






 本文介绍了如何在Chrome浏览器中通过开启Preserve log选项来查看页面跳转后的网络请求日志。首先,创建一个带有跳转链接的简单HTML页面,然后使用Chrome打开并进入开发者工具的Network面板。默认情况下,跳转会导致日志清空,但启用Preserve log后,可以保持页面跳转前的网络请求记录。
本文介绍了如何在Chrome浏览器中通过开启Preserve log选项来查看页面跳转后的网络请求日志。首先,创建一个带有跳转链接的简单HTML页面,然后使用Chrome打开并进入开发者工具的Network面板。默认情况下,跳转会导致日志清空,但启用Preserve log后,可以保持页面跳转前的网络请求记录。
在Web开发中,在页面跳转后看上个页面的网络请求日志信息是一个常见的需求。本文所述只是Web开发过程中一个小小的技巧。如果不知道这个技巧,开发者往往通过其他方式达到类似的目的,例如:注释页面跳转逻辑,打印日志信息等等。不过,利用好谷歌Chrome浏览器这个开发小技巧可以大大提高效率。
准备工作
准备一个简单的html页面,页面上只有一个跳转到百度首页的a标签。用谷歌Chrome浏览器打开准备好的html页面。不要用苹果的Safari浏览器打开,它没有类似Preserve log的功能。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>页面跳转</title>
</head>
<body>
<div>
<a href="https://www.baidu.com">百度首页</a>
</div>
</body>
</html>
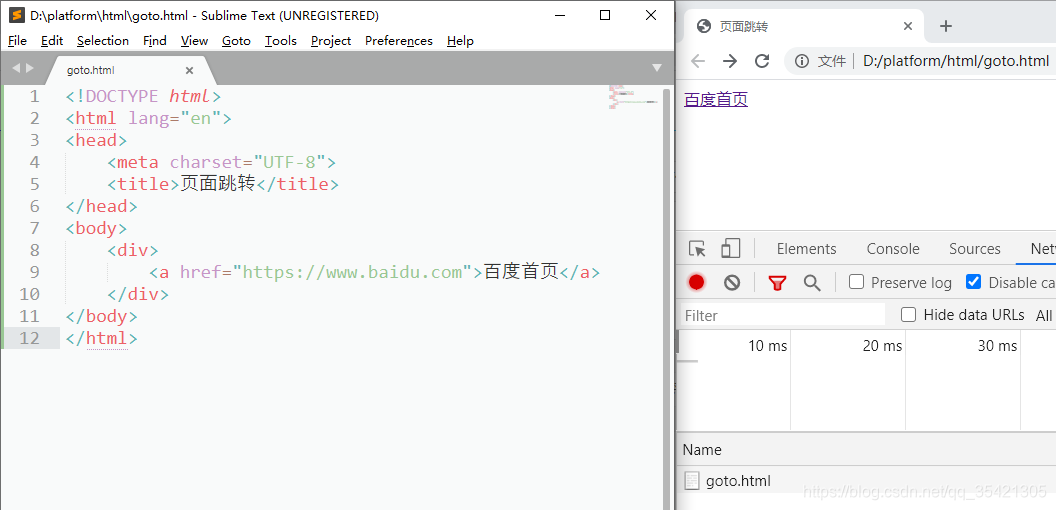
打开谷歌Chrome浏览器的Preserve log选项
注意:跳转到百度首页时,浏览器会请求html、js、css以及一些图片和字体等资源。为了方便演示,按F12打开开发者模式,在"Network"选项页,点击"Doc"选项,过滤掉其他东西,只显示请求html文件。
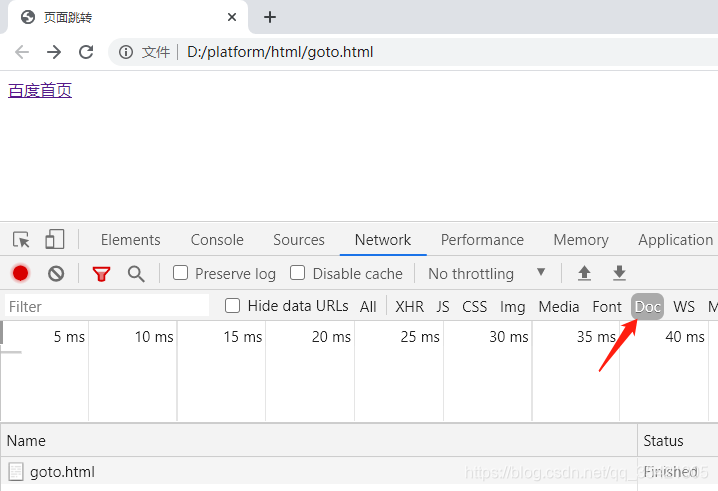
默认情况
点击上图的“百度首页”
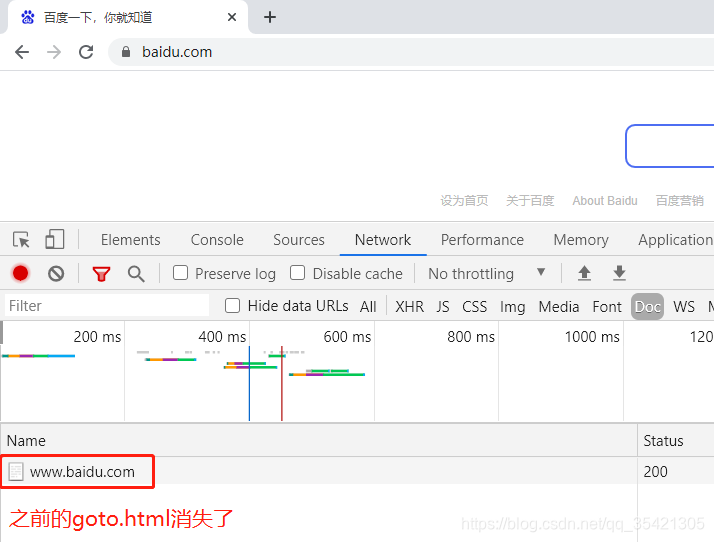
打开Preserve log选项后
打开Preserve log选项后,再点击之前准备的goto.html页面的“百度首页”,发现之前的goto.html继续保留,没有被删除。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











