






1、在vmwa机、安装ubuntu、一些准备设置
创建虚拟机的时候虚拟机名称填master,
安装ubuntu时姓名和计算机名都填master,用户名填hadoop,
安装完后检查是否能直接拖动文件到虚拟机中,不能的话要安装vmware-tools,安装完后重启,然后将jdk-8u162-linux-x64.tar.gz和hadoop-3.1.3.tar.gz拖动到主目录下,
设置屏幕不自动熄屏
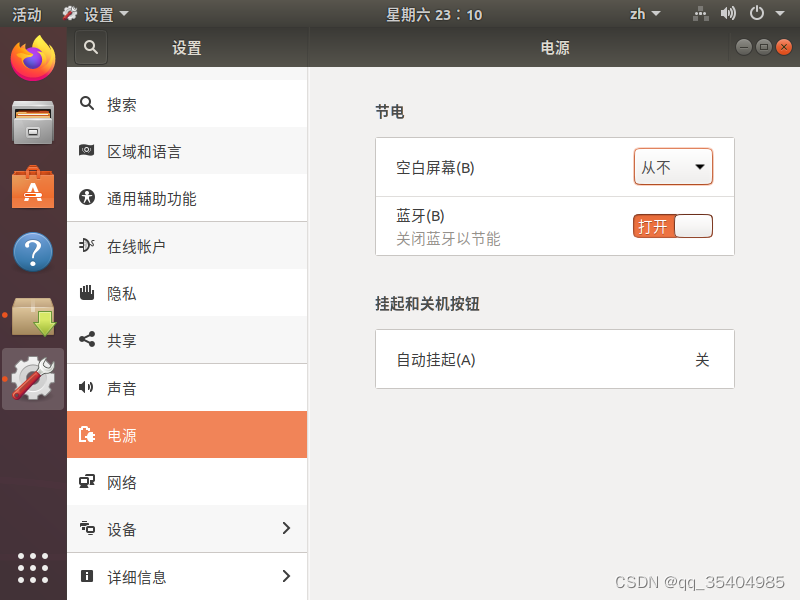
2、配置ip地址
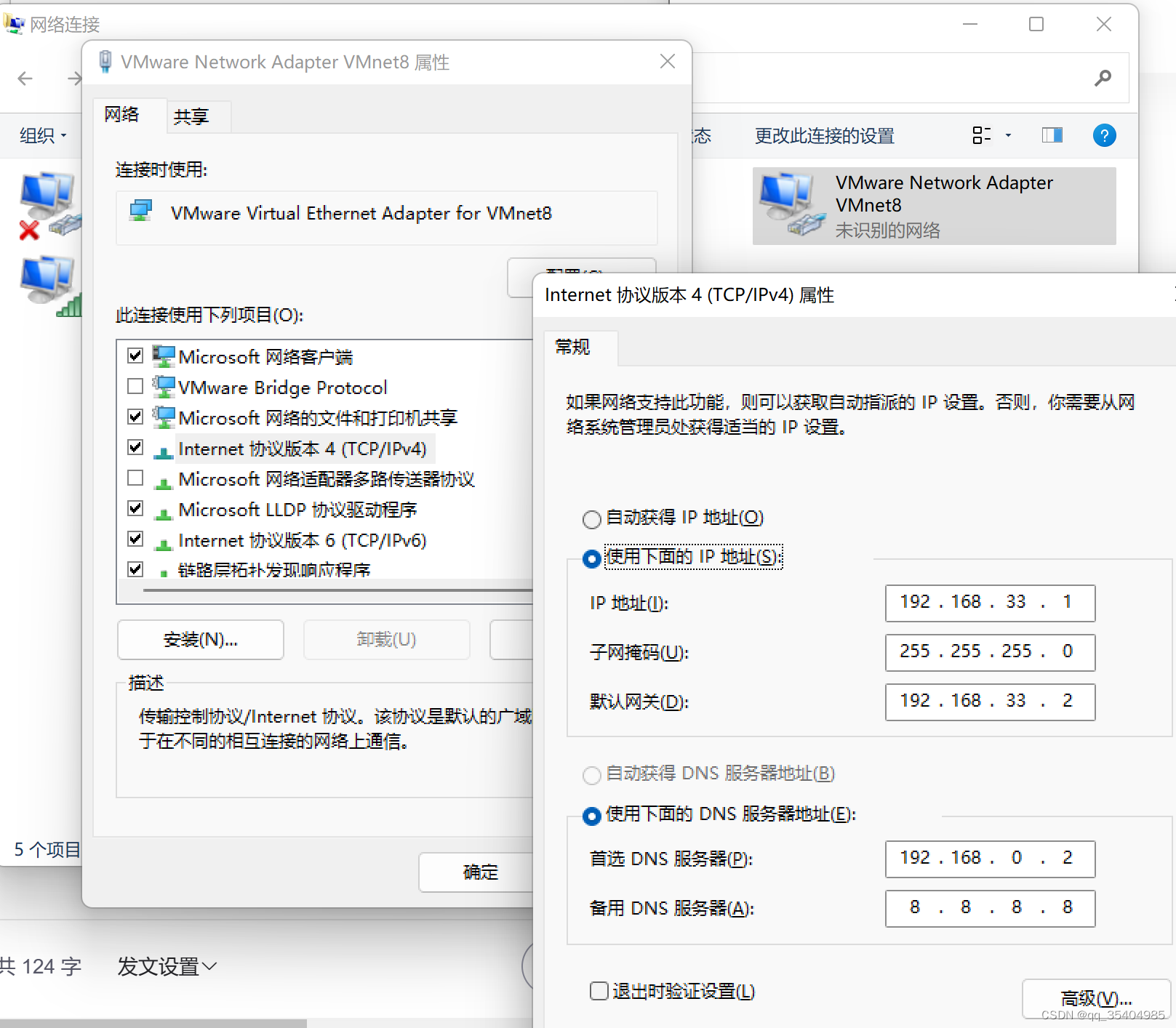
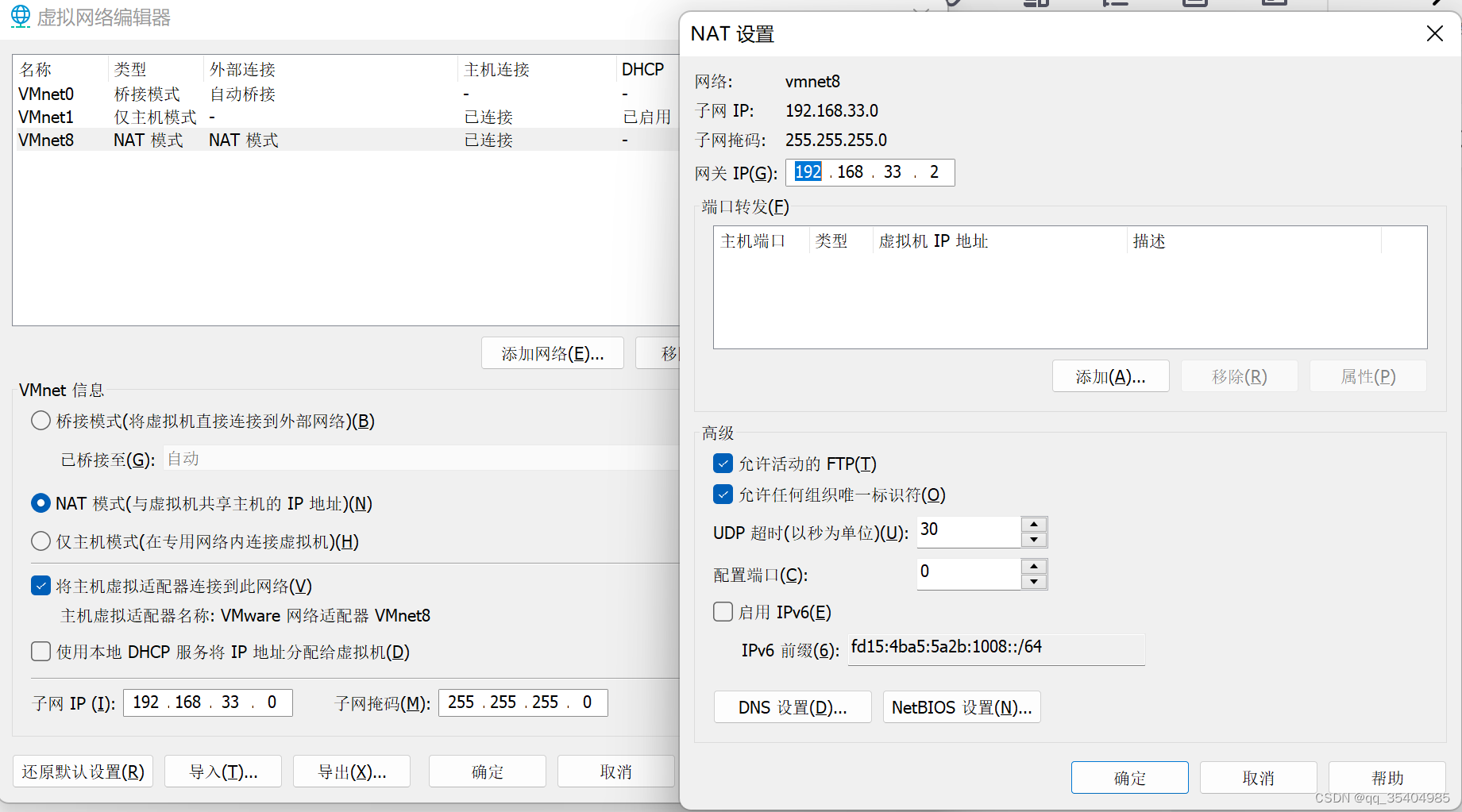
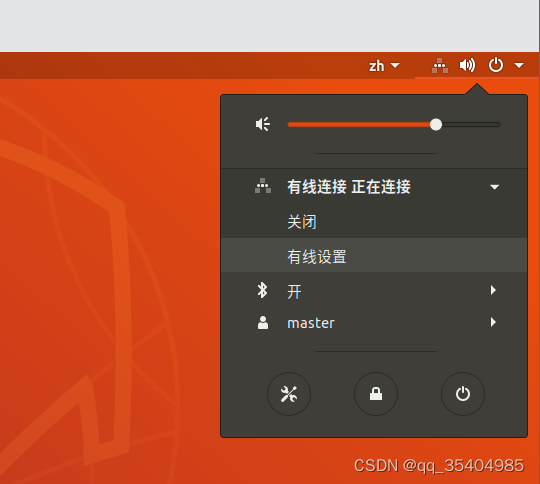
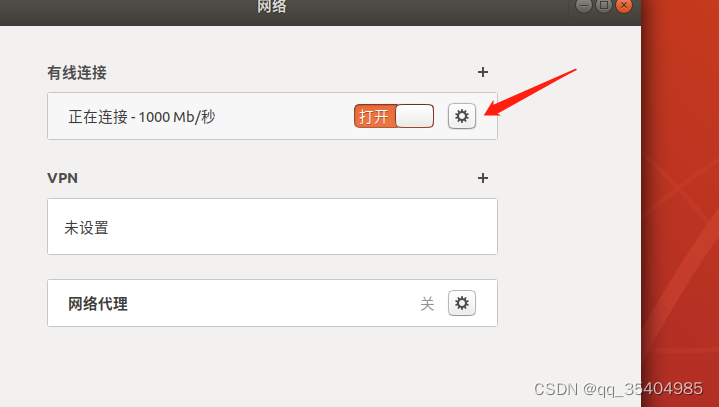

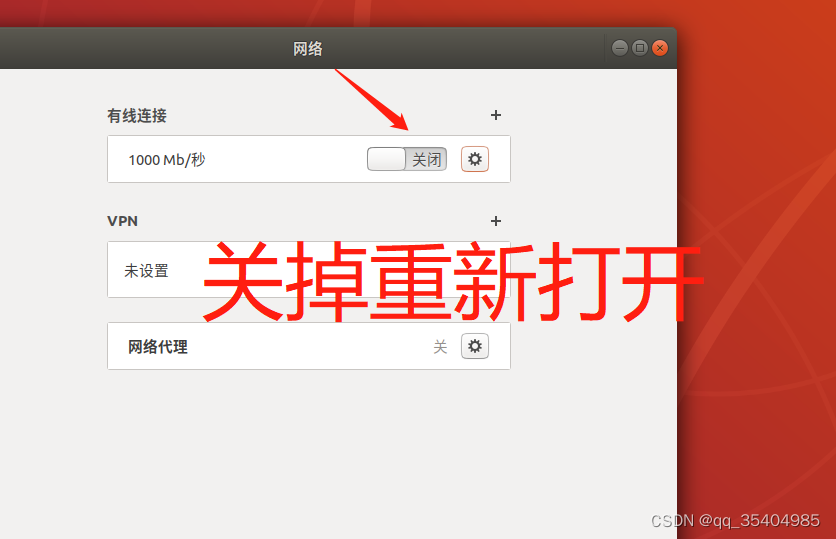
验证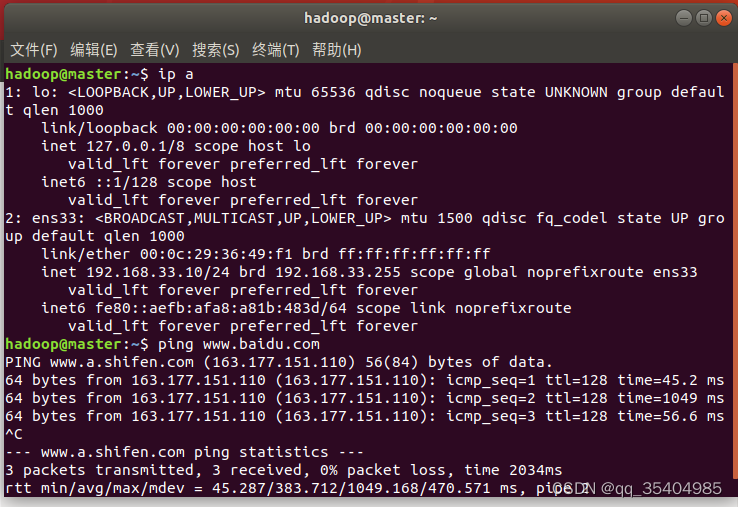
3、安装openssh-server、vim(习惯)
sudo apt-get update
sudo apt-get install openssh-server
sudo apt-get install vim4、安装java和hadoop
cd ~
sudo tar -zxvf jdk-8u162-linux-x64.tar.gz -C /usr/local/
sudo tar -zxvf hadoop-3.1.3.tar.gz -C /usr/local
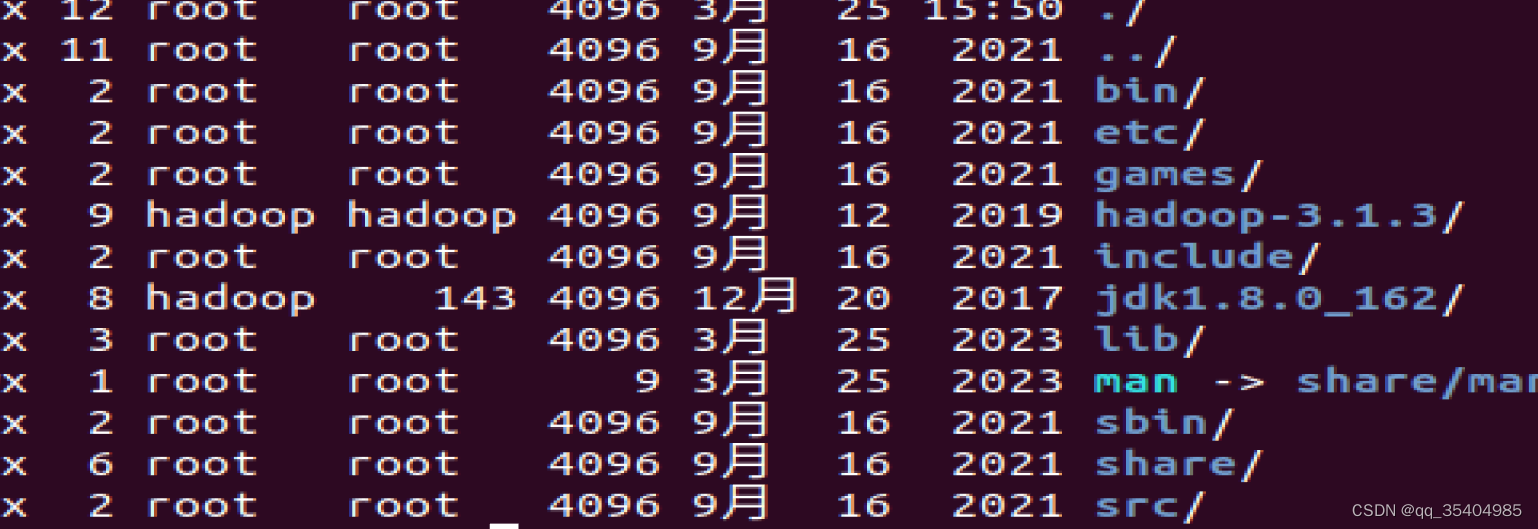
给这两个权限,归hadoop用户所有
cd /usr/local
sudo chown -R hadoop hadoop-3.1.3/
sudo chown -R hadoop jdk1.8.0_162用ll查看结果
配置环境变量
cd ~
vim .bashrc在.bashrc文件最下面添加
## java 环境变量
export JAVA_HOME=/usr/local/jdk1.8.0_162/
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
# hadoop 变量
export HADOOP_HOME=/usr/local/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin使生效
source .bashrc校验

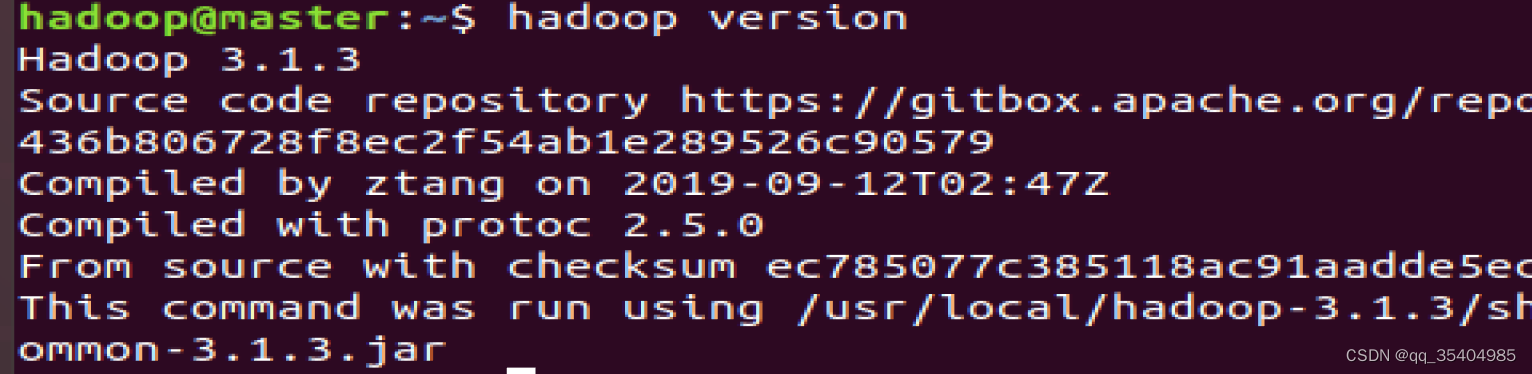
5、配置hadoop
cd /usr/local/hadoop-3.1.3/etc/hadoop/
vim core-site.xml
#添加到<configuration></configuration>中
<!-- 指定NameNode地址-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:8020</value>
</property>
<!-- 指定hadoop数据的存储目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop-3.1.3/data</value>
</property>
vim hdfs-site.xml
<!-- 指定NameNode web-->
<property>
<name>dfs.namenode.http-address</name>
<value>master:9870</value>
</property>
<!-- second name node web -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>slave2:9868</value>
</property>vim mapred-site.xml
<!-- 指定NameNode地址-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>vim yarn-site.xml
<!-- 指定 MR shuffle-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- ResourceManager addr-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>slave1</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_CONNON_HONE,HADOOP_HDFS_HONE,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADO0P_MAPRED_HOME</value>
</property>vim workers
master
slave1
slave2vim hadoop-env.sh
HADOOP_SECURE_DN_USER=root
HDFS_SECONDARYNAMENODE_USER=root
HDFS_NAMENODE_USER=root
HDFS_DATANODE_USER=root
HDFS_ZKFC_USER=root
HDFS_JOURNALNODE_USER=root
YARN_RESOURCEMANAGER_USER=root
YARN_NODEMANAGER_USER=root
JAVA_HOME=/usr/local/jdk1.8.0_162/
HADOOP_SHELL_EXECNAME=root6、修改hosts文件、关闭防火墙
sudo vim /etc/hosts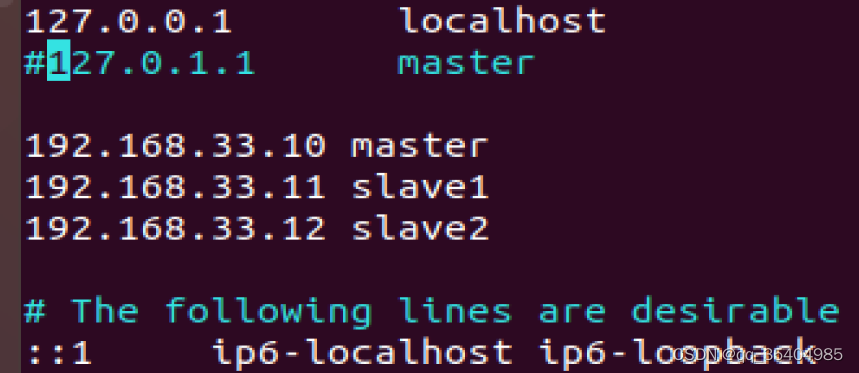
192.168.33.10 master
192.168.33.11 slave1
192.168.33.12 slave2# 关闭防火墙
systemctl stop firewalld.service
# 禁止开机启动
systemctl disable firewalld.service7、克隆虚拟机
先关闭虚拟机,右键虚拟机-管理-下一步-创建完整克隆-虚拟机名称slave1位置看着选
以同样方式克隆出slave2
克隆完后打开三台虚拟机
8、修改slave1、slave2的ip地址、hostname
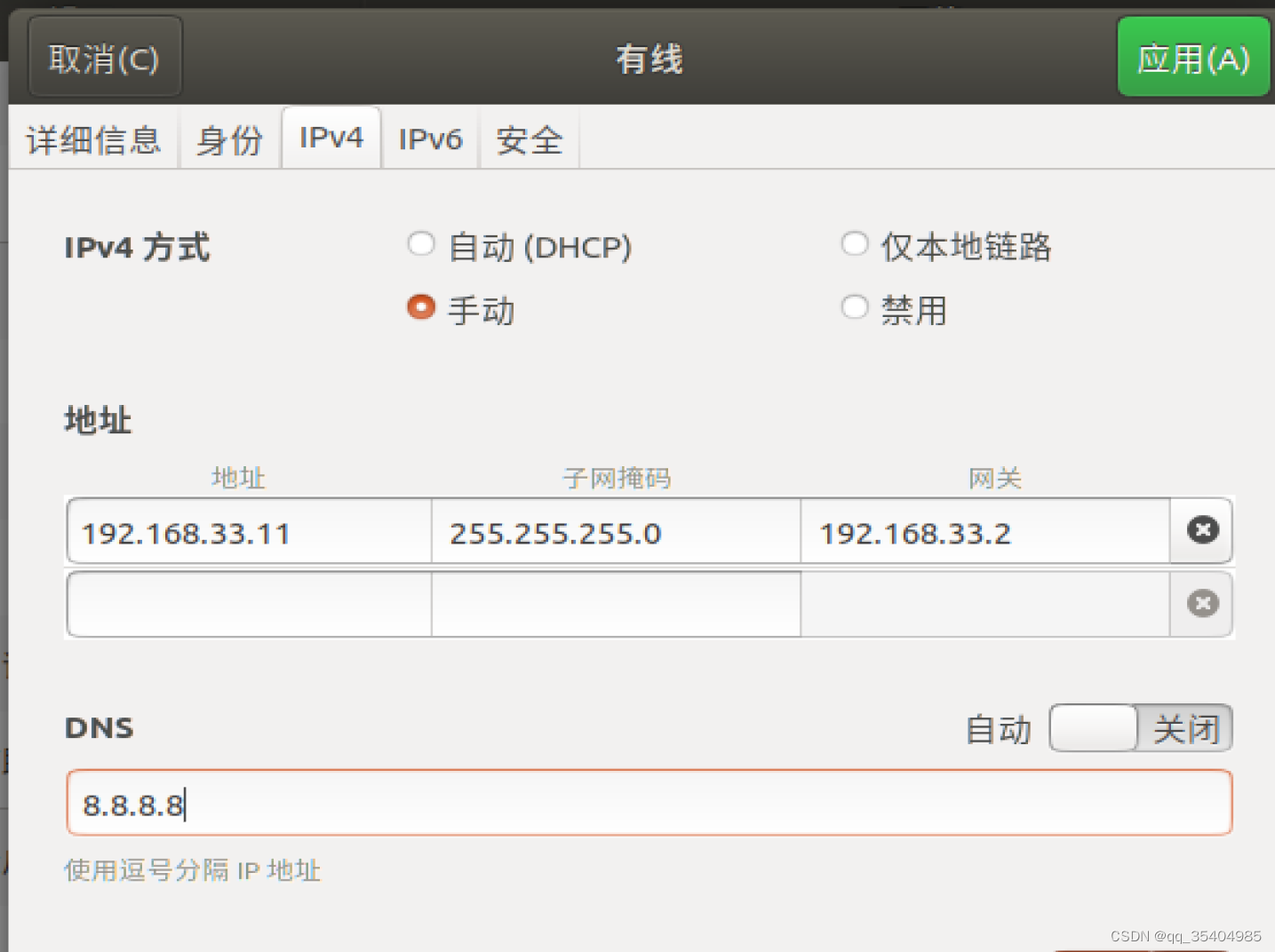
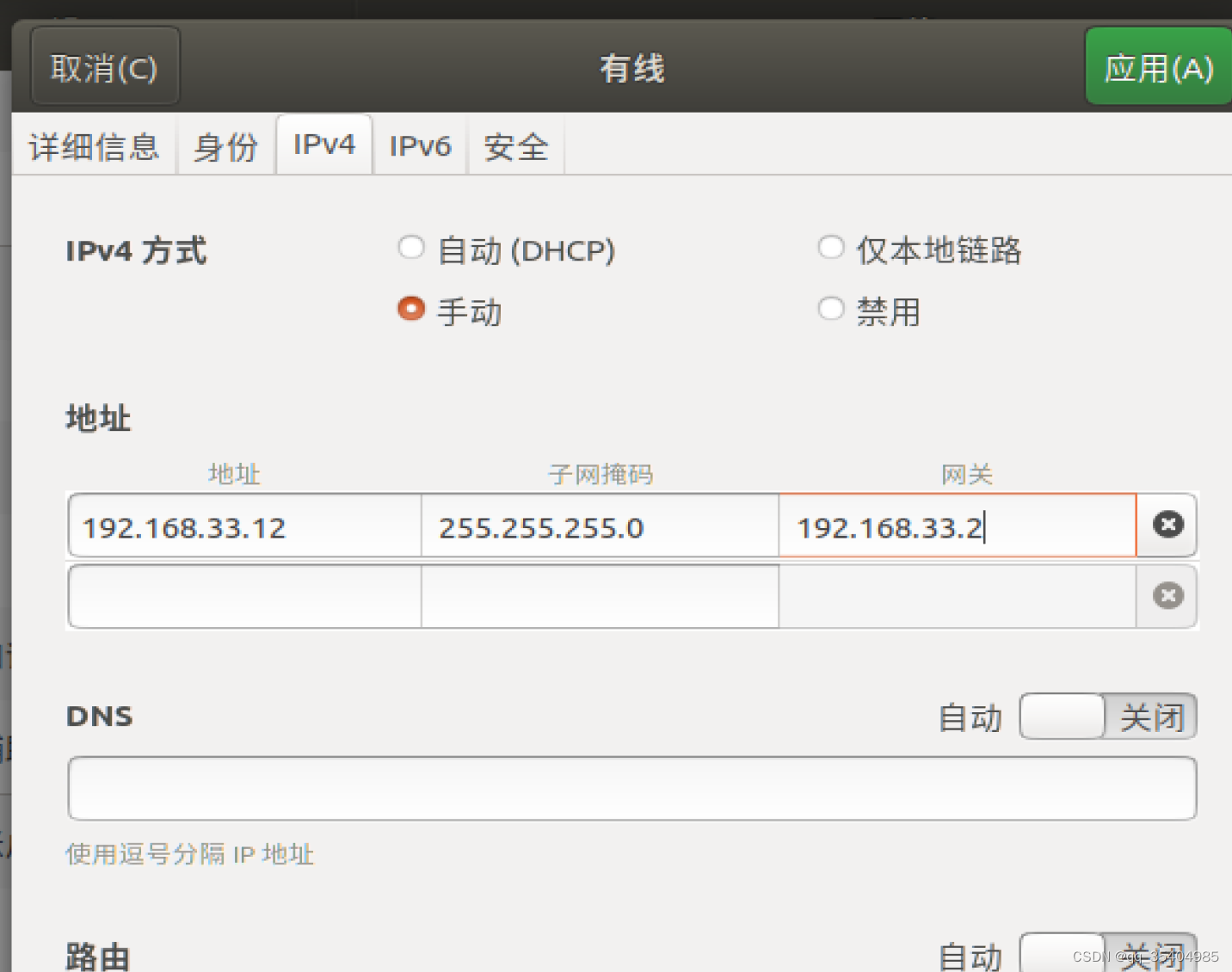
#在slave1中
hostnamectl set-hostname slave1
##重新使用hadoop登录
sudo login
#在slave2中
hostnamectl set-hostname slave2
sudo login
9、 配置ssh免密登录
分别在三台机器上生成 ssh 链接的私钥和公钥
ssh-keygen -t rsa#在master下
cd ~/.ssh
touch authorized_keys
cat id_rsa.pub >> authorized_keys
#在slave1下
scp ~/.ssh/id_rsa.pub hadoop@master:~/
#在master下
cd ~
cat id_rsa.pub >> .ssh/authorized_keys
#slave2
scp ~/.ssh/id_rsa.pub hadoop@master:~/
#master
cd ~
cat id_rsa.pub >> .ssh/authorized_keys
#最后查看一下追加的三段公钥,在master中:
cat .ssh/authorized_keys
#然后使用scp命令将master节点里的authorized_keys文件分别上传到slave1和slave2节点的.ssh/目录下,在master中:
scp /home/hadoop/.ssh/authorized_keys hadoop@slave1:~/.ssh/
scp /home/hadoop/.ssh/authorized_keys hadoop@slave2:~/.ssh/
#验证ssh免密登录,远程登录slave1命令,如果想登录其他节点,将slave1改成其他主机的主机名即可
ssh slave1
#退出命令
exit
10、启动集群
第一次启动初始化HDFS(在master上)
hdfs namenode -format
启动HDFS(在master上)
start-dfs.sh启动yarn(在hadoop1上)
start-yarn.sh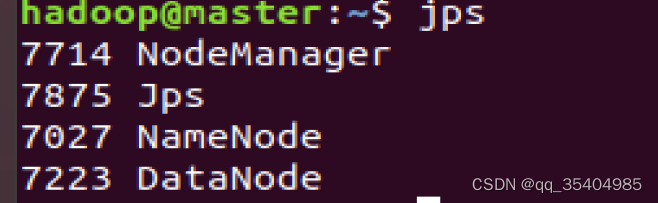
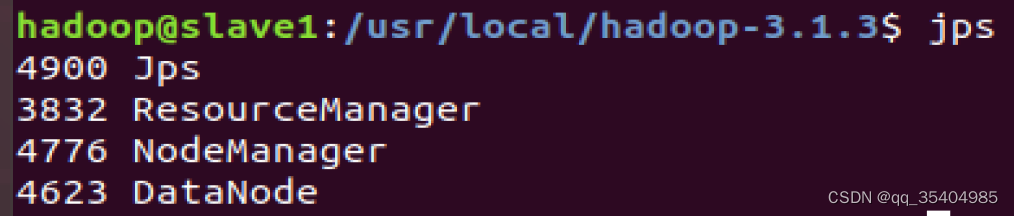

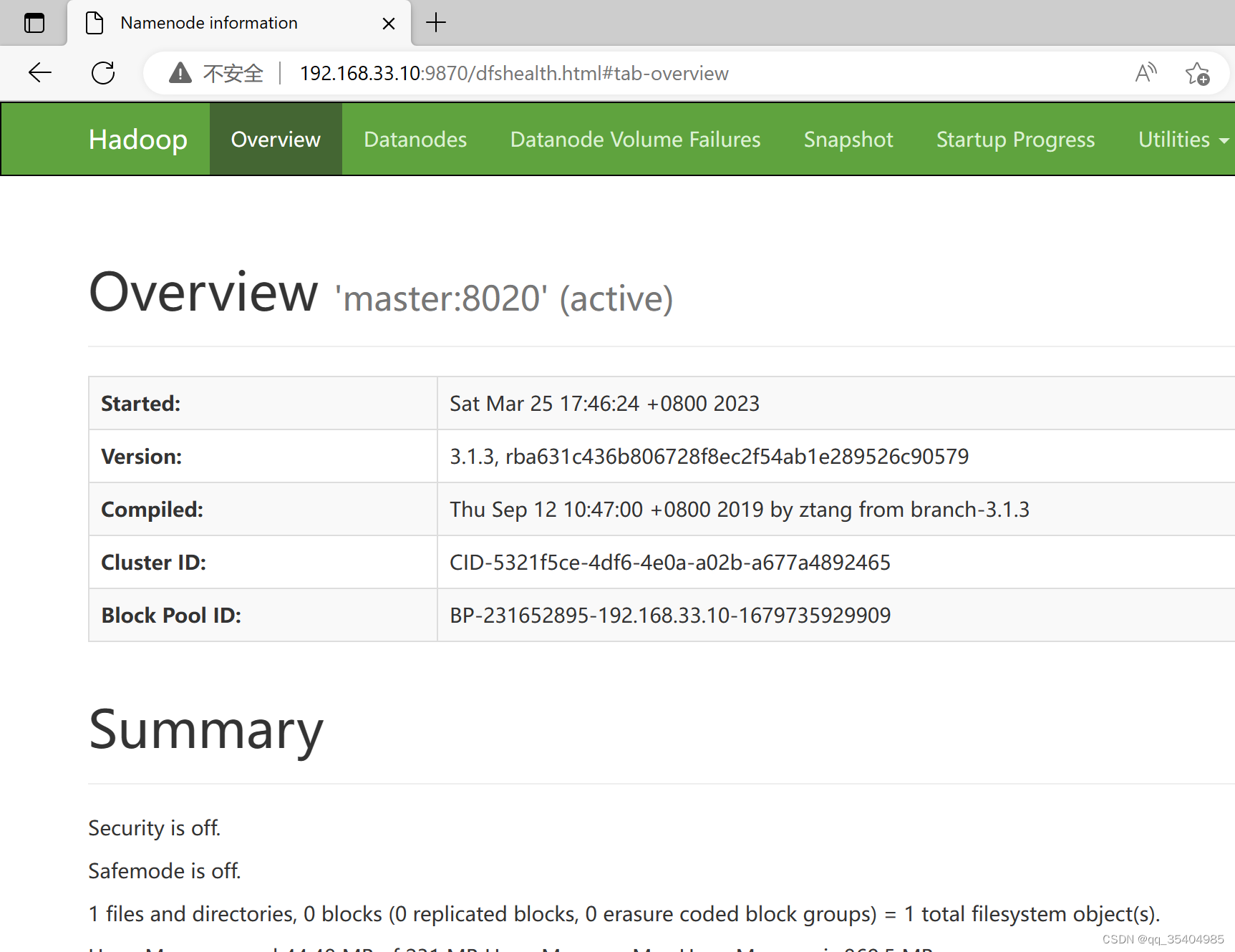
浏览器访问
停掉集群(在master上)
stop-all.sh参考:
hadoop-3.1.3 完全分布式集群搭建 - 知乎 (zhihu.com)
(60条消息) 超级无敌详细使用ubuntu搭建hadoop完全分布式集群_ubuntu搭建hadoop集群_普通网友的博客-CSDN博客















 547
547











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









