.detecting.enable = false
#canal.instance.detecting.sql = insert into retl.xdual values(1,now()) on duplicate key update x=now()
canal.instance.detecting.sql = select 1
canal.instance.detecting.interval.time = 3
canal.instance.detecting.retry.threshold = 3
canal.instance.detecting.heartbeatHaEnable = false
# support maximum transaction size, more than the size of the transaction will be cut into multiple transactions delivery
canal.instance.transaction.size = 1024
# mysql fallback connected to new master should fallback times
canal.instance.fallbackIntervalInSeconds = 60
# network config
canal.instance.network.receiveBufferSize = 16384
canal.instance.network.sendBufferSize = 16384
canal.instance.network.soTimeout = 30
# binlog filter config
canal.instance.filter.druid.ddl = true
canal.instance.filter.query.dcl = false
canal.instance.filter.query.dml = false
canal.instance.filter.query.ddl = false
canal.instance.filter.table.error = false
canal.instance.filter.rows = false
canal.instance.filter.transaction.entry = false
# binlog format/image check
canal.instance.binlog.format = ROW,STATEMENT,MIXED
canal.instance.binlog.image = FULL,MINIMAL,NOBLOB
# binlog ddl isolation
canal.instance.get.ddl.isolation = false
# parallel parser config
canal.instance.parser.parallel = true
## concurrent thread number, default 60% available processors, suggest not to exceed Runtime.getRuntime().availableProcessors()
#canal.instance.parser.parallelThreadSize = 16
## disruptor ringbuffer size, must be power of 2
canal.instance.parser.parallelBufferSize = 256
# table meta tsdb info
canal.instance.tsdb.enable = true
canal.instance.tsdb.dir = ${canal.file.data.dir:../conf}/${canal.instance.destination:}
canal.instance.tsdb.url = jdbc:mysql://10.1.2.27:3306/canal_tsdb
canal.instance.tsdb.dbUsername = canal_tsdb
canal.instance.tsdb.dbPassword = canal_tsdb
# dump snapshot interval, default 24 hour
canal.instance.tsdb.snapshot.interval = 24
# purge snapshot expire , default 360 hour(15 days)
canal.instance.tsdb.snapshot.expire = 360
# aliyun ak/sk , support rds/mq
canal.aliyun.accessKey =
canal.aliyun.secretKey =
#################################################
######### destinations #############
#################################################
canal.destinations = node-1
# conf root dir
canal.conf.dir = ../conf
# auto scan instance dir add/remove and start/stop instance
canal.auto.scan = true
canal.auto.scan.interval = 5
#canal.instance.tsdb.spring.xml = classpath:spring/tsdb/h2-tsdb.xml
canal.instance.tsdb.spring.xml = classpath:spring/tsdb/mysql-tsdb.xml
canal.instance.global.mode = spring
canal.instance.global.lazy = false
canal.instance.global.manager.address = ${canal.admin.manager}
#canal.instance.global.spring.xml = classpath:spring/memory-instance.xml
#canal.instance.global.spring.xml = classpath:spring/file-instance.xml
canal.instance.global.spring.xml = classpath:spring/default-instance.xml
##################################################
######### MQ #############
##################################################
canal.mq.servers = 10.1.2.72:9092
canal.mq.retries = 0
canal.mq.batchSize = 16384
canal.mq.maxRequestSize = 1048576
canal.mq.lingerMs = 100
canal.mq.bufferMemory = 33554432
canal.mq.canalBatchSize = 50
canal.mq.canalGetTimeout = 100
canal.mq.flatMessage = true
canal.mq.compressionType = none
canal.mq.acks = all
#canal.mq.properties. =
canal.mq.producerGroup = sc-cg-datasync-group
# Set this value to "cloud", if you want open message trace feature in aliyun.
canal.mq.accessChannel = local
canal.mq.topic=sc-cg-datasync
# aliyun mq namespace
#canal.mq.namespace =
##################################################
######### Kafka Kerberos Info #############
##################################################
canal.mq.kafka.kerberos.enable = false
canal.mq.kafka.kerberos.krb5FilePath = "../conf/kerberos/krb5.conf"
canal.mq.kafka.kerberos.jaasFilePath = "../conf/kerberos/jaas.conf"
配置保存后,集群中的server 就可以共用这份配置。
踩坑1:当instance 发生server切换时,发现binlog位置又回到原始点,导致重复消费
原因:上述配置中 canal.instance.global.spring.xml 还是使用的默认的 classpath:spring/memory-instance.xml 这种配置适用于单机模式,在内存中保存binlog位置,若发生server切换时新server中内存存的还是旧的binlog位置,导致又重新消费
解决方法:将配置 改成 classpath:spring/default-instance.xml 这种方式会将数据刷到zookeeper,从而使数据在 server中共享
**
踩坑2 :同样是发生server切换时,如果有存在ddl语句时,可能会报错
**原因:配置中 **canal.instance.tsdb.url 默认是使用h2内存数据库,当server切换时,新server没有保存最新的表结构,导致解析可能会报错
**解决方法:**canal.instance.tsdb.url 该配置需要使用外置的mysql数据库如下图,使得同一集群中的server使用一份数据
3 instance环境搭建
instance就是通过模拟mysql的一个从库去接受主从复制,从而解析binlog而获得数据。
3.1 新建instance
instance 可以通过安装包配置文件配置启动,也可以通过admin管控平台创建,我使用是管控平台。如下图:

3.1.1 点击新建instance

输入名称,该名称需要和server中 canal.destinations = node-1 该配置保持一致,不然会导致server启动会创建一个默认的instance, 而此时新建的又是一个新的instance,导致资源浪费。
3.1.2 配置instance
在空白处添加配置如下:
#################################################
## mysql serverId , v1.0.26+ will autoGen
canal.instance.mysql.slaveId=10112
# enable gtid use true/false
canal.instance.gtidon=false
# position info
canal.instance.master.address=192.168.189.10:23306
canal.instance.master.journal.name=mysql-bin.000207
canal.instance.master.position=48940372
canal.instance.master.timestamp=
canal.instance.master.gtid=
# rds oss binlog
canal.instance.rds.accesskey=
canal.instance.rds.secretkey=
canal.instance.rds.instanceId=
# table meta tsdb info
canal.instance.tsdb.enable=true
#canal.instance.tsdb.url=jdbc:mysql://127.0.0.1:3306/canal_tsdb
#canal.instance.tsdb.dbUsername=canal
#canal.instance.tsdb.dbPassword=canal
#canal.instance.standby.address =
#canal.instance.standby.journal.name =
#canal.instance.standby.position =
#canal.instance.standby.timestamp =
#canal.instance.standby.gtid=
# username/password
canal.instance.dbUsername=canal
canal.instance.dbPassword=123456789
canal.instance.connectionCharset = UTF-8
# enable druid Decrypt database password
canal.instance.enableDruid=false
#canal.instance.pwdPublicKey=MFwwDQYJKoZIhvcNAQEBBQADSwAwSAJBALK4BUxdDltRRE5/zXpVEVPUgunvscYFtEip3pmLlhrWpacX7y7GCMo2/JM6LeHmiiNdH1FWgGCpUfircSwlWKUCAwEAAQ==
# table regex
#canal.instance.filter.regex=.*\\..*
canal.instance.filter.regex=canal\\..*,chungou_lives.cg_order,chungou_lives.cg_goods,chungou_lives.cg_suppliers,chungou_lives.cg_goods_images,chungou_lives.cg_goods_category,chungou_lives.cg_spec_goods_price,chungou_lives.cg_logistics_info,chungou_lives.cg_order_aftersale_apply,chungou_lives.cg_order_refund,chungou_lives.cg_batch_refund_log
# table black regex
canal.instance.filter.black.regex=
# table field filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2)
#canal.instance.filter.field=test1.t_product:id/subject/keywords,test2.t_company:id/name/contact/ch
# table field black filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2)
#canal.instance.filter.black.field=test1.t_product:subject/product_image,test2.t_company:id/name/contact/ch
# mq config
canal.mq.topic=sc-cg-datasync
# dynamic topic route by schema or table regex
canal.mq.dynamicTopic=sc-cg-datasync-order:chungou_lives.cg_order;sc-cg-datasync-goods-category:chungou_lives.cg_goods;sc-cg-datasync-goods-category:chungou_lives.cg_goods_images;sc-cg-datasync-goods-category:chungou_lives.cg_goods_category;sc-cg-datasync-goods-price:chungou_lives.cg_spec_goods_price;sc-cg-datasync-after-sale-apply:chungou_lives.cg_order_aftersale_apply;sc-cg-datasync-batch-refund-log:chungou_lives.cg_batch_refund_log;sc-cg-datasync-order-refund:chungou_lives.cg_order_refund
canal.mq.partition=4
# hash partition config
canal.mq.partitionsNum=4
canal.mq.partitionHash=chungou_lives.cg_order:order_id,chungou_lives.cg_spec_goods_price:item_id
#################################################
配置内容:
1.配置主库的信息,选择binlog文件以及位置(还可以选择binlog的时间戳)
2.配置需要拦截的表
3.配置动态topic 即 可以通过不通的表分发到不通的topic
4.topic动态分区 即 可以针对订单表中基于订单编号或者id hash 操作到对应的位置的分区,保证同一订单只发送到某一个分区上(消费顺序性)
点击保存后 instance就能启动,如下:
启动成功,能看到属于集群中的哪个server.
3.1.3 instance日志查看
点击instance操作中的日志 如下图:
instance正在正常的读取binlog数据。
3.2 instance基于server切换演示

此时可以看到instance属于 10.1.2.72 这台主机中的server,打开server菜单,将该server停止

可以发现instance 已经自动发生了server切换,继续正常提供服务

4.zookeeper 高可用搭建
下载安装包
1.创建3个节点
2,在每个节点的主目录下创建data和logs两个目录用于存储数据和日志:
mkdir data
mkdir logs
3,在每个节点的conf目录下新建zoo.cfg文件,写入以下内容保存:
tickTime=2000
dataDir= 上述创建的data目录
dataLogDir=上步创建的logs目录
clientPort=2181
4,在每个节点的data目录下 创建myid 文件,在文件中声明序号,不能重复(这步在集群环境中必须要)
myid文件配置(添加一个数字即可)
1
- 集群安装配置,每个节点添加如下配置
server.1=IP1:2888:3888
server.2=IP2:2888:3888
server.3=IP3:2888:3888
其中,ID被称为 Server ID,用来标识该机器在集群中的机器序号(在每台机器的 dataDir 目录下创建 myid 文件,文件内容即为该机器对应的 Server ID 数字)。host 为机器 IP,port1 用于指定 Follower 服务器与 Leader 服务器进行通信和数据同步的端口,port2用于进行 Leader 选举过程中的投票通信。
6.启动
进入bin目录,启动、停止、重启分和查看当前节点状态(包括集群中是何角色)别执行:
./zkServer.sh start
./zkServer.sh stop
./zkServer.sh restart
./zkServer.sh status
执行 ./zkServer.sh status

就能看到各个节点的状态,以及主从信息。
当主节点挂了之后还能重新选举新的主节点。
5 通过zokeeper查看canal信息
canal 在zookeeper中的存储结构 ```shell /** * 存储结构: * *
* /otter * canal * cluster * destinations * dest1 * running (EPHEMERAL) * cluster * client1 * running (EPHEMERAL) * cluster * filter * cursor * mark * 1 * 2 * 3 ** * @author zebin.xuzb @ 2012-6-21 * @version 1.0.0 */ ``` 即: ```java /otter/canal:canal的根目录 /otter/canal/cluster:整个canal server的集群列表 /otter/canal/destinations:destination的根目录 /otter/canal/destinations/dest1/running:服务端当前正在提供服务的running节点 /otter/canal/destinations/dest1/cluster:针对某个destination的工作集群列表 /otter/canal/destinations/dest1/client1/running:客户端当前正在读取的running节点 /otter/canal/destinations/dest1/client1/cluster:针对某个destination的客户端列表 /otter/canal/destinations/dest1/client1/cursor:客户端读取的position信息 ```
进入zookeeper 某个节点:
./zkCli.sh -server 127.0.0.1:2181
连接:
ls /otter/canal/cluster
就能看到canal的server 集群列表
查看提供服务的running节点:
get /otter/canal/destinations/node-1/running

















 266
266











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











